Release Notes for Deephaven Versions 0.21.0, 0.22.0, & 0.23.0
An avalanche of new Deephaven features and integrations
April 17 2023

The Deephaven team has extended its stack to make real-time analytics and apps easy to build, share, use, and integrate.
Highlights of recent releases include new SQL database integrations, accelerated vector handling and Python gems, deepened integration with Apache Arrow, window- and rolling aggregations, increased intra-engine parallelism, authentication hooks, and UI/UX niceties. Notes for the 0.21.0, 0.22.0, and 0.23.0 releases can be found on GitHub.
SQL Database integrations
Since Deephaven enables you to work with static and streaming data simultaneously, your use cases may involve sourcing data from a SQL database. Java users have long had a JDBC integration available, but there are now many options available from Python.
The Arrow community is investing in development at the intersection of Arrow tables and SQL databases, so Deephaven works to interoperate with that new tech while also supporting other ODBC access. Accordingly, we now support several Python methods for accessing databases. In each case, you will pass connection information (like username and password) and a SQL query to the source:
- read_sql: This is a high-level interface that allows you to choose from three available drivers:
- ConnectorX. (This the default.)
- Turbodbc
- ADBC
- adbc.read_cursor: If you want to customize your database access further, Deephaven makes available a lower-level interface to Arrow’s new (and promising) ADBC library. With this integration, you can use ADBC for connections not just to Postgres and SQLite, but also to Flight-SQL, which opens up many other databases to users.
- odbc.read_cursor: A lower-level integration that provides a Turbodbc cursor similar to that of ADBC.
The Deephaven team will continue to invest in bringing SQL and Python workflows together. We are tracking Substrait’s progress, as its mission may advantage our users, and in the 0.24.0 release, the engine will support server-side SQL in Deephaven. At that time, users can use SQL within Deephaven workflows directly, inheriting results for both static and dynamic, ticking tables.
We hope you agree that real-time SQL in an environment with easy real-time Python (and Java) is exciting.
More Arrow-related niceties
The Deephaven API, Barrage, is an extension of Arrow’s gRPC-based Flight protocol, and we’re committed to architectural alignment. As an example, we just released:
Support for Arrow Flight authentication for Deephaven clients. Here is a description of our approach. The team is now working to plumb this through to the Web UI.
Read and write integrations with Persistent Arrow file formats (aka “Feather). The wrapper tools invariably delivering this capability also set Deephaven up to soon support in-memory Arrow tables.
We’d love to hear from you about the relative importance of having Arrow wrapper tools available to your workloads.
Server- and client-side Python love
The Python client API is a powerful beast. It now both supports bidirectional streaming (yes, clients receive and send real-time Streaming Table data) and is both syntactically consistent and has similar coverage with Deephaven’s Server-side Python.
The team has continued to wrap table operations to ensure Python users have easy access to all the engine’s capabilities. Now users can incorporate full_outer_join(),left_outer_join(), tree table, rollup(), and flatten() into their applications, analytics, and models.
Vector performance within Python functions has been greatly improved. The team overhauled the functional interfaces and introduced new primitive and closeable iterators, making vector operations fast (even as arrays update in real time).
