Skill evals for measurable agent self-improvement
Customizing claude skill-creator for iterative skill development
May 29 2026


Skills are re-usable markdown instructions that teach agents how to accomplish specific tasks. But how do you measure whether your instructions actually help agents complete the task — rather than just add noise — especially given that agents are non-deterministic? The answer is to evaluate behaviour in aggregate across many runs, a practice the AI community calls "evals".
At Deephaven, we have a public skill deephaven-core-query-writing that helps agents to write real-time Deephaven queries and build dashboards with live data. The following article discusses how we use evals to measure skill performance, and how we iteratively improve our skill using agent-driven recommendations.
How do you measure whether your instructions actually help agents — rather than just add noise?
Note
These skills are in early development and may give incomplete or inaccurate recommendations to agents. Feedback and contributions are welcome to help improve these skills. The skills include guidance for general Deephaven query writing, joins, aggregations, update_by, time ops, ui, plotting, and CSV importing.
What to measure
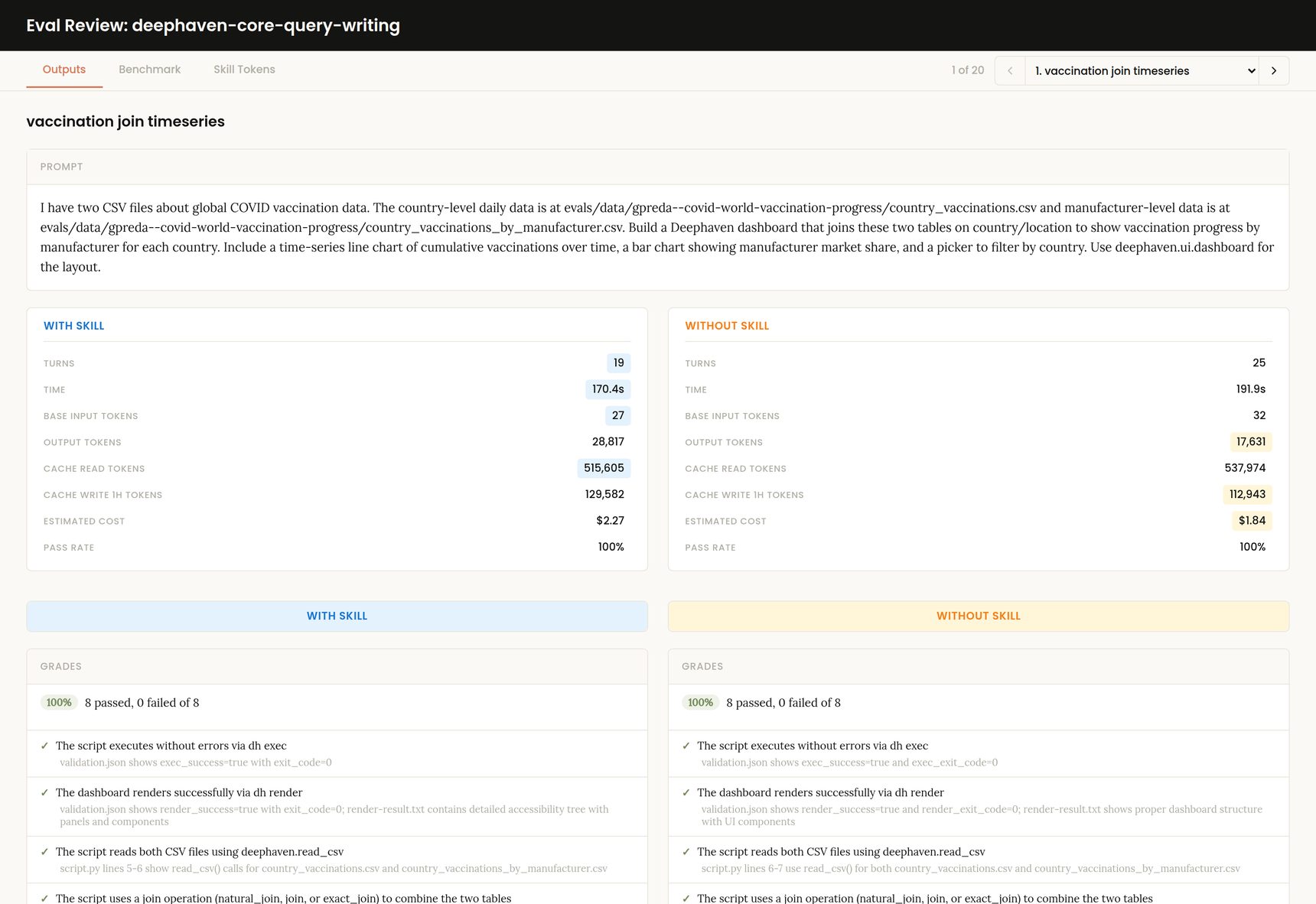
Evals can be written for a variety of purposes (from tracking accuracy to making sure updates don't break things). The first step to writing good evals is to determine what you intend to measure. In our case, my primary goal is to compare the success rate of an agent writing functional deephaven code with and without our skill.
