Deephaven's design
We built Deephaven to be an incredible tool for working with tabular data — full stop. To us, tables are dynamic, powerful constructs, but we certainly care about static, batch ones too. In this piece, we explore some of the underlying technical and architectural decisions that, taken together, deliver Deephaven's value proposition.
This guide assumes familiarity with distributed systems, JVM architecture, and modern data platforms. For hands-on tutorials, see our how-to guides.
Deephaven's architecture is built on several key innovations:
- Unified DAG-based update model: Real-time and static data flow through the same directed acyclic graph with automatic dependency tracking and incremental updates.
- Shared table structures:
RowSetsandColumnSourcesenable zero-copy operations and efficient memory usage across query operations. - Mechanical sympathy: Chunk-oriented processing, columnar layouts, and careful JVM optimization deliver exceptional performance.
- Seamless language integration: Python, Java, and polyglot APIs work together through JPY and gRPC.
- Python-first UI framework:
deephaven.uienables building reactive web applications entirely in Python, with live table integration and no front-end engineering required. - Unified batch and streaming: Batch and real-time data coexist behind a single, consistent API — no separate systems or complex coordination required.
How Deephaven compares
| Capability | Traditional Approach | Deephaven |
|---|---|---|
| Batch + Real-time | Separate systems (e.g., Spark + Flink) | Unified table API for both |
| Update model | Recompute full datasets | Incremental (only changed rows) |
| Memory efficiency | Copy-on-write, data duplication | Shared RowSets and ColumnSources |
| Query consistency | Manual coordination required | Automatic via DAG and logical clock |
| UI development | Separate front-end team/codebase | Pure Python (deephaven.ui) or JS |
| Data movement | Row-at-a-time or full scans | Chunk-oriented (4096 cells at once) |
| Performance tuning | Complex configuration, multiple systems | Mechanical sympathy built-in |
This document provides technical depth on each component. For a conceptual introduction to DAGs, start with our DAG concept guide.
Table update model
Deephaven's real-time engine uses a directed acyclic graph (DAG) to propagate updates efficiently through query operations. This architecture provides significant advantages over traditional batch processing:
How the DAG works
Queries automatically form a DAG where:
- Vertices represent tables or data operations.
- Edges represent dependencies and data flow.
- Updates propagate incrementally - only changed data recomputes.
- Consistency: A logical clock coordinates update cycles.
For example, consider this simple query:
When source receives a new row, the DAG ensures that filtered and aggregated update automatically and consistently. The engine only recomputes what changed - if one row updates, only that row flows through the graph.
Performance impact: Incremental updates mean a 1-row change to a million-row table triggers recomputation of only that single row, not the entire dataset. In a typical financial trading scenario with 1,000 updates per second to a 10-million-row table, Deephaven processes 1,000 rows per second while a full-recompute system would need to process 10 billion rows per second to maintain the same latency.
Update graph (UG) cycles
The engine batches updates at a configurable interval (default 1000ms) and propagates them through the DAG in topological order. This batching:
- Improves efficiency: Process multiple changes together instead of one at a time.
- Ensures consistency: All tables see the same snapshot of changes.
- Reduces overhead: Minimizes per-update costs.
Cross-process DAGs
The DAG extends across threads and network boundaries, allowing distributed data-driven applications. Tables can be shared between processes using initial snapshots followed by incremental deltas, enabling truly parallel update propagation.
Deep dive
For comprehensive coverage of DAGs, UG cycles, garbage collection, custom listeners, and performance optimization, see our DAG concept guide and table update model.
Unified table API design
Many use cases require analyzing and commingling static and dynamic data. We don’t think users should have to use different tools or APIs for these two types of sources, for two reasons:
- Learning curve: Learning two APIs may take (at least) twice as long as one. Further, there is often nagging cognitive dissonance in trying to remember how the same operation is done in each.
- Ease of data integration: Merging or joining data accessible via different systems often requires using a third tool for data federation or implementing a custom tool. This is never seamless and sometimes requires intermediation.
At Deephaven, we have designed and implemented a unified table API that offers the same functionality and semantics for both static and dynamic data sources, albeit with additional correctness considerations in the dynamic case. Deephaven tables that incorporate real-time data update at a configurable frequency (usually 10-100 milliseconds), always presenting a correct, consistent view of data to downstream consumers in the update graph, as well as to external listeners and data extraction tools, whether in-process or remote.
