Build with custom real-time data sources
Ingest and combine data programmatically using highly-flexible input tables
February 28 2022


Dynamic data comes from a variety of sources. Working with that data in real time opens many opportunities for analytics and applications. In modern systems, well-known protocols like Kafka are important, but so, too, are your custom sources. In many cases you may want to stream data from applications without hooking up Kafka.
Deephaven is a data engine that 'just works' with streaming tables -- essentially tables that can update every so often or change quickly in real time. In the deephaven-core product, we recently released a building block called an "input table". It's designed to accommodate a large range of custom data sources that interest you. For example, you'll be able to ingest in real time:
- A 3rd party data feed ✓
- An IOT device producing weather data ✓
- Outputs from a user interface that can then communicate with your backend ✓
Those are simply a few possibilities.
Deephaven input tables offer a powerful, flexible, and easy API to add your own dynamic data sources. The input table API is exposed over gRPC.
This blog demonstrates the feature's use in a remote Java client, but input tables can also be enabled directly from the server (via Application Mode) or via a script session in the web IDE. The examples below could readily be adapted to work with the JS client, or (in the future) with the Python or C++ client (or, any other language with gRPC support).
Once you've added your input table integration, you can use all the powerful features that Deephaven tables inherit: joining, filtering, sorting, manipulating, grouping, aggregating, embedding Python functions, and much more. They become just another source table in the directed acyclic graph of your live, updating query.
Types
An input table is a live, updating table where data can be added programmatically. Conceptually, it's similar to an SQL INSERT or MERGE statement; but as you'll see, it services use-cases well-suited to Deephaven's streaming core competencies.
There are currently two types of input tables:
-
An append-only input table. These input tables append all new rows to the end of the table. They are suitable for use cases where a full history of updates is needed. For example, an event-sourced audit log, an IOT event stream, or a social media feed.
-
A key-backed input table. These input tables have key-columns (zero or more). A new row is appended if the key is new, and an existing row is updated if the key already exists. (It is also possible to delete rows based on the key.) These are suitable for use-cases where (i) there is an important key associated with the data, and (ii) the full history of updates is not needed. A top-of-book price feed keyed by the symbol name, the current weather keyed by city name, or the live score of a baseball game keyed by the team names are all relevant examples. It's also possible to have an empty key (zero columns); for example, the state of a single light switch.
Create Input Table Request
A remote client can create an input table with a Create Input Table Request RPC. The most important part is the definition, which may be specified by an Arrow Schema (which describes column names and types), or by referencing the definition of an existing table. For the key-backed input table, the key-columns are also important.
The Java client has InMemoryAppendOnlyInputTable and InMemoryKeyBackedInputTable classes to represent each respective type of input table.
Here is an example creating an append-only input table named audit_log from the Java client:
Here is an example creating a key-backed input table named city_weather from the Java client:
After executing the above, you should be able to see the (empty) tables in the web UI "Panels" dropdown, typically available at http://localhost:10000/ide/.
The full runnable source code for these examples is available at the Deephaven Examples input tables repository.
Add Table Request
Once you've created an input table, you'll likely want to add data to it. A remote client can add to an input table with the Add Table Request RPC. The table data is exported to the server via an Arrow Flight DoPut RPC, then added to the input table created earlier.
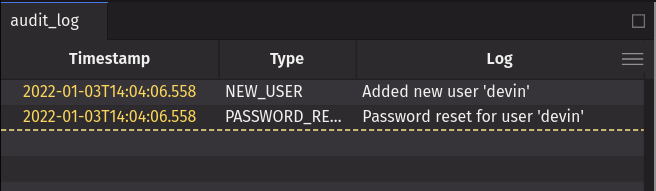
For example, to add new rows to the audit_log input table from the Java client, you can execute:
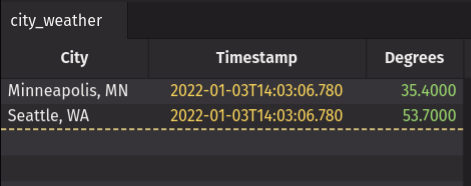
To add, or update, rows in the city_weather input table from the Java client, you can execute:
After executing the above, the tables in the web UI will show that the data has been added successfully.
Integrations
The above examples are purposefully minimal to isolate the core concepts of (i) creating an input table, then (ii) adding to it. Of course, the nature of APIs is that they can be integrated with other systems. This simple example invocation with static example data can easily be extended to a real-world integration, sourcing data programmatically, potentially even at high velocity. The audit_log could be integrated as the sink for a real application's audit log; city_weather could be integrated with a real weather API.
The Deephaven input table APIs present a low barrier of entry into the Deephaven streaming ecosystem.
I'm excited about the plethora of use cases for input table integrations.
- IOT devices producing data can use input tables and Deephaven to drive home automation.
- Input tables can serve as a communication layer between GUIs and backend application processes.
- Sports insiders can create new client experiences by using input tables and Deephaven to manipulate fine grained play-by-play details to delight fans in real time.
- Blockchain data can drive (non-blockchain) applications to facilitate analytics and experiences.
- Quick POCs can be developed for health care telemetry.
Related concepts
Input tables are not the only way to present dynamic data to Deephaven. Among other methods, Kafka streams are often used to get real-time data into live Deephaven tables. This is particularly useful for systems with established Kafka infrastructure. In such cases, the Deephaven server acts as a consumer to a Kafka server, and either/both the Deephaven server and/or the remote clients act as a producer to the Kafka server using the Kafka APIs.
Source code
The source code for the examples above is available at deephaven-examples/input-tables. It has full runnable examples that provide the setup and context for creating and adding to input tables from a remote client. It also has other examples beyond those demonstrated above.
Upcoming features
- Input Table API - Python client #1608
- Input Table API - C# client #1609
- "One-shot" stream input table #1610