Deephaven Security and Auditing configuration
This guide provides a conceptual overview of Deephaven's security model, covering the implementation of security at both the operating system level and within the product. It is intended to provide foundational knowledge for administrators and auditors.
For a checklist of specific configuration recommendations, see the Hardening Technical Controls guide. For practical examples of how to query and monitor security events, refer to the Audit Technical Controls guide.
Data and security overview
Deephaven is a time series database that provides rich and efficient analysis of large (billion+ rows per day) historical data sets, and live "ticking" data streams. Deephaven can be installed on Linux servers or as a Helm-managed set of Kubernetes deployments. Its internal storage is append-only, and stores data in regular files in hierarchical directory structures. On-disk data can be stored in a proprietary format with column files or in Parquet files. Deephaven also provides orchestration capabilities for things like ingesting batch data and managing shared queries. Access control within the product is achieved through a robust Access Control List (ACL) system, configurable down to specific columns and rows of data in a table.
The most common level of user access to Deephaven allows a user to read data from specifically granted tables, a sample data set (if installed), and subsets of system data that are applicable to the user. Standard user access also allows users to write data to user tables, which are separate from the typically much larger systems tables. A user table in Deephaven is a bit like a temp table in SQL Server, but a user table is persisted on disk. Regular users can also be granted access to read data from shared queries and access shared dashboards (UI constructs that can include grids of data and charts). Regular users do not have permissions to write or delete data except for user tables and, if configured, special "input" tables, which are a variant of user tables that use row version IDs to allow the appearance of a randomly updatable table.
The typical configuration of Deephaven is with a library of historical data, which might be initially backfilled with batch imports, and one or more sources of streaming data, which can be fed via native Deephaven loggers or Kafka or Solace ingesters. Users who have been granted access to the tables associated with these data sets can then write queries and create dashboards based on the data. Users will, through a variety of APIs (Deephaven Web API, Python client, R client, etc.), launch or connect to one or more workers on Deephaven servers that will do the query processing work. Each worker is a separate Java Virtual Machine process. There are options to limit which servers can be used when launching a worker and configuration settings to limit how much heap a user can allocate when launching a worker. All login/logout, worker launch, and even individual commands executed by the worker are audited or logged.
Deephaven also provides privileged groups for permissions management, schema management for system schemas, and global access to data; it also provides a "view only" group for users who cannot create queries but can only make use of pre-created dashboard content to which they have been granted access.
System accounts and OS security
Deephaven installation requires several users (service accounts) and groups to segment access to OS resources for service and user interactions. These can be created by the Deephaven installation; alternatively, custom accounts created by an administrator before beginning the installation can be used. All of the user and group account names can be changed to custom names during the installation process (the default names are used in this section to refer to the accounts and groups).
Service account users:
| Default name | Purpose |
|---|---|
irisadmin |
|
dbquery |
|
dbmerge |
|
Groups:
| Default name | Purpose |
|---|---|
irisadmin, dbquery, and dbmerge |
|
dbquerygrp |
|
dbmergegrp |
|
All of the Deephaven service account users have no password. They are only used throughsudo`.
Their home directories are under /db/TempFiles. The home directories are used to store some account-specific configuration values and also for scratchpad space for caching dynamically compiled Java classes for workers.
The installation process, or manually prepared prerequisites, will configure the irisadmin account with sudoer rights to manage Deephaven services, run monit, and sudo to dbquery or dbmerge. If the user running the initial installation does not have root access, they must have similar sudo rights to irisadmin.
The list below shows the minimum sudoers rights, with dh_service being the installing user account.
Note that all the sudoers entries specify both user and group that can be sudoed, and that all are NOPASSWD entries, since installer and monit process launch actions cannot prompt for a password - especially for irisadmin acting as dbquery or dbmerge, where irisadmin doesn't have a password to provide.
Dependency service accounts
Besides the three core Deephaven service accounts listed above, there are also some service accounts associated with Deephaven dependencies.
- etcd: The etcd account is used to run the etcd service. etcd is a distributed key/value store used for storing various configuration settings and dynamic state information for the Deephaven cluster. In a simple single-node installation, etcd will be among the services running on the node. In larger clusters, some odd number of nodes will run etcd; for instance, a four-node cluster would probably have three of the nodes running etcd. It is also possible to use an etcd cluster that is running on different servers than the Deephaven installation, in which case none of the Deephaven nodes will have an etcd process or user.
