Deephaven Data Tailer
The Deephaven Data Tailer is a powerful and flexible service for automating the ingestion of real-time data into your Deephaven environment. Acting as a bridge between file-based data sources and the Data Import Server (DIS), the Tailer continuously monitors directories for new or updated files—such as logs or CSVs—produced by applications, services, or other Deephaven processes. As soon as new data is detected, the Tailer efficiently reads and forwards it for immediate intraday storage and analysis, ensuring your tables are always up to date.
The Tailer is highly configurable: you can run multiple Tailers in parallel, each with its own rules for which files to process and where to route the data. This enables scalable, robust data pipelines that adapt to a variety of operational needs, from simple single-table setups to complex, multi-source environments. Typical deployments run Tailers on the same nodes where data is produced, minimizing latency and maximizing throughput.
Key features include:
- Automated file discovery and ingestion for both Deephaven binary log files and CSV files
- Support for partitioned data, enabling high-frequency and time-series workflows
- Flexible configuration for routing, filtering, and managing multiple data streams
- Seamless integration with Deephaven's internal partitioning and routing infrastructure

Each Tailer instance is uniquely identified—often by a name or numeric ID set at startup—and can be independently managed or restarted. For most users, the default Tailer configuration will be sufficient, but advanced scenarios are supported through custom configuration files and properties.
Tailer configuration consists of three parts: process-level settings, table/log definitions, and destination (routing) configuration. For a full breakdown of these components, see the Tailer configuration section below.
Note
In most cases, you will not need to run additional Tailers or change the Tailer configuration. The data routing configuration defines which DISs handle a given table, and no Tailer configuration is needed.
The default configuration for Deephaven includes a Tailer that operates on every Deephaven node. This Tailer identifies and monitors all files that follow the standard Deephaven filename format, which are located in the standard directories (including /var/log/deephaven/binlogs). You can add additional file locations by using the log.tailer.defaultDirectories or log.tailer.additionalDirectories properties.
Intraday Partitioning
Deephaven partitions all intraday data into separate directories, effectively creating multiple sets of data files distributed across these directories. When querying intraday data or merging it into the historical database, all the intraday partitioning directories are combined into a single table. In most cases, users are not directly aware of this partitioning; however, configuring the Tailer requires a comprehensive understanding of this structure to use it correctly.
Deephaven is highly optimized for appending data to tables. To facilitate this, it is essential that only one data source writes to a specific set of underlying intraday data files at any given time. This is one of the primary reasons for implementing intraday partitioning. Since most real-time data sources utilize Deephaven loggers to generate data, and this data is then processed through the Tailer, it is the Tailer that determines the appropriate internal partition directories for appending the intraday data.
The Tailer establishes two levels of partitioning when sending data to the Data Import Server (DIS). When the Tailer is configured to set up both levels correctly, it ensures that the data is appropriately separated. The DIS will create distinct directories at each level of partitioning, and the lowest-level subdirectories will each contain a set of data files for the table.
- Internal partitions are the first level of partitioning and typically correspond to a data source. The configuration of the Tailer usually determines the value of the internal partition based on the name of a binary log file, possibly incorporating additional information from its configuration for further differentiation. The schema does not define internal partitions. In some Deephaven tools, such as importers, the internal partition is also called the destination partition.
- Column partitions divide the data based on the partitioning column specified in the table's schema, a String column that frequently contains a date value. The Tailer determines the column partition value based on a log file name. For date-based column partitioning, the value is usually in
yyyy-MM-ddformat (e.g., 2017-04-21).
Binary log filename format
The Tailer runs in a configuration where it automatically monitors binary log directories for new files, looking for new partitions and processing them appropriately. To assist in these file searches, binary log filenames must be in a standard format, with several parts separated by periods. Support is provided for filenames in other formats, but this requires additional configuration (explained later).
The default filename format is <Namespace>.<Table Name>.<System or User>.<Internal Partition>.<Column Partition>.bin.<Timestamp>, which has the following components separated by periods:
- The table's namespace.
- The table's name.
- The table's namespace set (
SystemorUser). - The internal partition value.
- The column partition value (usually a date).
.bin.is the expected separator for binary log files.- The date and time the file was created. This enables file sorting.
The following example from a Deephaven internal table illustrates a typical filename:
DbInternal- the table's namespace.AuditEventLog- the table's name.System- the type of table that, in this case, belongs to a system namespace.Userwould indicate a user namespace.vmhost1- the internal partition used to distinguish a data source, usually a host name.2017-07-23- the column partition value. This is frequently a date inyyyy-MM-ddformat (or another specified format that includes the same fields), but any partitioning method may be used as long as the filename can be used to distinguish the partition..bin.- the file identifier that distinguishes this as a Deephaven binary log file. The standard identifier is.bin..2018-07-23.135119.072-0600- a timestamp to process the files in order. The standard format used in this example is a timestamp down to the millisecond inyyyy-MM-dd.HHmmss.SSSformat, followed by timezone offset. The timezone offset is important to correctly sort files during daylight-savings transitions.