However, simply measuring the pass rate doesn’t give the full picture. Generally, one of the most successful ways to leverage coding agents is to include a feedback loop in your prompts so agents can iteratively work towards a goal and measure whether they have achieved it. If we give both our “with skill” and “without skill” agents the ability to iteratively run queries towards a goal, the latest SOTA models may both succeed. In that case, the question becomes how do we decide who did it better? That’s where measuring additional metrics like time taken, tokens used, estimated cost, and number of turns helps, beyond just pass rate.
Building a test harness
The way we’ve set up our test harness specifically for with vs without skills was aided by the Claude skill-creator skill release. We were already testing our skills before its release, but we have since borrowed some of its report-generation features. Consider this a playbook for vibe coding your way through building your own harness.
We start by constructing a set of prompts that represent our “evals”, which are representative tasks that users may try to accomplish with our skills, and then add expectations that represent how we measure conformance towards a pass rate. For us, that involves trying to perform some level of analysis on data (we use the 20 most popular CSV files on kaggle), writing Deephaven queries against that data, and then producing a dashboard. Deephaven is primarily used for real-time data, but for testing, simply using static CSV data keeps it more repeatable. Using real-world datasets ensures we have representative coverage of the data types one might encounter in the wild.
A single eval might look something like this:
Collectively, the prompt and expectations represent our evals. We repeat this pattern across a variety of datasets and prompts to produce a set of evals. Each eval is then inserted into a template that includes generic tooling instructions to provide a feedback loop, such as how to run Deephaven code, how to get table output and exit codes, how to view the dashboard, file paths, and where to place output. The prompt represents the goal given to the agent. For the “with skill” eval runs, they are forced to read the skills entry point file. For the "without skill” run, they do not have access to the skill files and must rely on the model's inherent knowledge of Deephaven query writing.
The expectations are not provided to the agent and are used to assess the agent's work afterward. Expectations are simple statements that can be either deterministically graded (e.g., executes the query with exit code 0) or LLM-graded (e.g., the dashboard includes aggregated statistics, such as average grades by alcohol level). In our case, we used a combination of the two.
Capturing output for grading
The output of your evals is the work product. For each eval, we capture:
script.pywritten by the agent- the last exit code of the execution
- an accessibility tree of the rendered dashboard
- a screenshot
- the full conversation log of the agent session
We create a folder for each run of the eval set, and within that is a folder for each individual eval run containing its output.
We also record model details (ex. Opus, Sonnet), model effort, wall clock time of each agent session, and the total skills token count at time of the run. This is useful for referring back between runs later.