- MySQL: In Deephaven v.20221001 (Jackson) and later, the use of MySQL to store ACL data is optional. Systems that don't use MySQL will instead store ACL data in etcd. It is also possible to use an external (to the cluster) MySQL or MariaDB installation to store ACL data. In the case where etcd ACL storage is not used, and the MySQL or MariaDB process is installed on one of the Deephaven nodes, that node will also have a MySQL account under which the ACL database process will run.
- lighttpd: Lighttpd is a simple Web server process that is used by the
client_update_service(CUS) to host data for installing the Swing "thick" client or synchronizing remote client support files to remote systems. The CUS is optional. In version 20230511 (Vermilion) and later, its functionality has been incorporated into theweb_api_service, and lighttpd is no longer used. In pre-Vermilion clusters that have not disabled the CUS, there will be a lighttpd user account on the node that runs the CUS.
All of the above accounts are no-shell users.
User interaction with Deephaven
Authentication
Authentication of user actions is handled through access tokens which are refreshed each minute. The tokens are issued by the authentication_server process. The authentication_server can be configured to use one or more authentication modules. These include:
localusers- users and credentials stored locally.LDAP- user authentication handled by requesting validation from an LDAP service (e.g., Active Directory or OpenLDAP).SAML/OAUTH2- user authentication handled by an external IDP that supports OAUTH2 protocol (e.g., Okta or Google)..authorizedkeys- allows key-based authentication using a server-side list of authorized public keys.DHADI- allows transparent single sign-on via Active Directory trusted authentication for Windows users.
Background of Deephaven Data Access Mechanisms
Deephaven data is accessible in two main ways: tables and Persistent Queries. Each of these has their own access control system. Both of them share Deephaven user and group management. Users are automatically members of the allusers group, and this group has some default permissions, such as access to the LearnDeephaven namespace, which contains example tables and data.
Table ACLs
Table Access Control Lists allow Deephaven groups and users to be granted access to individual tables or wildcard sets of tables.
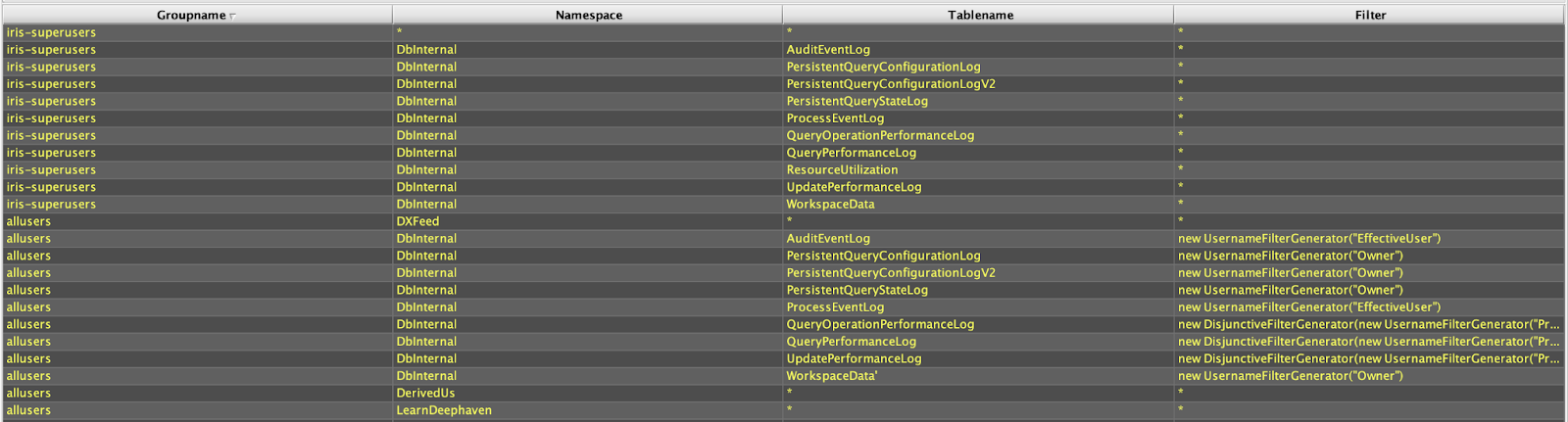
The screenshot above (from the ACL Editor utility in the Deephaven Swing client) shows default Table ACLs that exist in Deephaven. The iris-superusers group has explicit rights to all data in all of the internal "DbInternal" tables, but also has a wildcarded right to all data in all tables that already exist or that might be added later (*,*,* permissions). The allusers group, on the other hand, has full access to example tables in the LearnDeephaven namespace, and filtered access to data in other DbInternal tables. The use of an ACL filter object instead of * in the filter column indicates that row data from the table will be filtered, so regular users will only see some of the data in these tables. The DXFeed and DerivedUs permissions are custom ACLs that were added after installation.