Bandwidth Throttling
The Tailer configuration provides the option to throttle the throughput of data sent to specific destinations, or the throughput sent for a specific log entry (per destination). This should only be used if network bandwidth is limited or issues have been encountered due to unexpected spikes in the amount of data being processed by the Tailer. Because it restricts how quickly the Tailer will process binary log files, use of this feature can cause Deephaven to fall behind in getting real-time data into the intraday database. Throttling is optional and will not be applied unless specified.
Two types of throttling are supported:
- Destination-level throttling is applied to each destination (Data Import Server), and is specified in the data routing configuration for a given data import server.
- Log-entry-level throttling is applied to each destination for each log entry in the XML file and across all partitions for that log entry. It is specified with the
maxKBpsattribute in a log entry.
Throttles are always specified in kilobytes per second (KBps). Because the binary log files are sent directly to the Data Import Servers without translation, the size of the binary log files can give an indication of the required bandwidth for a given table. For example, if a particular table's binary log files are sized at 1GB each hour, then an approximate bandwidth requirement could be calculated as follows:
- Since throttles are specified in KBps, first translate GB to KB: 1GB = 1,024MB = 1,048,576 KB.
- Next, divide the KB per hour by the number of seconds in an hour: 1,048,576 KB per hour / 3,600 seconds per hour = 291.3KB per second.
- In this case, setting a 300 KBps throttle would ensure that each hour's data could be logged, but latency will occur when data delivery to the log file spikes above the specified 300 KB/s throttle rate.
Throttling uses a token bucket algorithm to provide an upper bandwidth limit and smoothing of peaks over time. The token bucket algorithm requires, at a minimum, enough tokens for the largest messages Deephaven can send, and this is calculated by the number of seconds (see the log.tailer.bucketCapacitySeconds property) times the KBps for the throttle. Currently, Deephaven sends maximum messages of 2,048KB (2MB), so the number of seconds in the bucket times the bandwidth per second must equal or exceed 2,048K. The software will detect if this is not true and throw an exception that prevents the Tailer from starting.
The bucket capacity also impacts how much bandwidth usage can spike, as the entire bucket's capacity can be used at one time.
- If
log.tailer.bucketCapacitySecondsis 10, and a throttle allows 10 KBps, then the maximum bucket capacity is 100KB, which is not sufficient for Deephaven; the bucket would never allow the maximum 2,048KB message through. Deephaven will detect this and fail. - If
log.tailer.bucketCapacitySecondsis 60, and a throttle allows 1000KBps, then the bucket's capacity is 60,000K. If a large amount of data was quickly written to the binary log file, the Tailer would immediately send the first 60,000K of data to the DIS. After that the usage would level out at 1,000KBps. The bucket would gradually refill to its maximum capacity once the data arrival rate dropped below 1,000KBps, until the next burst.
Binary Log File Managers
The Tailer must be able to perform various operations related to binary logs.
- It must derive namespace, table name, internal partition, column partition, and table type values from binary log filenames and the specified configuration log entry.
- It must determine the full path and file prefix for each file pattern that matches what it is configured to search for.
- It must sort binary log files to determine the order in which they will be sent.
These operations are handled by Java classes called Binary Log File Managers. Two Binary Log File Managers are provided.
StandardBinaryLogFileManager- this provides functionality for binary log files in the standard format described above (<namespace>.<table name>.<table type>.<internal partition>.<column partition>.bin.<date-time>)DateBinaryLogFileManager- this provides legacy functionality for binary log files using date-partitioning in various formats.
The default Binary Log File Manager specified by the log.tailer.defaultFileManager property is used unless the fileManager XML attribute is included.
For the Tailer to function correctly, file names for each log must be sortable. Both Binary Log File Manager types will take into account time zones for file sorting (including daylight savings time transition), assuming the filenames end in the timezone offset (+/-HHmm, for example "-0500" to represent Eastern Standard Time). The standard Deephaven Java logging infrastructure ensures correctly-named files with full timestamps and time zones. Note that the DateBinaryLogFileManager does not consider time zones in determining the date as a column partition value, only in determining the order of generated files; the column partition's date value comes from the filename and is not adjusted.
Tailer configuration
Deephaven property files, Tailer-specific XML files, and data routing configuration control the Tailer's behavior.
- Property definitions – Tailer behavior that is not specific to tables and logs is controlled by property definitions in Deephaven property files.
- Table and Log definitions – detailed definitions of the binary logs containing intraday data and the tables to which those logs apply are contained in XML configuration files. Each Log entry in these XML files corresponds to a single Binary Log File Manager instance.
- Destination (routing) configuration – specifies where the Tailer should send data. This is configured in the data routing configuration, which determines how tables are routed to Data Import Servers (DISs) and other destinations.
Property file configuration parameters
This section details all the Tailer-related properties. Properties may be specified in property files, or passed in as Java command line arguments (e.g., -Dlog.tailer.processes=db_internal).
