Ingest streaming data
While batch data is imported in large chunks, ticking data (or streaming data) is appended to an intraday table on a row-by-row basis as it arrives. Ticking data is also different from batch data in how Deephaven handles it. Normally, batch data that is imported to a partition with today's date is not available to users. The expectation is that such data will first be merged and validated before users should access it. Ticking data, on the other hand, is immediately delivered to users as new rows arrive. The quality of this newest data may be lower than that of historical data but having access to information with low latency is generally more important for ticking sources.
Another difference between batch and ticking data is that there are no general standards for ticking data formats. CSV, JDBC, JSON, and others provide well-known standards for describing and packaging sets of batch data. However, ticking data formats do not have such accepted standards, so there is always some custom work involved in adding a ticking data source to Deephaven.
Typical steps in adding a streaming data source to Deephaven:
- Create the base table schema
- Add a LoggerListener section to the schema
- Deploy the schema
- Generate the logger and listener classes
- Create a logger application that will use the generated logger to send new events to Deephaven
- Edit the host config file to add a new service for the tailer to monitor
- Edit the tailer config file to add entries for the new files to monitor
- Restart the tailer and DIS processes to pick up the new schema and configuration information
The last three steps above apply only if deploying a new tailer. If the standard Deephaven Java logging infrastructure is used (with log file names that include all the details needed for the tailer to determine its destination), the existing system tailer should pick up new tables automatically.
Process Overview
In addition to specifying the structure of the data in a table, a schema can include directives that affect the ingestion of live data. This section provides an overview of this process followed by details on how schemas can control it. Example schemas are provided as well.
Streaming data ingestion is a structured Deephaven process where external updates are received and appended to intraday tables. In most cases, this is accomplished by writing the updates into Deephaven's binary log file format as an intermediate step.
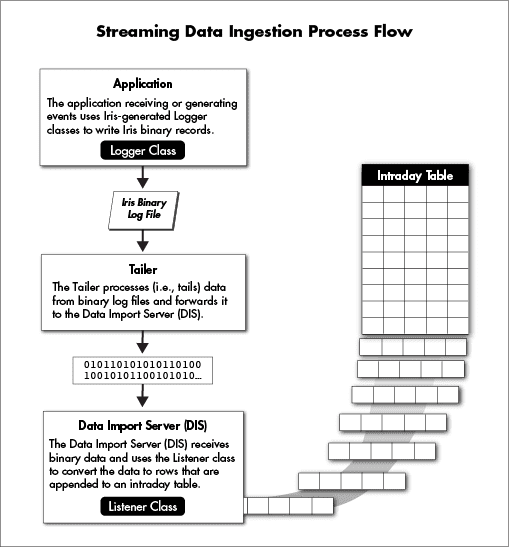
To understand the flexibility and capabilities of Deephaven table schemas, it is important to understand the key components of the import process. Each live table requires two custom pieces of code, both of which are generated by Deephaven from the schema:
- a logger, which integrates with the application producing the data
- a listener, which integrates with the Deephaven Data Import Server (DIS)
The logger is the code that can take an event record and write it into the Deephaven binary log format, appending it to a log file. The listener is the corresponding piece of code that can read a record in Deephaven binary log format and append it to an intraday table.
The customer application receives data from a source such as a market data provider or application component. The application uses the logger to write that data in a row-oriented binary format. For Java applications or C#, a table-specific logger class is generated by Deephaven based on the schema. Logging from a C++ application uses variadic template arguments and does not require generated code. This data may be written directly to disk files or be sent to an aggregation service that combines it with similar data streams and then writes it to disk.
Note
See also: Logging from C# and Logging from C++.
The next step in streaming data ingestion is a process called the tailer. The tailer monitors the system for new files matching a configured name and location pattern, and then monitors matching files for new data being appended to them. As data is added, it reads the new bytes and sends them to one or more instances of the Data Import Server (DIS). Other than finding files and "tailing" them to the DIS, the tailer does very little processing. It is not concerned with what data is in a file or how that data is formatted. It simply picks up new data and streams it to the DIS.
The Data Import Server receives the data stream from the tailer and converts it to a column-oriented format for storage using the listener that was generated from the schema. A listener will produce data that matches the names and data types of the data columns declared in the "Column" elements of the schema.
Loggers and listeners are both capable of converting the data types of their inputs, as well as calculating or generating values. Additionally, Deephaven supports multiple logger and listener formats for each table. Together, this allows Deephaven to simultaneously ingest multiple real-time data streams from different sources in different formats to the same table.
Please read our full documentation on Streaming Data for further details.