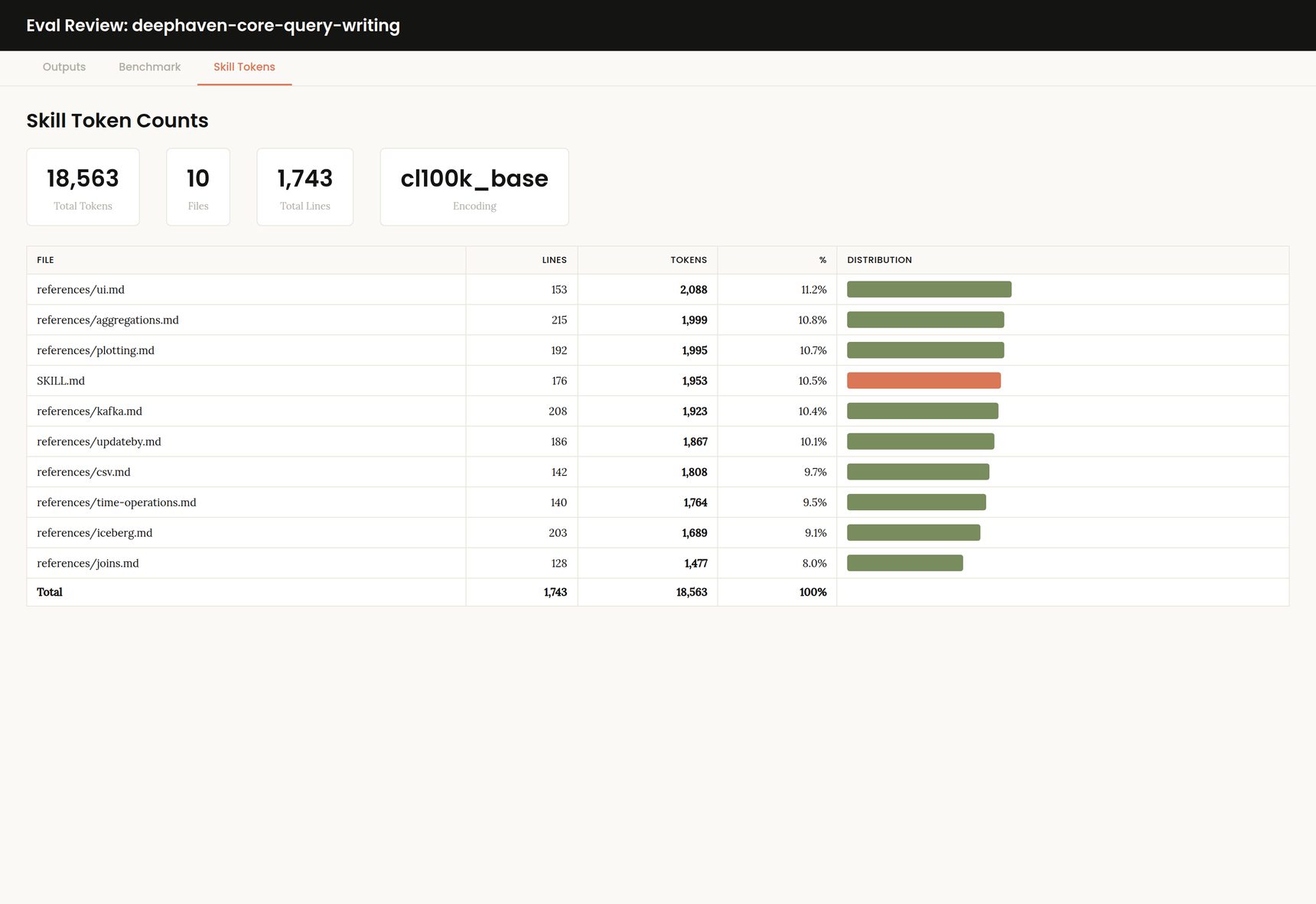
Capturing the conversation logs
For our evals, we are running using a headless Claude agent. For each run, we copy the JSONL of the session log. This is important for self-reflection later. While iteratively developing, having a large catalog of past runs can help agents dig into specific, commonly encountered failure points. It can also be useful to allow humans to scan the logs to make sure no unexpected failures occur due to configuration issues. For example, because we use a team plan, my agents automatically inherited access to certain MCP servers, which allowed headless agents to cheat and search our docs, despite the MCP not being manually installed. This was unexpected and required a specific flag to disable, but would never have been discovered if it weren’t for manual log review.
Session logs also contain detailed token usage throughout the session, including input, output, and cached tokens, so capturing the logs provides lots of value.
Grading
After each eval run, an independent agent has instructions to grade the expectations. It is given access to the work output (script, rendered output, etc) and the expectations and returns a structured JSON answer that is either pass or fail for each eval's expectation. Agents seem to be reasonably okay judges, given specific criteria. Agents must also give reasoning behind the pass/fail in the form of a single sentence citing evidence. This can help you debug incorrect passes or failures to narrow or refine your expectations. LLMs grading their own work can be imperfect, but in aggregate can still produce meaningful results.
Agent recommendations
This is where the fun begins. Another independent agent takes the grading, the output, the conversation history, and the skill files, and is given an instruction to analyze why it failed. What was missing from the skill files? Where did it stumble or have to spend additional iterations along the way to producing a result? It creates a simple markdown report with recommendations of what worked and what didn’t for each eval.
After all recommendations complete per eval, yet another agent is given all the summaries and produces a final summary report of common failures across evals. These recommendations can then be used to iteratively improve the skills.