Configuration file specification
These properties determine the processing of XML configuration files, which are read during Tailer startup to build the list of Logs handled by the Tailer.
| Property | Description | Example |
|---|---|---|
log.tailer.configs | A comma-delimited list of XML configuration files defining the tables being sent. The classpath is followed to locate the named files. | log.tailer.configs=tailerConfigDbInternal.xml (default location: /usr/illumon/latest/etc/tailerConfigDbInternal.xml) |
log.tailer.processes | A comma-delimited list of processes for which this Tailer will send data. Each process should correspond to a <Process> tag in the XML configuration files. If the list is empty or not provided, the Tailer will run but not handle any binary logs. If it includes an entry with a single asterisk (*), the XML entries for all processes are used. | log.tailer.processes=db_internal,customer_logger_1 |
Tailer properties
These properties specify the name and runtime attributes of the Tailer:
| Property | Description | Example |
|---|---|---|
intraday.tailerID | Specifies the Tailer ID (name) for this Tailer. Usually set by startup scripts on the Java command line rather than in a property file. | intraday.tailerID=customer1 |
log.tailer.enabled.<tailer ID> | If this is true, the Tailer will start normally. If false, the Tailer will run without tailing any files. | log.tailer.enabled.customer1=true |
log.tailer.bucketCapacitySeconds | The capacity in seconds for each bucket used to restrict bandwidth to the Data Import Servers. Applied independently to every throttle. Defaults to 30 seconds if not provided. | log.tailer.bucketCapacitySeconds=120 |
log.tailer.retry.count | (Optional) How many times each destination thread will attempt to reconnect after a failure. Default is Integer.MAX_VALUE. Value of 0 means only one connection attempt will be made. | |
log.tailer.retry.pause | The pause, in milliseconds, between each reconnection attempt after a failure. Default is 1000 ms (1 second). | |
log.tailer.poll.pause | The pause, in milliseconds, between each poll attempt to look for new data in existing log files or find new log files when no new data was found. Lower values reduce latency but increase processing overhead. Default is 100 ms (0.1 second). |
File watch properties
The Tailer will use underlying infrastructure to watch for new files to send to its Binary Log File Manager instances for possible tailing.
Caution
The logic used to watch for these files can be changed. However, the log.tailer.watchServiceType property should only be changed under advice from Deephaven Data Labs.
| Property | Description | Options/Examples |
|---|---|---|
log.tailer.watchServiceType | Specifies the watch service implementation to use. | JavaWatchService (efficient, but not for NFS); PollWatchService (works everywhere, less efficient) |
Memory properties
The following properties control the memory consumption of the Tailer and the Data Import Server.
| Property | Description | Default/Example |
|---|---|---|
DataContent.producersUseDirectBuffers | If true, the Tailer allocates direct memory for its data buffers. If changed, adjust JVM args in hostconfig. | true; -j -Xmx2g -j -XX:MaxDirectMemorySize=256m |
DataContent.consumersUseDirectBuffers | If true, the Data Import Server uses direct memory for its data buffers. | false |
BinaryStoreMaxEntrySize | Sets the max size in bytes for a single data row in a binary log file. Affects buffer sizes. | 1024 * 1024 |
DataContent.producerBufferSize.user | Buffer size in bytes for each User table data stream. | 256 * 1024 |
DataContent.producerBufferSize | Buffer size in bytes for each System table data stream. | 256 * 1024 |
DataContent.consumerBufferSize | Buffer size in bytes for the Data Import Server. Must be large enough for a producer buffer plus a full binary row. | 2 * max(DataContent.producerBufferSize, BinaryStoreMaxEntrySize + 4) |
DataContent.userPoolCapacity | Max number of user table locations processed concurrently. | 128 |
DataContent.systemPoolCapacity | Max number of system table locations processed concurrently. | 128 |
DataContent.disableUserPool | If true, user table locations are processed without a constrained pool. | false |
DataContent.disableSystemPool | If true, system table locations are processed without a constrained pool. | false |
Note
The Tailer allocates two pools of buffers, one for user tables and one for system tables. Each item in that pool requires two buffers for concurrency, so the memory required will be double the buffer size times the pool capacity.
Total memory required for the Tailer is approximately 2 * (DataContent.producerBufferSize * DataContent.systemPoolCapacity + DataContent.producerBufferSize.user * DataContent.userPoolCapacity).
Binary log file cleanup properties
The tailer provides an optional cleanup function that deletes binary log files after they have been fully processed. This is useful for managing disk space and ensuring that only relevant logs are retained. The cleanup job runs periodically and can be configured to delete files based on their age.