Window-based aggregations in a big way
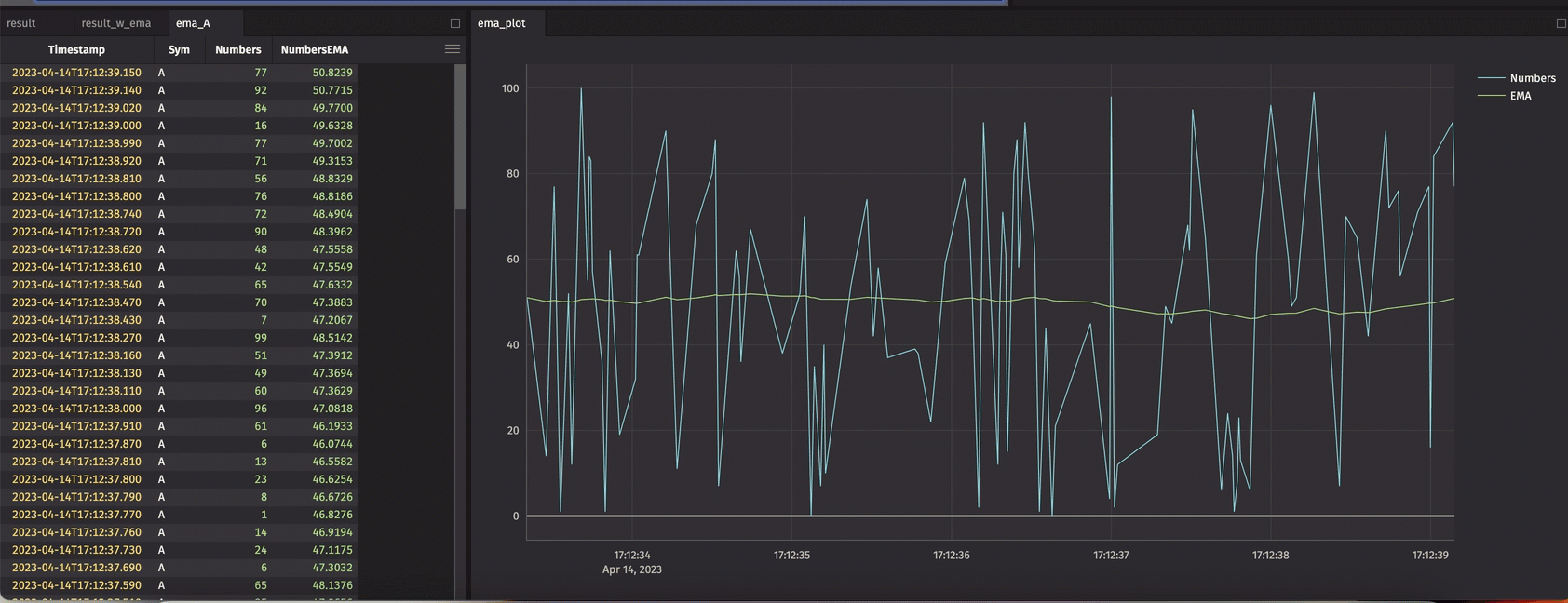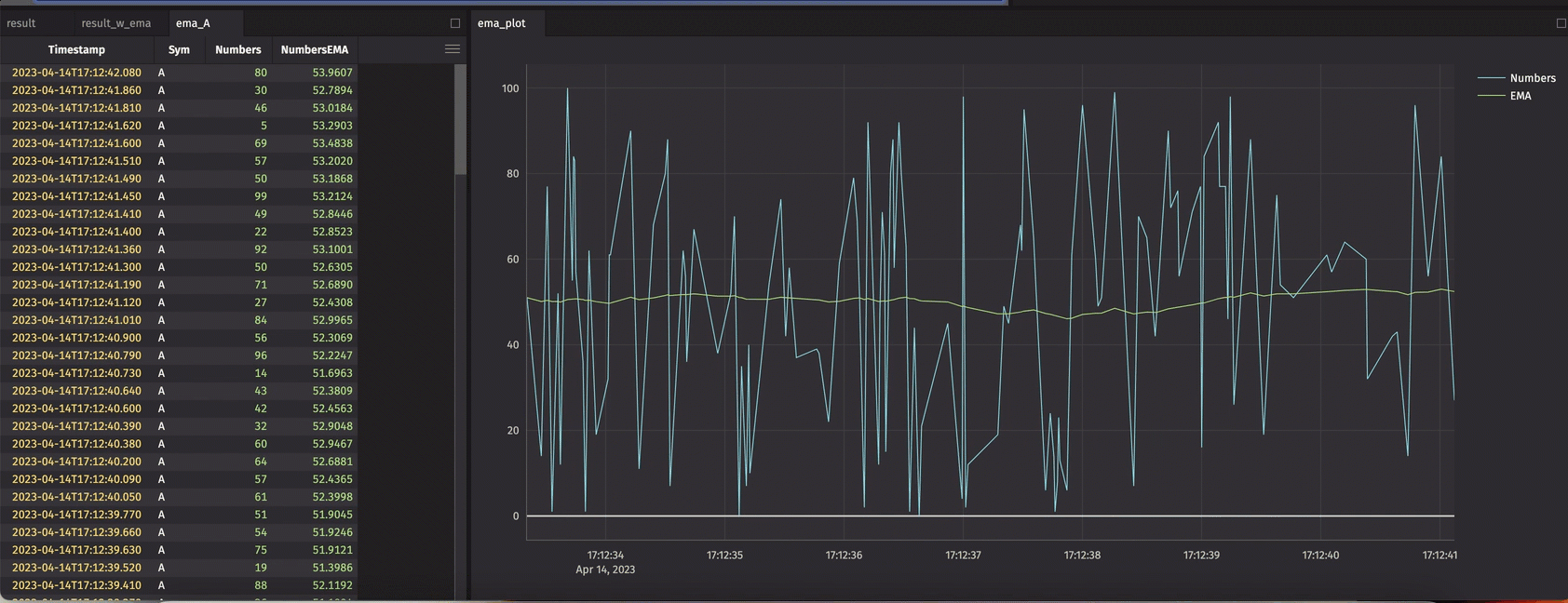