Summary stats
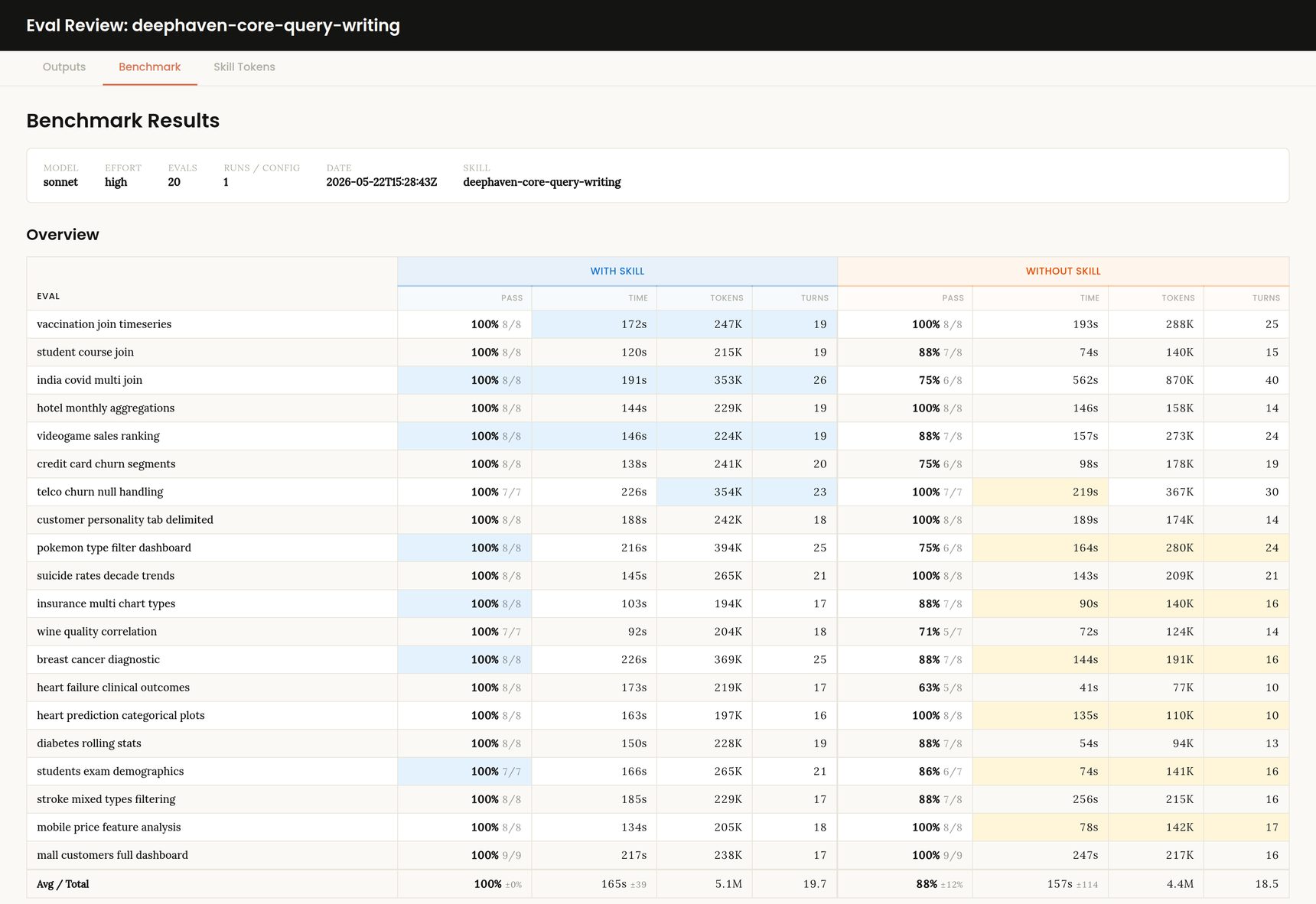
Alongside the grading, a Python script walks through the session logs and pulls out the metrics we actually care about for each run. Token usage is broken out into input, output, and cached, since cached tokens are billed differently and the with-skill runs lean heavily on caching. The script also records the turn count, wall-clock time, the model and effort used, and the exit code of the final script execution. These are joined back to the grading results so that every eval has both a pass/fail breakdown and the cost to get there.