| Property | Description | Example/Default |
|---|---|---|
log.tailer.fileCleanup.enabled | Whether binary log files are deleted after all data has been sent to all destinations. Default is true for Kubernetes, otherwise false. | log.tailer.fileCleanup.enabled=false |
log.tailer.fileCleanup.deleteAfterMinutes | Minutes after a tailed log file is last modified before deletion if log.tailer.fileCleanup.enabled=true. Defaults to 240. | log.tailer.fileCleanup.deleteAfterMinutes=240 |
log.tailer.fileCleanup.startupDeletionCutoffTime | Optional and not set by default, the minimum age (format HH:mm or HH:mm:ss) of files to delete if log.tailer.fileCleanup.enabled=true. If this is set, then on startup the tailer will look for files it would have tailed but are older than the age defined by this parameter, and submit them to the cleanup job as if they have been tailed to all destinations (they'll only be deleted if log.tailer.fileCleanup.enabled=true). If not set or set to zero (e.g. 00:00), then don't look for old files to delete on startup. If this is defined, it must be greater than log.tailer.startupLookbackTime plus one day. Only the Standard Binary Log Manager provides this functionality. | log.tailer.fileCleanup.startupDeletionCutoffTime=72:00:00 |
log.tailer.fileCleanup.timerPeriodMinutes | The period (in minutes) between cleanup runs. Default is 10 minutes. | log.tailer.fileCleanup.timerPeriodMinutes=10 |
log.tailer.completedFileLog | Full path of a CSV file to list binary files that have been fully processed and may be (or have been if log.tailer.fileCleanup.enabled=true) deleted. The CSV file has two columns: LogTimestamp (ISO 8601) and Filename (absolute path). If not defined, then no CSV file is written. | log.tailer.completedFileLog=/var/log/deephaven/tailer/completed-logs.txt |
Caution
Be careful when using log.tailer.fileCleanup.startupDeletionCutoffTime because no effort is made to validate that the files have actually been tailed to all destinations. This is primarily useful for looking for files after restarts when the tailer has been down for a while, and is the only way to delete old files (those not actively being tailed) after a restart.
To ensure that standard cleanup doesn't conflict with the startup deletion lookback time, the log.tailer.fileCleanup.startupDeletionCutoffTime must be at least 24 hours longer than the log.tailer.startupLookbackTime property. This way, in a standard configuration, the tailer won't delete files with the same column partition value as files the tailer may be processing.
Miscellaneous properties
The following additional properties control other aspects of the Tailer's behavior.
| Property | Description | Example/Default |
|---|---|---|
log.tailer.defaultFileManager | Specifies which Binary Log File Manager is used for a log unless the log's XML configuration entry specifies otherwise. | log.tailer.defaultFileManager=com.illumon.iris.logfilemanager.StandardBinaryLogFileManager |
log.tailer.defaultIdleTime | If the Tailer sends no data for a namespace/table/internal partition/column partition combination for a certain amount of time (the "idle time"), it will terminate the associated threads and stop monitoring that file for changes. Format: HH:mm or HH:mm:ss. | Usually set for 01:10 |
log.tailer.defaultDirectories | Optional, comma-delimited list of directories where this Tailer should look for log files. If not specified, defaults are used from iris-defaults.prop. | log.tailer.defaultDirectories=<logroot>/binlogs,<logroot>/binlogs/pel,<logroot>/binlogs/perflogs |
log.tailer.logDetailedFileInfo | Whether the Tailer logs details on every file every time it looks for data. Default is false (only logs when new files are found). | log.tailer.logDetailedFileInfo=false |
log.tailer.additionalDirectories | Optional, comma-delimited list of directories appended to those in log.tailer.defaultDirectories. Use to specify additional directories. | Not set by default, an example is log.tailer.additionalDirectories=/Users/app/code/bin1/logs,/Users/app2/data/logs |
log.tailer.logBytesSent | Whether the Tailer logs information every time it sends data to a destination. Default is true. | log.tailer.logBytesSent=true |
log.tailer.startupLookbackTime | The amount of time (format HH:mm or HH:mm:ss) the Tailer should look back for files when starting. Used to ensure all data is sent after restarts. | Usually set for 01:10 |
Date Binary Log File Manager parameters
| Property | Description | Example/Default |
|---|---|---|
log.tailer.timezone | Optional property specifying the time zone for log processing. If not specified, the server's timezone is used. Used in calculating path patterns for date-partitioned logs and tables. | log.tailer.timezone=America_New_York |
log.tailer.internalPartition.prefix | Prefix for the Tailer's internal partition, used by DateBinaryLogFileManager to determine the start of the internal partition name. If not provided, the Tailer uses the server name or defaults to localhost. | log.tailer.internalPartition.prefix="source1" |
Tailer XML configuration files
Details of the logs to be tailed are supplied in XML configuration files.
Configuration file structure
Each Tailer XML configuration file must start with the <Processes> root element. Under this element, one or more <Process> elements should be defined. All <Process> elements in all configuration files with the same name will be combined.
<Process> elements define processes that run on a server, each with a list of <Log> entries which define the Binary Log File Manager details for the Tailer. Each <Process> element has a name that identifies a group of logs. The log.Tailer.processes property determines which <Process> names a Tailer will process, according to its XML configuration files. For example, the following entry specifies the default Binary Log File Manager for the db_internal process; a Tailer that includes db_internal in its log.tailer.processes property would use this Binary Log File Manager. Each parameter is explained below.
If the <Process> name is a single asterisk (*), every Tailer will use that Process element's Log entries regardless of its log.tailer.processes value.
Each <Log> element generates one Binary Log File Manager instance to handle the associated binary log files. Binary log files are presented to each Binary Log File Manager in the order they appear in the XML configuration files. Once a file manager claims the file, it is not presented to any other file managers.