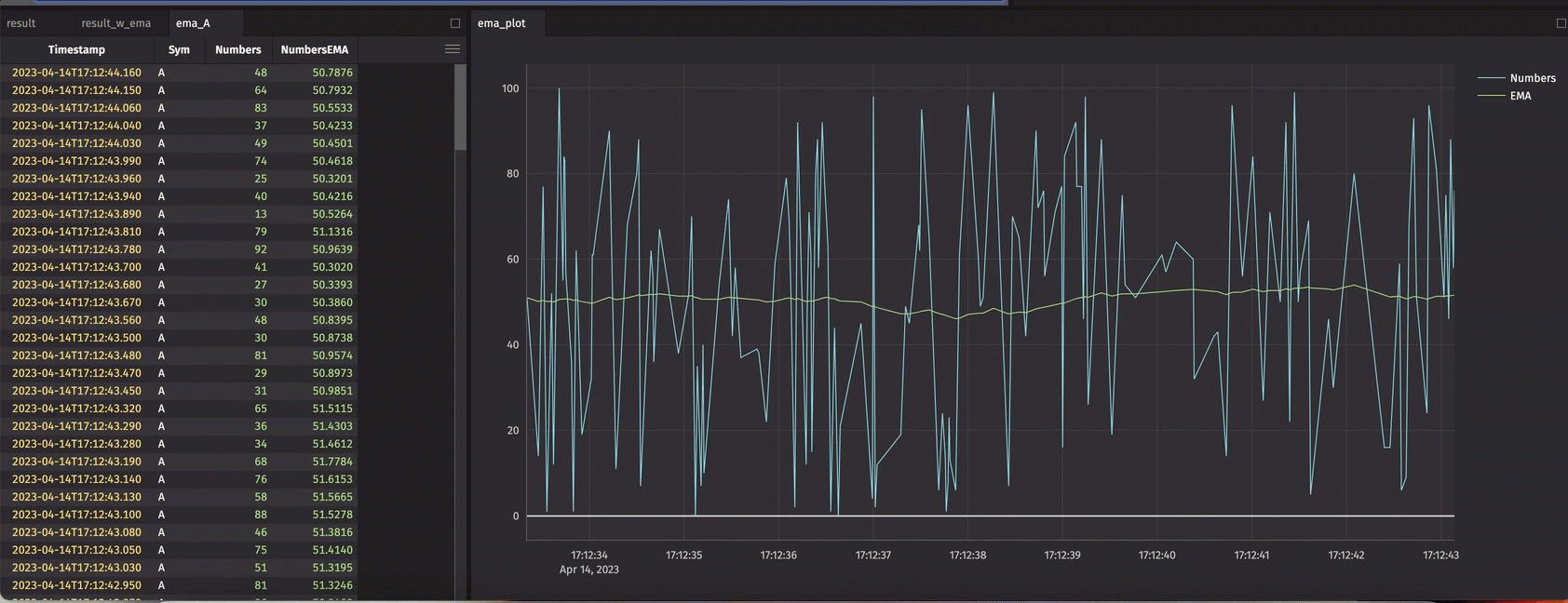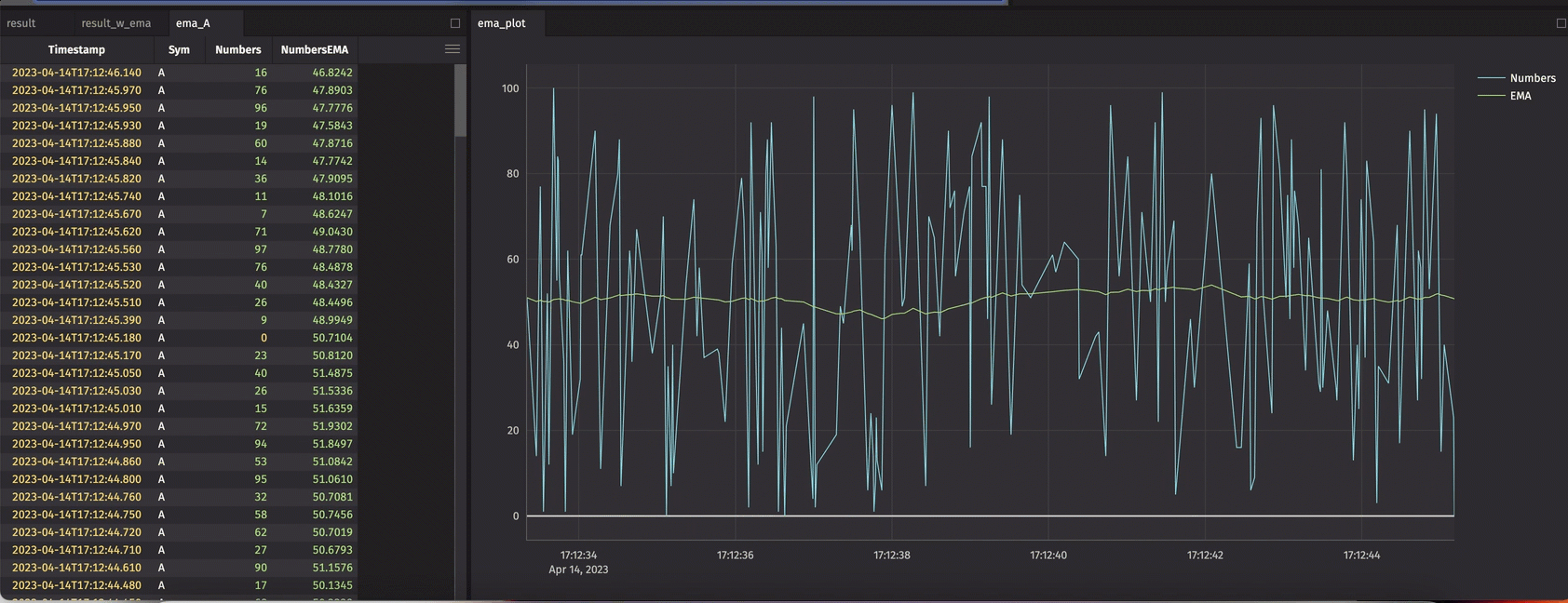
The crew has put significant effort into delivering the update_by() operation and its derivatives. This method can be used to create new columns in a table based on window-based aggregations – using keys or not.