The aggregation step then combines this into a single table per run, comparing with-skill and without-skill side by side. While useful in aggregate, in practice we end up looking at the per-eval breakdown more than the overall average, because a single runaway eval that hits the turn limit can drag the average down significantly, even when the median experience is fine.
How it's run
A single Python script runs each stage in sequence. The script:
- spins up the agent against an eval,
- captures its output,
- validates that the output is real working code,
- parses the session log for metrics,
- grades against the expectations,
- generates recommendations,
- and then aggregates everything into a report.
Since each eval is independent, they can be run in parallel to save time, with only the later stages requiring all evals to be complete first.
We use Claude in headless mode (claude -p) for agent runs. The main reason is that it writes a complete session log to disk, which we can later parse for token counts, the model used, the number of turns, and the full transcript. The same pipeline could be pointed at any headless coding agent that produces a parseable log, and future explorations will involve testing against Codex and Antigravity.
Note: Claude recently changed to API-billed instead of a plan, so we may change this approach.
Iterative loop
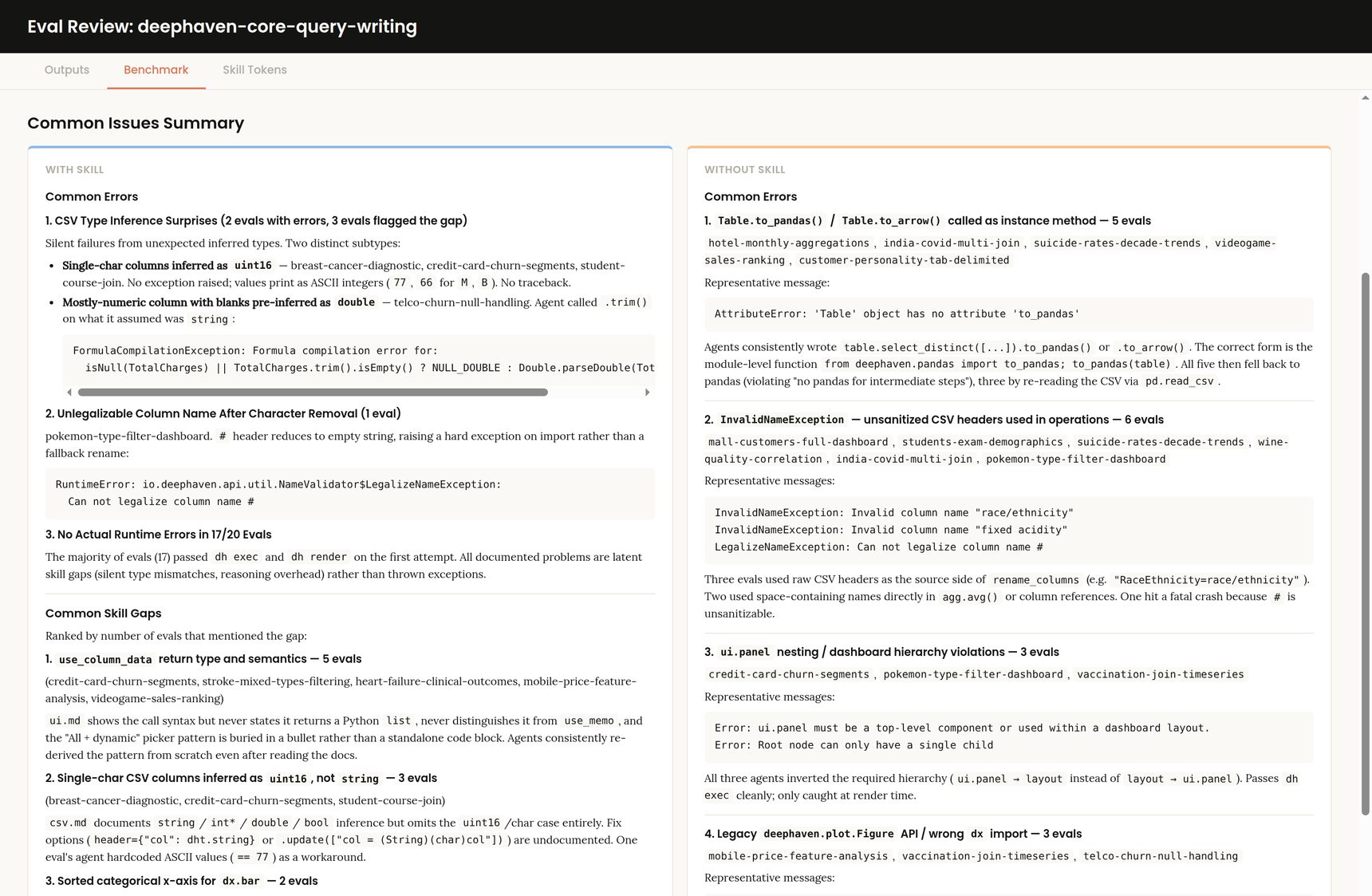
Once the harness is in place, the interesting question isn't really whether it works, but what you do with the recommendations. In practice, the loop looks like this: Run the evals, open the report, read the per-eval recommendations alongside the dashboard screenshots and generated scripts, and then decide as a human what's worth changing in the skill. Usually, only one or two recommendations across the whole batch are worth acting on. The rest are either too specific, already covered, or pointing at a failure that has nothing to do with the skill content.