Binary Log File Manager types
Each <Log> element specifies information about the binary log files that a Tailer processes. The attributes within each <Log> entry vary depending on the type of Binary Log File Manager chosen. The Log Element Attributes section provides full details on each attribute.
StandardBinaryLogFileManager and DateBinaryLogFileManager both allow the following optional attributes to override default Tailer properties; each is explained in detail later.
idleTimechanges the default idle time for when threads are terminated when no data is sent.fileSeparatorchanges the default file separator from.bin..logDirectoryorlogDirectoriesspecifies directories in which the Binary Log File Manager will look for files.excludeFromTailerIDsrestricts a Log entry from Tailers running with the given IDs.maxKBpsspecifies a Log-level throttle.
Standard Binary Log File Manager
The StandardBinaryLogFileManager looks for files named with the default <namespace>.<table name>.<table type>.<internal partition>.<column partition>.bin.<date-time> format. It will be the most commonly used file manager, as it automatically handles files generated by the common Deephaven logging infrastructure.
- The namespace, table name, table type, internal partition, and column partition values are all determined by parsing the filename.
- The optional
namespaceornamespaceRegexattributes can restrict the namespaces for this Binary Log File Manager. - The optional
tableNameortableNameRegexattributes can restrict the table names for this Binary Log File Manager. - The optional
tableTypeattribute restricts the table type for this Binary Log File Manager.
Date Binary Log File Manager
The DateBinaryLogFileManager requires further attributes to find and process files. It provides many options to help parse filenames, providing compatibility for many different environments.
- A
pathattribute is required, and must include a date-format conversion. It may also restrict the start of the filename. - If
pathdoes not restrict the filename, afilePatternRegexattribute should be used to restrict the files found by the Binary Log File Manager. - A
namespaceornamespaceRegexattribute is required to determine the namespace for the binary log files. - A
tableNameortableNameRegexattribute is required to determine the table name for the binary log files. - The optional
internalPartitionRegexattribute can be specified to indicate how to determine the internal partition value from the filename. If theinternalPartitionRegexattribute is not specified, the internal partition will be built from thelog.tailer.internalPartition.prefixproperty or server name, and theinternalPartitionSuffixattribute. - The column partition value is always determined from the filename, immediately following the file separator.
- The table type is taken from the optional
tableTypeattribute. If this is not specified, the table type isSystem.
Custom Binary Log File Managers
The existing Binary Log File Managers will cover most use cases; in particular, the StandardBinaryLogFileManager will automatically find and tail files that use the standard Deephaven filename conventions. If you need additional functionality, you can create a custom BinaryLogFileManager and specify it in the tailer's XML configuration file.
See the Javadoc for com.illumon.iris.logfilemanager.BinaryLogFileManager for details on how to do this. Extending the StandardBinaryLogFileManager class may be easier as a starting point.
Log Element Attributes
Unless otherwise specified, all parameters apply to both regular-expression entries and fully-qualified entries. These are all attributes of a <Log> element.
| Attribute | Description |
|---|---|
excludeFromTailerIDs | Excludes this log from the specified Tailer IDs. Example: excludeFromTailerIDs="CustomerTailer1" |
fileManager | Fully-qualified Java class implementing Binary Log File Manager for this Log. Example: fileManager="com.illumon.iris.logfilemanager.StandardBinaryLogFileManager". If not specified, property log.tailer.defaultFileManager determines the class to use. |
filePatternRegex | Regular expression that restricts file matches for a date Binary Log File Manager. Example: filePatternRegex="^[A-Za-z0-9_]*\.stats\.bin\.*" |
fileSeparator | Specifies the separator to be used if files do not include the standard .bin. separator. Example: fileSeparator="." |
idleTime | Time (in HH:mm or HH:mm:ss) after which threads created by this manager will be terminated if no data has been sent. Example: idleTime="02:00" |
internalPartitionRegex | For date Binary Log File Managers, regex applied to filename to determine the internal partition. Example: internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*" |
internalPartitionSuffix | Suffix to be added to the internal partition prefix. Example: internalPartitionSuffix="DataSource1" |
logDirectory | Specifies a single directory for log files. Example: logDirectory="/usr/app/defaultLogDir" |
logDirectories | Comma-delimited list of directories to search for files. Example: logDirectories="/usr/app1/bin,/usr/app2/bin" |
maxKBps | Maximum rate (in KB/s) at which data can be sent to each Data Import Server. Example: maxKBps="1000" |
namespace | Restricts/defines the namespace for this log entry. Example: namespace="CustomerNamespace" |
namespaceRegex | Regex to determine namespace from filename. Example: namespaceRegex="^(?:[^\.]+\.){0}([^\.]+).*" |
path | For date Binary Log File Managers, the filename (not including directory) for the log. Example: path="CustomerNamespace.Table1.bin.$(yyyy-MM-dd)" or path=".bin.$(yyyy-MM-dd)" |
tableName | Restricts/defines the table name for this log entry. Example: tableName="Table1" |
tableNameRegex | Regex to determine table name from filename. Example: tableNameRegex="^(?:[^\.]+\.){0}([^\.]+).*" |
tableType | Restricts/defines the table type for this log entry. Example: tableType="User" |
Regular expression example
It may be helpful to examine a standard set of regular expressions used in common Tailer configurations. A common filename pattern will be <namespace>.<tablename>.<host>.bin.<date/time>; the host will be used as the internal partition value. The following example filename provides an example of this file format:
EventNamespace.RandomEventLog.examplehost.bin.2017-04-01.162641.013-0600
In this example, the table name can be extracted from the filename with the following regular expression:
tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*"
This regular expression works as follows:
^ensures the regex starts at the beginning of the filename.(?:starts a non-capturing group, which is used to skip past the various parts of the filename separated by periods.[^\.]+as part of the non-capturing group; matches any character that is not a period, requiring one or more matching characters\.as part of the non-capturing group; matches a period.){1}ends the non-capturing group and causes it to be applied 1 time. In matches for other parts of the filename, the 1 will be replaced with how many periods should be skipped; this causes the regex to skip the part of the filename up to and including the first period.([^\.]+)defines the capturing group, capturing everything up to the next period, which in this case captures the table name..*matches the rest of the filename, but doesn't capture it.