Persistent Query Access Control
Persistent Queries (PQs) have their own access control which can be independent of Table ACLs. The PQ creator/owner must have access to underlying tables to use them in the query, and then the creator/owner can delegate access to the query to other users. In this respect, PQs provide a mechanism that can be similar to rights that can be granted to a SQL view. However, the query creator can also go further and apply new permissions to the tables created within the query. Alternatively, if the PQ is a parameterized PQ, the query creator can choose which data to retrieve using their own permissions versus data that should be retrieved using the permissions of the user accessing the query.
Run As
Run As, also known as Per-User Workers, allows an administrator to configure individual user accounts to run workers as a specific user account rather than as the shared dbquery or dbmerge account (see above for more details on these default run-as accounts). When a user's account is configured to run workers as a system user, the permissions assigned to that system account can be used to control access to specific tables or subsets of tables, as well as providing the user with more granular additional permissions, such as rights to write to specific tables, but not all tables.
Auditing
Deephaven processes log their activities to a set of tables in the DbInternal namespace. The primary table for this is AuditEventLog. This table records details of user connections and disconnections, access to tables through direct queries or PQs, configuration changes, and other security-related events. For specific queries and examples, see the Audit Technical Controls guide.
General activity auditing
Authentication process details are logged to the Deephaven authentication server log (/var/log/deephaven/authentication_server/AuthenticationServer.log.yyyy-MM-dd-hhmmss.nnn-TZ). All authentication events, successful or unsuccessful, will be logged to these text files, with a link from AuthenticationServer.log.current pointing to the currently active log file. Usually, the bulk of activity in this log is for renewals of access tokens, which take place each minute that a connection is active.
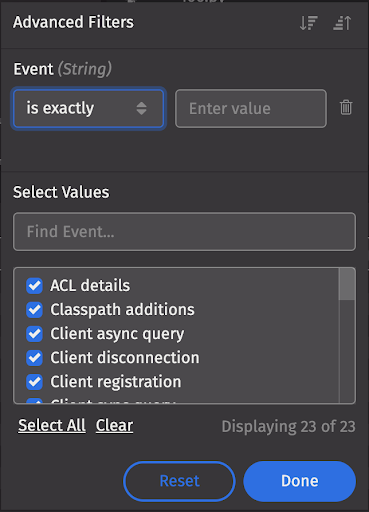
Once authenticated, user activity within Deephaven is audited to the DbInternal.AuditEventLog table. This table includes activities like configuration changes, launching and terminating workers, permissions checks, schema modifications, and other privileged activities and inter-process activities. The Event and Process columns provide good filtering options to select events of interest:
Data access auditing
The DbInternal.AuditEventLog table provides data access audit events, both for access to tables and for access to PQs. Data access events will generally have rows where the Process value is worker_n; worker processes are those that back Persistent Queries, query consoles, and remote clients that are actually accessing data. Most events logged from worker processes will be related to data access and include details about the user, table, and namespace being accessed. More detailed information about queries and scripts being executed are logged to the DbInternal.ProcessEventLog. This log captures all activities and errors/exceptions raised within worker execution.
Because Persistent Queries can construct entirely new tables as well as present or derive data from existing tables, it would be a complex process to analyze PQ definitions and permissions to infer what access to underlying data is granted through them. Actual access to underlying tables through Persistent Queries is audited, however, so a presentation of what tables were accessed, by whom, and when, can be easily constructed. This audits at the table level, though, and not to particular values within the table. On the other hand, it is possible, using parameterized PQs, to use the table access permissions of the user executing the query, rather than those of the user that created the query. In this case, data access will be limited and filtered, including row and/or column filters that apply to the user.