Use cases in this space are rich. Cumulative, rolling, and window-based grouping are all supported. Cumulative sums, EMAs, row count, and time-driven mins, maxes, and products are just a few examples.
A Deephaven developer demos it here:
update_byis available to Python and Java users, and has been integrated into the client APIs as well.- Grouping within this
update_byoperation delivers arrays. This pairs nicely with the performance improvements to handling vectors in functions, as noted above. - Here is a list of all the aggregation operations currently supported. Again, think cumulative, rolling, and windowed methods.
The example below demonstrates its use in calculating an EMA.
Usability and performance joy
Community users have requested some enhancements that make Deephaven even easier to use.
- Autocomplete and Pydoc integration in Deephaven’s Web IDE had a massive upgrade. In the editor, you now not only receive prompts for symbols as you type, but the respective docstrings for the suggested items are available in-line. Further, parameter help is available right there for function calls. Both these are supported as you hover on text as well.
- Deephaven users rely heavily on Parquet for static data. Now read.parquet supports a boolean for is_refreshing. If set to
true, as the source directory inherits new Parquet data, the in-engine Deephaven tables will immediately ingest the new partitions. This de facto provides real-time batch updates – pretty slick.
Those two features can be seen back-to-back in this video:
-
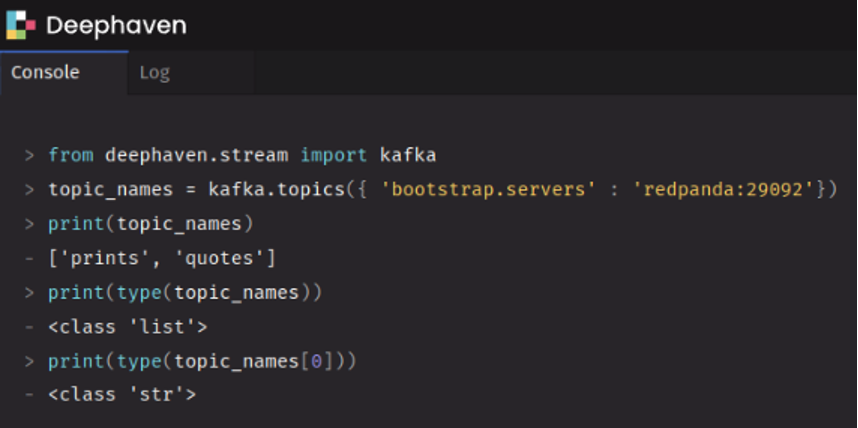
You can now query for available Kafka topics from the Deephaven editor. The simple script below will deliver a list of strings of topic names.
-
The Deephaven engine is now parallelizing many processes for you. Think “speed” here. This happens in two ways:
- Intra-query: For DAG nodes with no upstream dependencies, calculations can be addressed on different threads simultaneously within a single update-graph-cycle.
- Specific operations are now proactively multi-threaded: select,update, partitioned_table, and
update_byare the headliners here.
-
A “go-to” experience in the UX of a table now allows you to hop to a cell you have in mind without filtering. Under the hood, the JavaScript team plumbed through the engine’s seekRow capabilities.
-
Browsers now recover elegantly if they reconnect.
Looking forward
The April release will be headlined by...
- Server-side SQL! It will support our updating-table model (real-time SQL!) and be a big deal in every way.
- A huge upgrade to our plotly integration, so users can control the layout of figures and inherit many more plotly plots ticking in rea time.
- A new
range_joinfunction that allows time-series joins that grab a window of qualified rows from a right-side table. We know many users are excited about this one.
The team is also investing in expanding documentation and is beginning to work on an R client.
We look forward to interacting with you via Deephaven’s Slack or GitHub Discussions.