For this example, the three attributes that would capture the namespace, table name, and internal partition are very similar, only differing by the number that tells the regex how many periods to skip:
-
namespaceRegex="^(?:[^\.]+\.){0}([^\.]+).*" -
tableNameRegex="^(?:[^\.]+\.){1}([^\.]+).*" -
internalPartitionRegex="^(?:[^\.]+\.){2}([^\.]+).*"
The above example could result in the following regular expression Log entry, which would search for all files that match the <namespace>.<tablename>.<host>.bin.<date/time> pattern in the default log directories:
Direct-to-DIS CSV Tailing
Deephaven supports tailing CSV files directly to the Data Import Server. To configure CSV tailing:
- Create and properly configure a schema with an
ImportSourceelement. This schema may be handwritten or generated via Schema Discovery. - Create and configure a Tailer configuration file in an appropriate customer-controlled location, such as
/etc/sysconfig/illumon.d/resources.- Mark the process as CSV format by adding an attribute
fileFormat="CSV". - Add a new tag
<Metadata>to provide the DIS with important information needed to properly process the CSV files.
- Mark the process as CSV format by adding an attribute
- Configure tailer properties to find the new configuration file and recognize the new process name by editing
iris-environment.prop. In a stanza appropriate to your tailer (e.g.,[service.name=tailer1|tailer1_query|tailer1_merge], marked with the comment# For all tailer processes): - Set
log.tailer.configsto include your configuration file. E.g.,log.tailer.configs=tailerConfigDbInternal.xml,newTailerConfig.xml - Set
log.tailer.processesto include your process name (or usedb_internal). E.g.,log.tailer.processes=db_internal,csv_data.
In the Tailer configuration file, the <Metadata> tag should contain a collection of <Item name="name" value="value"/> entries. The valid Items are:
importSourceName- (Required) The name of a valid ImportSource from the table’s schema. The DIS will use this description to parse the CSV.charset- (Optional) The charset encoding of the files. If omitted, this defaults toUTF-8.format- (Optional) The format of the CSV file. This may be any one of the supported CSV formats except BPIPE (see Importing CSV files).hasHeader- (Optional) Indicates whether the file has a header line. This defaults totrue.delimiter- (Optional) The delimiter between CSV values. If omitted, this uses the delimiter of the specified format.trim- (Optional) Specify that CSV fields should be trimmed before they are parsed.rowsToSkip- (Optional) The number of rows (excluding the header) to skip from each file tailed.constantValue- (Optional) - The value to use for constant fields.
Once these have been configured and the Tailer started, any CSV files produced in the specified paths will be tailed directly to the DIS.
An example follows:
This simpler example will make the default Tailer pick up CSV files in /var/log/deephaven/binlogs:
Transactional processing
In many cases, it is desirable to process sets of rows as a transaction. There are two different methods for supporting this paradigm.
Transaction column
The first and best method is to designate a specific column in the CSV as a “Transaction” column. This allows the source writing the CSV to control when transactions are started and completed. To enable this mode of processing, you must add the rowFlagsColumn metadata item to the Tailer configuration file.
<Item name=”rowFlagsColumn” value=”rowFlags”/>
This will designate a column “rowFlags” as a special column. Transactions are started by writing a row with StartTransaction in the “rowFlags” column. Subsequent rows that are part of the transaction should have “None” written to the “rowFlags” column, and to end the transaction, write a row with “EndTransaction” in the “rowFlags” column.
You may write “SingleRow” for rows that should be logged independently, not as part of a transaction.
Caution
While you are in a transaction, writing “SingleRow” or “StartTransaction” will abort the transaction in progress!
Automatic transactions
In some cases, the format of the CSV may not be changeable. In these cases, you may use automatic transactions to accomplish a similar goal.
Caution
Automatic transactions are not recommended unless they are absolutely necessary.
Automatic transactions ensure that every row logged is part of a transaction. When a new file is encountered or no rows have been received within the timeout window, the current transaction is completed, and subsequent rows begin a new transaction.