Example: The same code works for both static and live data:
Unified batch and streaming
Traditional lambda architecture requires separate systems for batch and real-time data — a batch layer, a speed layer, and a serving layer — with complex coordination between them. Deephaven eliminates this complexity entirely. The same API handles both static and streaming data transparently, with no code changes required when switching between them.
One classic use case can be found in capital markets’ trading systems, with previous days’ historical data that can be treated as static managed separately from intraday data that is still growing and evolving. It’s often necessary to bootstrap models over historical datasets and then extrapolate with intraday data as it arrives. Another applicable example can be found in infrastructure monitoring systems that aggregate data hierarchically across many nodes; older data may be batch-processed and aggregated at coarse granularity, while fresh data may be in its most raw form for minimum latency.
In this regard, our Enterprise product institutionalizes this model for our customers, providing a complete suite of tools for publishing persistent, append-only, immutable data streams as tables and distributing this data widely to many query engines hosted within remote applications, along with tooling for data lifecycle management and data-driven application orchestration. Deephaven Enterprise explicitly allows for historical data to be post-processed, stored, and served in an appropriate form to maximize throughput for common queries, while allowing minimum latency for raw, real-time data, and integrates these within its own distributed data service layer.
Our community software empowers users with a comprehensive, extensible query engine that can interact with and commingle data accessed or ingested directly from disparate sources, including custom applications, Apache Parquet, Apache Kafka, Apache Orc, CSV, JSON, CDC, and in the future, Arrow, ODBC, and other contemplated integrations. Our table update model and unified table API design allow for seamless integration of data with different characteristics, thus allowing batch data and real-time data to coexist behind the same interface. Layering our gRPC API on top completes the picture, linking Deephaven query engines with one another or with client applications to construct data-driven applications.
This combination of capabilities allows Deephaven to replace the complexity of traditional lambda architecture with a single, unified system. This, in turn, allows for a better overall experience for end-users, as the data manipulation and access APIs are consistent and realize the full capabilities of all layers.
Tables designed for sharing and updating
Deephaven tables are implemented using data structures that lend themselves to efficient sharing and incremental updating. At its most basic, each table consists of two components:
- A
RowSetthat enumerates the possibly-sparse sequence of row keys (non-negative 64-bit integers) in the table. - A map associating names with
ColumnSourcesthat allow data retrieval for individual row keys, either element-by-element or in larger batches.
A ColumnSource represents a column of (possibly dynamically updating) data that may be shared by multiple tables.
A RowSet selects elements of that ColumnSource and might represent all the data in the ColumnSource or just some subset of it. A redirecting RowSet is a RowSet that is derived from another RowSet and which remaps its keys. It can be used, for example, to reorder the rows in a table effectively.
Example of sharing:
Filtering (where operations) creates a new RowSet that is a subset of an existing RowSet; sorting creates a redirecting RowSet.
A table may share its RowSet with any other table in its update graph that contains the same row keys. A single parent table is responsible for maintaining the RowSet on behalf of itself and any descendants that inherited its RowSet. Table operations that inherit RowSets include column projection and derivation operations like select and view, as well as some join operations with respect to the left input table; e.g., natural join, exact join, and as-of join.
A table may share any of its ColumnSources with any other table in its update graph that uses the same row key space or whose row key space can be redirected onto the same row key space. A single parent table is responsible for updating the contents of a given ColumnSource for itself and any descendants that inherited that ColumnSource. Operations that allow this sharing without redirection include where, as well as any column transformation that passes through columns unchanged or simply renamed, and some join operations with respect to the left-hand table’s ColumnSources. Operations that allow ColumnSource sharing with redirection include sort, as well as most joins with respect to the right-hand table’s ColumnSources.
By itself, this sharing capability represents an important optimization that avoids some data processing or copying work. When considered in an updating query engine, it should be clear that this avoidance extends to each update cycle, paying dividends for the lifetime of a query.
Performance impact: Shared ColumnSources can reduce memory footprint by 50-90% for queries with multiple filtered or joined views of the same source data. For example, five different where filters on a 10-column table share all 10 ColumnSources, storing only five different RowSets instead of duplicating 50 columns.