The recommendations tend to be too specific by default. An agent that just watched a single eval stumble will happily suggest "add an example of joining a CSV-loaded table to a Kafka stream with a timestamp tolerance". That might fix the one eval and add a few hundred tokens to the input cost of every agent forever. The human job in the loop is to translate specific failures into general lessons.
Karpathy loop
I wanted to try to remove the human from this loop using an autoresearch-based approach. Run the evals, generate the recommendations, have an agent edit the skill files, run the evals again, repeat.
It didn't work. I suspect this is for two reasons that compound elsewhere, too.
- The recommendation step has a strong bias toward adding rather than removing. Asking an agent what's missing after a partial failure almost never returns "nothing, this failure isn't about the skill", even when that would be the right answer. The recommendation agents are also more likely to output additional suggestions than to say there are no further changes needed, which feeds the same direction.
- My loop step had no real sense of the token budget. It dutifully appends every suggestion, and the next round's recommendations then point at the new failure modes introduced by the now-larger skill. Within a few iterations, the skill had grown considerably, and the pass rate hadn't meaningfully moved.
The thing I took away from this is that improving a skill is a multi-objective optimization (pass rate up, token count down, complexity down). I wasn’t able to successfully get an agent to optimize across multiple constraints.
There might be a version of this that works with a more carefully constructed recommendation prompt, but for now human review seems best.
An aside “rendering” dashboards to text
It is worth a quick aside on what makes the validation half of all this practical. Earlier versions of the harness validated dashboards by having the agent write a Playwright test, run it, parse the output, and debug DOM selectors when things didn't line up. A meaningful share of agent turns went into the test-writing loop, rather than the task we actually cared about.
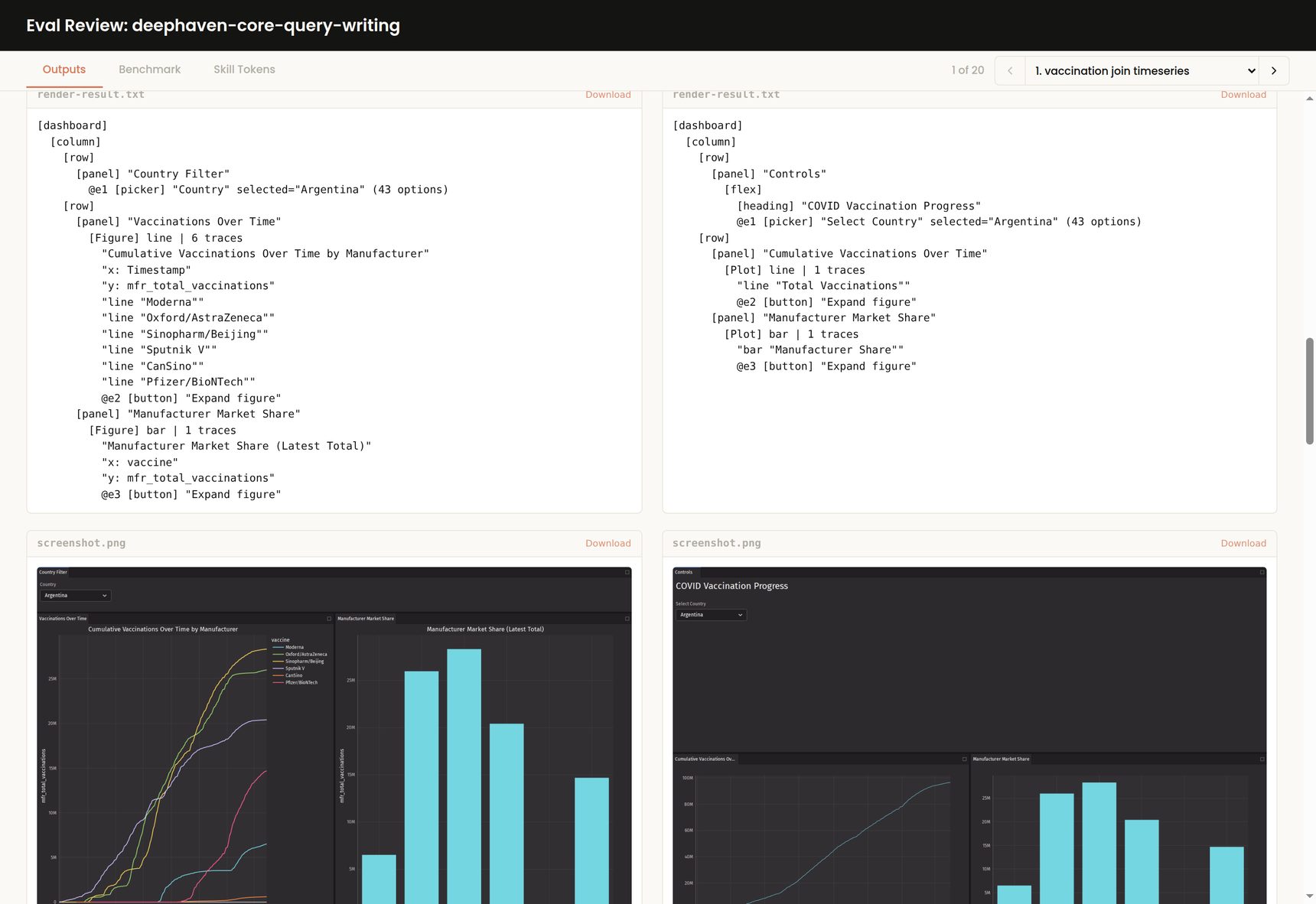
What replaced it is a small CLI we built for headlessly rendering Deephaven UI components as a text tree, and chaining interactions against them (clicks, selections, snapshots of the rendered accessibility tree, and runtime error diagnosis). From the harness's point of view, it is a single command that returns either "the dashboard rendered and looks like this" or "it broke and here's why". The grading agent works directly off this modified accessibility tree, which is structured enough to answer questions like "does this dashboard have a picker" or "is there a scatter plot" without ever touching a real browser. Screenshots still get taken for the human-facing review page, but no grading depends on pixels.