To enable automatic transactions, add the following setting to the Tailer configuration metadata:
<Item name="transactionMode" value="NewFileDeadline"/>
<Item name="transactionDeadlineMs" value="30000"/>
The first setting enables automatic transactions, while the second specifies the inactivity timeout in milliseconds for which the system will automatically complete a transaction.
Running a remote Tailer on Linux
The Deephaven log Tailer (LogTailerMain class) should ideally run on the same system where log files are generated. It is strongly recommended that the storage used by the logger and Tailer processes is fast, local storage, to avoid any latency or concurrency issues that might be introduced by network filesystems.
Note
See also: How to automate configuration of clients and remote servers
Setup process
To set up an installation under which to run the LogTailerMain class:
- Install Java SE runtime components, including the Java JDK (devel package). The Tailer can sometimes be run with a JRE, but if advanced non-date partition features or complex data routing filtering are used, a JDK is required. This should match the version of Java installed on the Deephaven cluster servers. The presence and version of a JDK can be verified with
javac -version. - Create a directory for a Tailer launch command, configuration files, and workspace and logging directories. This directory must be accessible for read and write access to the account under which the Tailer will run.
- Obtain the JAR and configuration files from a Deephaven installation (either copied from a server, or installed and/or copied from a client installation using the Deephaven Launcher), or use the
Deephaven Updaterto synchronize these from the Client Update Service. TheDeephaven Updateris the recommended approach, as it allows automation of runtime updates for headless systems.
Note
The current version of the DeephavenLauncher tar will vary from release to release, and the actual URL will vary with your installation. See Find the Client Update Service Url to determine the correct values.
Deephaven in the above example is the friendly name for this instance. Any name can be used, but a name without spaces or special characters will be easier to use in scripts.
The Deephaven Updater should be re-run periodically to ensure the Tailer has up-to-date binaries and configuration from the Deephaven server. We recommend running it before each Tailer startup as part of the Tailer start script.
- Create the following directories, and ensure the account under which the Tailer will run has access to them:
/var/log/deephaven/tailer- the process logging path. It is sufficient, and recommended, to create/var/log/deephavenand grant the Tailer account read/write access to this path. An alternate logging path can be configured with a custom value passed to the-DlogDirJVM argument when starting the Tailer./var/log/deephaven/binlogs- the root path for binary log files, and the recommended location for local loggers to write their log files./var/deephaven/run- the account will need read/write access here to create and delete PID files (can be overridden with a custom JVM argument-DpidFileDirectory)./var/deephaven/binlogs/peland/var/deephaven/binlogs/perflogs- these directories are default monitored paths by all Tailers; other Deephaven processes may use them on the remote Tailer host.
- Create a launch command to provide the correct classpath, properties file, and other installation-specific values needed to run the Tailer process.
Note
The classpath paths include Deephaven configuration files (resources), jars (java_lib/*), a root path for other configuration (Deephaven), and, in this example, the directory that contains the Tailer config XML file (iris).
The --add-opens flags are required for Java 11 and later versions to allow access to internal JDK modules that Deephaven uses.
- Configure startup for the Tailer process.
Management and logging
The remote Tailer can be managed using systemd commands:
Logging for the Tailer process will be under /var/log/deephaven/tailer, unless an alternate path is passed to the -DlogDir JVM argument.
Running a remote Tailer on Windows
The Deephaven log Tailer (LogTailerMain class) should ideally be run on the same system where log files are being generated. Since this class has no dependency on *nix filesystem or scripting functionality, it can be run under Java as a Windows process or service when a Windows system is generating binary log data.
Note
See also: How to automate configuration of clients and remote servers
Requirements
To set up an installation under which to run the LogTailerMain class:
- Install Java SE runtime components or use the Launcher installation that includes the Java JDK. The Tailer can sometimes be run with a JRE, but if advanced non-date partition features or complex data routing filtering are used, a JDK is required.
- Create a directory for a Tailer launch command, configuration files, and workspace and logging directories. This directory must be accessible for read and write access to the account under which the Tailer will run.
- Create the following directories, and ensure the account under which the Tailer will run has access to them:
\var\log\deephaven\tailer- the process logging path. It is sufficient, and recommended, to create\var\log\deephavenand grant the Tailer account read\write access to this path. An alternate logging path can be configured with a custom value passed to the-DlogDirJVM argument when starting the Tailer.\var\log\deephaven\binlogs- the root path for binary log files, and the recommended location for local loggers to write their log files.\var\deephaven\run- the account will need read\write access here to create and delete PID files (can be overridden with a custom JVM argument-DpidFileDirectory).\var\deephaven\binlogs\peland\var\deephaven\binlogs\perflogs- these directories are default monitored paths by all Tailers; other Deephaven processes may use them on the remote Tailer host.
-
Obtain the JAR and configuration files from a Deephaven installation (either copied from a server, or installed and/or copied from a client installation using the Deephaven Launcher), or use the
Deephaven Updaterto synchronize these from the Client Update Service. We recommend using theDeephaven Updateras it can automate runtime updates for headless systems. -
Create a launch command to provide the correct classpath, properties file, and other installation-specific values needed to run the Tailer process.