Furthermore, the possible sparsity of the RowSet's row key space allows for greatly reduced data movement within the RowSet itself and the ColumnSources it addresses. This is essential for the performance of Deephaven’s incremental sort operation, as well as in many cases when source tables publish changes that are more complex than simple append-only growth; e.g., multiple independently-growing partitions, or tabular representations of key-value store state.
Mechanical sympathy
“You don’t have to be an engineer to be a racing driver, but you do have to have Mechanical Sympathy.”
– Jackie Stewart, racing driver
This section heading and quote might be better explained by one of our favorite blogs. As systems programmers, we know that it’s best to use our tools (JVM, host OS, underlying I/O subsystems, CPU, etc) in the way that they were designed to be used most effectively. We’ve optimized our query engine with this principle in mind, although this remains and always will remain a work in progress.
More specifically…
Deephaven’s approach to mechanical sympathy can be summarized with a few key observations:
- Aggregations and operations: Often best served at scale through vertical structures. Deephaven's column orientation provides flexibility and performance.
- Data movement: Can have high fixed costs. It's best to amortize those costs over many rows/cells/bytes to achieve higher throughput. However, fetching more data than needed causes "read amplification", and oversized blocks harm cache performance. Deephaven uses block-oriented reads with carefully chosen sizes.
- Predictable code: Code that doesn't mislead the branch predictor is easier for the CPU to optimize. Deephaven's engine minimizes branches, especially in inner loops. Generated code prunes unreachable cases.
- JIT compilation: Modern JVMs deliver excellent performance when properly utilized. We help by:
- Avoiding virtual method invocations in inner loops.
- Operating on dense memory regions to enable vectorization.
- Leveraging Vector API support (Java 19+ preview feature) for explicit SIMD operations.
- Garbage collection: Can cause serious performance degradation through CPU consumption and unpredictable pauses. Deephaven uses preallocation and object pooling to reduce young generation pressure. Inner loops reuse objects instead of allocating temporaries.
- Concurrency: Can be counterproductive if poorly designed. Resource contention, false sharing, and thrashing can make concurrent code slower than single-threaded equivalents. Deephaven avoids shared state and provides tools for natural parallelization along partition boundaries.
Chunk-oriented architecture
The Deephaven query engine moves data around using a data structure called a Chunk. This subsystem is key to achieving mechanical sympathy in our implementation.
By working with chunks of data rather than single cells, we allow the engine to amortize data movement costs at every applicable level of the stack. For example, ColumnSources are ChunkSources, allowing bulk getChunk and fillChunk data transfers. These data transfers may in turn be implemented by wrapping or copying arrays, by reading the appropriate region of a file, or by evaluating a formula once for each result element.
Performance impact: Processing data in chunks of thousands of elements instead of one at a time reduces method call overhead by orders of magnitude and enables SIMD vectorization, delivering 4-8x throughput for arithmetic operations on modern CPUs.
By structuring our engine operations as chunk-oriented kernels, we allow the JVM’s JIT compiler to vectorize computations where possible.
Chunks are strongly-typed by the storage they represent; as such, there is an implementation for each Java primitive type and an additional one for Java Objects, and a separate WritableChunk hierarchy for chunks that may be mutated. They are parameterized by a generic Attribute argument that allows compile-time type safety according to the kind of data stored in a chunk; e.g., values, ordered row keys, hash codes, etc, without runtime cost.
The Chunk type hierarchy is designed such that cellular data access is never performed using virtual method calls; cell accessors like get, set, and add are always final and should be easy to inline. Only bulky methods like slice and copy tend to be truly virtual, with multiple implementations.
Chunks are pooled to allow re-use as temporary data buffers without significant impact on garbage generation, thus reducing garbage collection frequency and duration.
Deephaven currently implements chunks as regions of native Java arrays, with implementations for each primitive type as well as an additional one for Object references. In the future we might switch to use Apache Arrow ValueVectors (called Arrays in the C++ implementation) or another high-performance implementation.
Columnar hash tables
Building further on our chunk-oriented engine design, Deephaven join and aggregation operations frequently rely on a columnar hash table implementation that allows chunks of single or multi-element keys to be hashed and inserted or probed in bulk operations where data patterns permit. Each component of this operational building block attempts to enable vectorization and avoid virtual method lookups by relying on chunk-oriented kernels, whether for hashing data, sorting data, looking for runs of identical values, and so on.