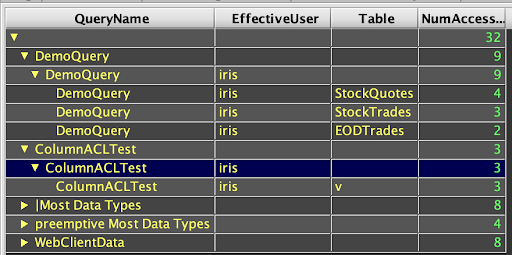
Queries and reports using data from this table can show who is accessing which tables, when, how often, and through what mechanisms (direct queries, PQs, etc). This example rollup table shows user accesses to Persistent Queries, and is opened to drill down into details such as the specific tables accessed through the queries:
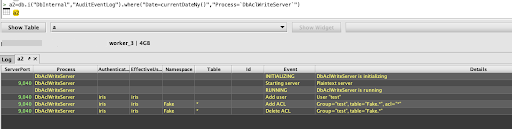
The AuditEventLog also records account and account permissions changes. These are logged by the DbAclWriteServer process. Querying this table can be used to produce a history of entitlement changes along with details of which users made the changes.
Additional data access details are available from the ProcessEventLog table. This table is an unstructured log of Deephaven system activity. Among the activities logged to it are the text of individual queries.
Analysis of table-based access to specific data
Deephaven's APIs, such as those related to DbAclProvider, enable detailed inspection of access control configurations. Administrators or auditors can programmatically retrieve information about users, groups, and their effective permissions on tables. This capability is crucial for:
- Generating reports on user/group access to specific tables or data subsets (especially where row/column filters are applied).
- Verifying that permissions align with intended security policies.
- Automating parts of the access review process.
For practical examples and scripts on how to perform such analysis, refer to the Audit Technical Controls guide.
Configuration management
Deephaven employs a layered and scoped configuration system, primarily managed through property sets stored in etcd. This system allows for default settings, environment-specific overrides, and process/server-specific configurations. Key aspects include:
- Layered Properties: Configuration files like
iris-defaults.prop,iris-environment.prop, andiris-endpoints.propare loaded in a specific order, allowing for overrides. - Scoped Stanzas: Configurations can be applied to specific services or servers.
- Security-Related Settings: Many security parameters, including authentication methods, audit logging levels, and TLS/SSL settings, are managed via this system.
- Credential Management: Secure storage and access control for credentials used by Deephaven services (e.g., for etcd, internal logins) are integral to the configuration.
- TLS/SSL: Deephaven uses TLS/SSL for secure communication, relying on certificates and keys managed within its configuration and truststore/keystore mechanisms.
For detailed information on the configuration system, property files, specific security settings, tools like property_inspector, and management of certificates and credentials, refer to the Configuration overview and the Hardening Technical Controls guide.
Replication of security files
Ensuring that security-related files (e.g., private keys, truststores, credentials) are securely distributed and synchronized across all nodes in a Deephaven cluster is critical. Deephaven provides mechanisms and tools for this, differing slightly between Kubernetes and non-Kubernetes deployments:
- Kubernetes: Security files are typically managed via read-only volumes attached to relevant pods.
- Non-Kubernetes: Utilities like
config_packager.share used to package and distribute necessary credentials and configuration files to target machines.
For specific procedures on securely managing and replicating these files, consult the Hardening Technical Controls guide.
Networking
Understanding the communication pathways and network ports used by Deephaven services is crucial for configuring firewalls and ensuring secure network segmentation. Deephaven services use a mix of proprietary TCP-based protocols for older interfaces, and GRPC for newer interfaces, for their interprocess communications. The core documentation provides details of the different services and the default ports or port ranges they use. All ports and ranges can be modified in Deephaven configuration properties.
Communications between Deephaven clients, including the Web UI, and Deephaven Worker processes and infrastructure services also happen over these ports, port ranges, and protocols.
The easiest way to limit the exposed ports and allowed endpoints is by configuring the Envoy reverse proxy. This allows all client communications to Deephaven from outside the cluster to be directed through a single Envoy port, which is 8000 by default. Within the Deephaven cluster, fairly open communications are still required because Envoy, which is usually running on one of the cluster nodes, will need to be able to create connections to services and workers running on other nodes of the cluster and on a variety of ports.
Besides client communications, a Deephaven cluster may require connectivity to other systems for NFS storage, Kafka data and schema connections, Solace connections, and connections to other data streams, including, potentially, incoming data stream connections to a tailer port on the node running the main Data Import Server (DIS). The default DIS tailer port is 22021; this is configurable in the routing.yaml file.
Technical controls
The related guides Audit technical controls and Hardening technical controls provide details on specific audit data sources within Deephaven and configuration recommendations for a secure environment.