-
Configure startup for the Tailer process.
Note
Since Windows does not support inotify, Tailers on Windows must be configured to use the PollWatchService.
Example Directory
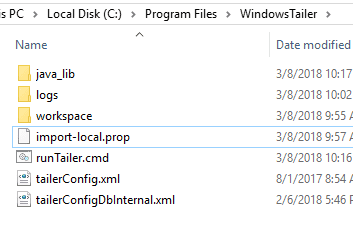
This directory was created under Program Files, where administrative rights will be needed by the account under which the Tailer will run. In this example, the Tailer is being run as a service under LocalSystem, and the Deephaven resources and jars were manually synchronized to this path. Specific accounts with more limited rights than LocalSystem would also be valid. The key requirements are that the account must be able to write to the logs and workspace directories, must be able to read from all files to be tailed and all configuration and JAR files, and must have sufficient network access to contact the DIS.
Note that this directory contains a TailerConfig XML file, which specifies the Tailer's configuration (i.e., which binary log files it will tail) and a property file, which specifies other Tailer configuration options, including where the Tailer will send the data. For full details on Tailer configuration, see Tailer Configuration. This directory also contains a logs and a workspace directory, which can be created empty, and a java_lib folder that was copied, with its JAR files, from the directory structure set up by the Deephaven Launcher client installer.
As new releases of Deephaven are applied to an environment, the JAR files in java_lib must be updated so that any new Tailer or Tailer support functionality is also available to Windows-based Tailer processes. The Deephaven Updater makes it simple to automate this update.
We recommend running the Updater before each Tailer startup as part of the Tailer start script.
Launch Command
The launch command in this example is a Windows cmd file. It contains (effectively) one line (^ is the line continuation character for Windows .bat and .cmd files):
The components of this command follow:
java- Must be in the path and invoke Java matching the version used by the Deephaven server installation.-cp "[instance_root]\[instance_name]\resources";"[instance_root]\[instance_name]\java_lib\*";"[location_of_tailerConfig.xml_file]"- The class path to be used by the process.- The first part is the path to configuration files used for the Deephaven environment, such as properties files and the data routing YAML file.
- The second part is the path to the JAR files from the Deephaven server or client install.
- The third part points to the directory containing the configuration XML file the process will need.
-server- Run Java for a server process.-Xmx4g- How much memory to give the process. This example is 4GB, but smaller installations (tailing less files concurrently) will not need this much memory. 4GB will be sufficient for most environments but if a lot of logs are tailed or data throughput is fairly high this may need to be increased.-DConfiguration.rootFile=iris-common.prop- The initial properties file to read. This file can include other files, which must also be in the class path.iris-common.propis the default unified configuration file for Deephaven processes.- It is also possible to specify or override many Tailer settings by including other
-Dentries instead of writing them into the properties file.
-Dworkspace="[instance_root]\[instance_name]\workspaces"- The working directory for the process.-Ddevroot="[instance_root]\[instance_name]\java_lib"- Path to the Deephaven binaries (JARs). Same as the first half of the class path in this example.-Dprocess.name=tailer- The name for this process.-Dservice.name=iris_console- Use stanzas from properties files suitable for a remote client process.-Dlog.tailer.processes=[comma-separated list]- Process names to be found in the Tailer config XML files.-Ddh.config.client.bootstrap="[instance_root]\[instance_name]\dh-config\clients"- specifies where to find configuration server host and port details.-Dintraday.tailerID=1- ID for the Tailer process that must match Tailer instance specific properties from the properties file.com.illumon.iris.logtailer.LogtailerMain- The class to run.
Other properties that could be included, but are often set in the properties file instead:
-Dlog.tailer.enabled.1=true-Dlog.tailer.configs=tailerConfig.xml-DpidFileDirectory=c:/temp/run/illumon
Also, if logging to the console is desired (e.g., when first configuring the process, or troubleshooting), -DLoggerFactory.teeOutput=true will enable log messages to be teed to both the process log file and the console.
Warning
This should not be set to true in a production environment. It will severely impact memory usage and performance.
If the pidFileDirectory is not overridden, the process will expect to find C:\var\run\illumon in which to write a pid file while it is running.
The process will also expect C:\var\log\deephaven\binlogs\pel and C:\var\log\deephaven\binlogs\perflogs to exist at startup. These directories should be created as part of the Tailer setup process.
Automate Tailer execution
There are several options to automate the execution of the LogTailerMain process. Two possibilities are the Windows Task Scheduler or adding the process as a Windows Service.
The Task Scheduler is a Windows feature that can be used to automatically start, stop, and restart tasks. Previous versions of the Tailer process needed to be restarted each day, but current versions can be left running continuously.
An easy way to configure the launch command to run as a Windows Service is to use NSSM (The Non-Sucking Service Manager). This free tool initially uses a command line to create a new service:
The tool will then launch a UI to allow the user to browse to the file to be executed as a service (e.g., runTailer.cmd in this example), and to specify other options like a description for the service, startup type, and the account under which the service should run. Once completed, this will allow the Tailer to be run and managed like any other Windows service.