RowSet implementations
Another area of the Deephaven query engine that merits specific attention is our RowSet implementation. In practice, RowSets switch between a number of implementation options depending on size and sparsity. Currently, there are three in use:
- Single Range: Exactly what it sounds like, ideal when all row keys in a
RowSetare contiguous. - Sorted Ranges: Like single range, but more than one, and in sorted order. Ideal for tables with a small number of contiguous ranges, no matter how widely separated.
- Regular Space Partitioning: Our take on the popular Roaring Bitmaps (RB) data structure, but with substantial optimizations to allow for widely distributed row key ranges. We use a library of containers initially derived from the Java RB implementation, with a few special case containers added to allow for a smaller memory footprint in important edge cases. These containers are organized in an array as in RB, but ranges of containers that would be entirely full are stored as a single entry in a parallel array.
In all cases, the goal is to allow for efficient traversal or set operations with minimum storage cost and high throughput. This is crucial, as every table operation within Deephaven relies in part on the performance characteristics of these data structures.
Performance characteristics:
| Implementation | Best For | Memory | Operations |
|---|---|---|---|
| Single Range | Contiguous keys | O(1) | O(1) |
| Sorted Ranges | Few ranges | O(ranges) | O(log ranges) |
| RSP | Sparse, large sets | O(containers) | O(containers) |
Regular Space Partitioning (RSP) vs Binary Space Partitioning (BSP)
Regular Space Partitioning (RSP) is a fundamental and unique data structure used by every table operation in Deephaven's various APIs. Deephaven's RSP uses the Roaring Bitmaps RoaringArray as a technical building block. It fixes some of the shortcomings of Binary Space Partitioning (BSP), particularly those related to the overhead of operations on large RowSets.
RSP improves upon BSP by partitioning
RowSets at fixed points instead of arbitrary ones. For large datasets, this has multiple benefits: not only does RSP guarantee that the pieces in eachRowSetalign, but it also eliminates the need to worry about iterators crossing array boundaries at different points for eachRowSet.
BSP allows a system to accumulate a set of values (i.e., a RowSet) in a sorted array. For example, the following sorted array of only a few values is very simple and efficient:
To keep an array sorted when performing operations such as an insert, the system must first find where to put the new value. This requires a binary search, which is an O(log n) operation. Next, space needs to be made for the new value. As the set grows, the array is split around the middle (the binary space partition), and the two pieces are arranged in a tree structure.
For big RowSets - often accumulating millions of values - the overhead on BSP operations can be high. As a single RowSet is created or grows, the binary subdivision operation can be expensive. Operations involving mixing two different RowSets (e.g., union, intersect, or set difference) can be particularly expensive because they need to look at the individual values in each RowSet and decide what will happen in the result.