This made iteration loops significantly faster and easier, as it no longer needed to write custom Playwright code or use slow browser interaction. If validation requires a generated test for every eval, you’ll spend most of your eval's time debugging the test harness instead of the skill.
Results
The headline result from the most recent runs is that the skill produces better looking dashboards, with fewer errors, and takes less time to do so. This comes at the expense of slightly higher token usage due to reading skill files, and carrying that token weight through the conversation. However, I think for a user trying to iteratively refine a dashboard, actual token usage will likely be dramatically lower than without the skill.
What is more interesting than the average is the shape of the per-eval results. Most evals pass at or near 100% in both configurations, because the underlying model already knows enough Deephaven from training to handle the basic shape of a query. The skill earns its keep on a small number of evals that consistently fail without it, typically the ones that lean on specific join semantics, less common UI components, or behaviors where the natural-sounding API isn't the one that actually works.
I also had a few incidental findings from running the same evals across different models. With a tight feedback loop in place (error output, render results, exit codes), even the smaller models can usually complete the task. They just take many more turns to brute-force their way there, and the skill helps them less than you would expect, because their bottleneck is reasoning rather than knowledge. Moving from Sonnet to Opus noticeably reduces total token usage per eval, because the stronger model one-shots more often rather than stumbling through an error-fix loop. Opus 4.7 one-shots more reliably than 4.6, but uses slightly more tokens on average, spending more on thinking up front and less on retries (and also differences in how it computes token usage).
The other result worth mentioning is the token-reduction pass we did on the skill itself. A round of compressing prose or tables into comma-separated lists and removing redundant examples cut the overall skill size by roughly a quarter, with no measurable change in pass rate. That kind of change is the one I trust the harness for the most. It is easy to delete things from a skill if you have a way to confirm afterward that nothing important went with them.