Going back to the previous example, in BSP, if we need to insert 10 into the above array, Deephaven asks: Is the resulting array too big? If yes, the system splits it at a median value, creating two sub-arrays and a parent node:
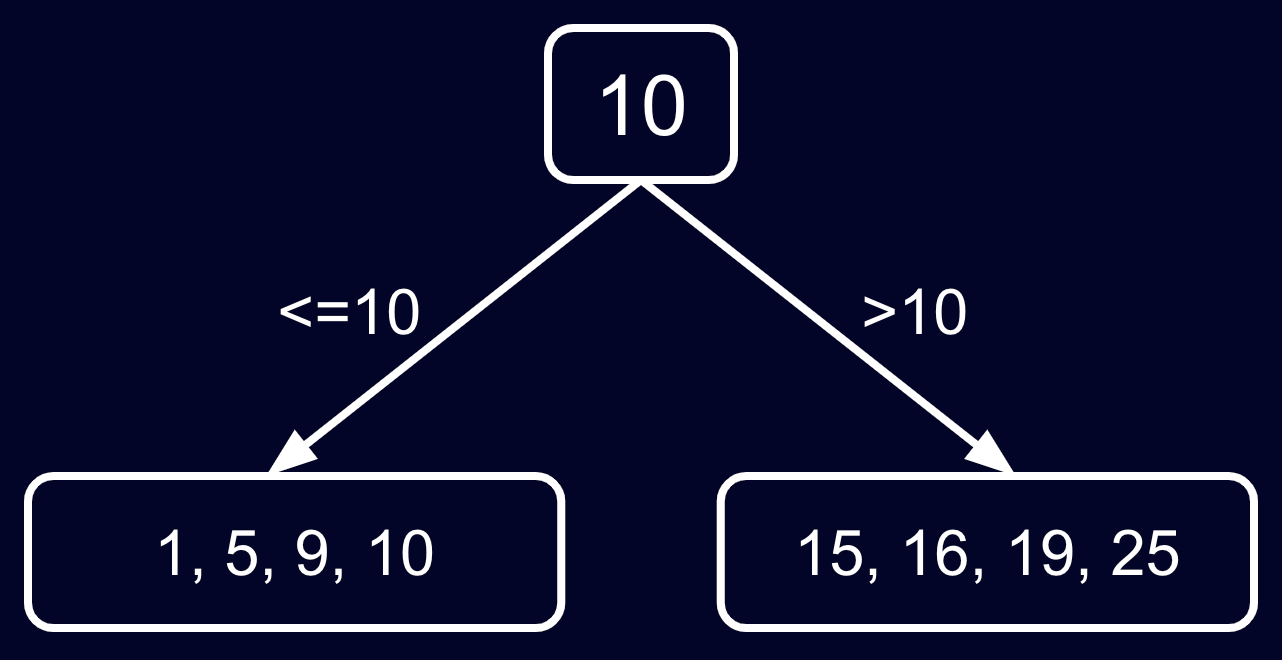
In this case, 10 is the parent node that directs which sub-branch to descend when a search is performed.
Unlike BSP, RSP forces partitioning at specific fixed points. It divides the space in fixed ranges of 2^16 (65,536) values. In this data structure, a RowSet is an array of containers, each containing at most 2^16 elements. In our BSP example, the median value 10 bubbles in the tree to separate two nodes. In RSP, this would be n * 2^16 for some n. The key difference is that in BSP, the middle of the array is the point where the partitioning takes place, which bubbles up as an inner tree node. In RSP, this cannot be arbitrary, since it's always an integer multiple of 2^16.
Consider operations such as union, set difference, or intersect. The system can work on the corresponding containers without caring about boundaries between them. For instance, the position for RowSet key 65,537 can only be in the container where n = 1, so Deephaven always knows exactly where to look.
For large datasets, RSP is usually much faster at these operations. If the system can work in pieces at a time for each operation and guarantee that the pieces on each RowSet align in terms of values, they can be worked on more efficiently without having to worry about iterators crossing individual array boundaries at different points for each RowSet.
RSP also compactly represents values. It would be inefficient to write out every single value in a big range - let's say all of the values in the set [ 0, 1000 * 2^16 ]. Deephaven would have to create 10,000 containers, with all keys in each of them present. Instead, Deephaven has a compact way to represent continuous ranges of values that can span full blocks in [ n * 2^16, m * 2^16 - 1 ] space, for some value of n and m where m > n.
Nevertheless, small RowSets are more expensive in RSP because they are still comprised of an array of containers first and then the containers themselves. This matters for queries that need to create one RowSet per row (e.g., joins). This issue is alleviated by creating a special case for single-range RowSets.
Formula and condition evaluation
Deephaven table operations often support complex, user-defined expressions for creating columns (“formulas”) or filtering (“conditions”). We’ve taken several key design decisions that either enable interesting use cases or allow for significant optimization.
Expression parsing
Deephaven uses JavaParser to turn user-specified expressions into three implementation categories:
- Simple pre-compiled Java class instances: For common operations, avoiding compilation overhead.
- New Java classes: Dynamically compiled, loaded, and instantiated for complex expressions.
- Numba-compiled machine code: Numba JIT compilation for Python expressions.
Given these options, simple expressions can be explicitly optimized and avoid any compilation overhead. Complex expressions, on the other hand, allow for a wide degree of latitude in method calls, conditionality, and positional column access.
Example of formula evaluation:
Part of this process replaces column name references with parameters that can then be supplied from data loaded efficiently in chunks. It also allows for columns to be accessed as logical arrays in row position space.
Integrating user methods
One critical aspect of complex formula or condition evaluation is the ability to apply any user function that can be callable via Java, either directly or via JNI. This allows for users to “extend” the query language with their own functionality by integrating external models and algorithms into their queries. This, in turn, enables all manner of exciting integrations with data science toolkits, whether open source or proprietary.
Further work
There is a lot more we can do in this area, especially considering some of the tools that have matured in recent years. We’re especially interested in exploring alternative bytecode-generation strategies and integrating GraalVM as a compilation option.
Bridging Java and Python: JPY
Although the core of Deephaven is implemented in Java, we consider Python to be the most important language in use for writing Deephaven queries. We have invested significantly in a fork of the open source JPY project, and are currently working with the project’s contributors to evolve capabilities. Written in C with JNI and Python C APIs, JPY is a performant, low level library.
To maximize the familiarity of the Deephaven data science and app-dev experience, we have developed a transparent, pure Python API that relieves the user from the details of calling JPY. During the design and implementation of this Pythonic API, special care was taken to minimize the number of crossings between JNI and Python runtime.
Building UIs
Deephaven provides two approaches for building custom user interfaces:
-
deephaven.ui: A Python web framework for building real-time data-focused applications. Write scripts entirely in Python — no front-end engineering, JavaScript, or CSS required.Key features:
- Components: Create user interfaces from components defined entirely with Python
- Live dataframe aware: Components can use Deephaven tables as a data source
- Reactive: UI components automatically update when the underlying Python data changes
- Declarative: Describe the UI as a function of the data and let the framework handle the rest
- Composable: Combine and reuse components to build complex interfaces
- Wide range of components: From simple text fields to complex tables and plots
For complete documentation, tutorials, and examples, see the
deephaven.uidocumentation. -
web-client-ui: JavaScript/TypeScript components for building custom web applications with full control over the front-end.
gRPC APIs for polyglot interoperability
Deephaven's core API is implemented using polyglot technologies that allow for compatible client (or server!) implementations in almost any language. It is composed of several complementary modules, but its Arrow Flight service and Table service are foremost. These offer high-performance data transport — specifically organized to include real-time and updating data — and a table manipulation API that mirrors the Deephaven engine's internal compute paradigm. You can read more about our API itself here.
Distributing DAGs and global consistency
At Deephaven, we believe that our approach to propagating static and updating tabular data will revolutionize distributed data systems development. It represents a powerful new model.
As touched upon briefly earlier in this piece, the Deephaven query engine propagates updates concurrently via a DAG, relying on a logical clock to mark phase and step changes for internal consistency. While this sort of coordination is suitable within a single process, the overhead increases exponentially when extending such a DAG across multiple processes.
Based on this observation, we've implemented a design for multi-process data-driven applications that relies on consistent table replication using initial snapshots followed by subsequent deltas. This allows nodes to operate with their logical clocks mutually decoupled, allowing truly parallel update propagation. This also allows for bidirectional data flows, with nodes that publish a given table able to act as consumers for other tables.
This approach intentionally trades away "global consistency" for increased throughput and scalability. In practice, we think that such a global view is either illusory or better implemented via end-to-end sequence numbers that allow for data correlation within the query engine. By illusory we mean to observe that input sources often publish in a mutually-asynchronous manner, thus constraining the possibilities for true consistency to something narrower; e.g., "mutual consistency based on the inputs observed at a given point in time." For data sources that do contain correlatable sequence numbers, Deephaven offers tools for synchronizing table views to reconstruct a truly consistent state.
The whole is greater than….
Deephaven is the result of evolution. Better stated, Deephaven’s architecture is the effect of requests and feedback from sophisticated users coupled with the R&D efforts of a dedicated development team over many years. Compelling problem sets deserve prolonged attention, and servicing real-time app-dev and data science use cases certainly qualifies.
Deephaven Community Core is specifically designed, delivered, and packaged to be modular. This is both consistent with modern best practices and strategies to maximize its software’s extensibility and value to the community it serves. In exploring the components of its value proposition, we hope you conclude that taken together, Deephaven offers a compelling stack for your data-driven use case. Sometimes range matters. And range is a Deephaven superpower.
Related documentation
Conceptual guides
How-to guides
UI frameworks
deephaven.uidocumentationdeephaven.uiarchitectureweb-client-uion GitHub- @deephaven/grid component
An in-depth look at what we’ve done, why we’ve done it, and why you should care.