Aggregate
Aggregations are essentially an extension of grouping. They allow you to easily find sums, counts, variances, etc. of records within a group.
- “I want the sum of TradeSize by Account... or by Symbol... or by Account & Symbol.”
- “I want the max of SignalMagnitude by Factor... or by PM-Group & Factor.”
- “I want the average of slippage by Sector, AgeOfTrade, and Exchange.”
Aggregation operations:
- group the values of multiple rows based on the key,
- return a calculation on the arrays of all the non-key columns in those groups.
There are three ways to perform aggregations programmatically:
Note
All aggregations update in real time as new data becomes available.
Dedicated Aggregators
The syntax for single aggregations is very similar to that of basic grouping methods:
agg = sourceTable.aggTypeBy("groupingKey")
If multiple values are used in the groupingKey argument, each distinct value set is used for grouping. You can choose to omit a value for this argument (except when using the countBy method) to aggregate the table data without grouping.
See below to learn about each aggType. The examples use the following source table:
firstBy and lastBy
The firstBy method finds and groups each distinct value or set of values for the grouping column(s), then returns the first row for each group:
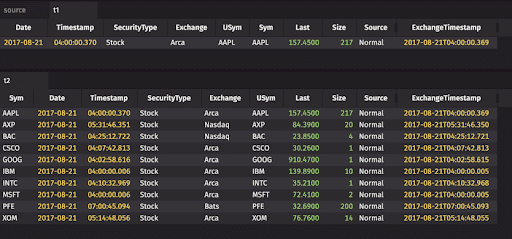
The lastBy method finds and groups each distinct value or set of values for the grouping column(s), then returns the last row for each group:
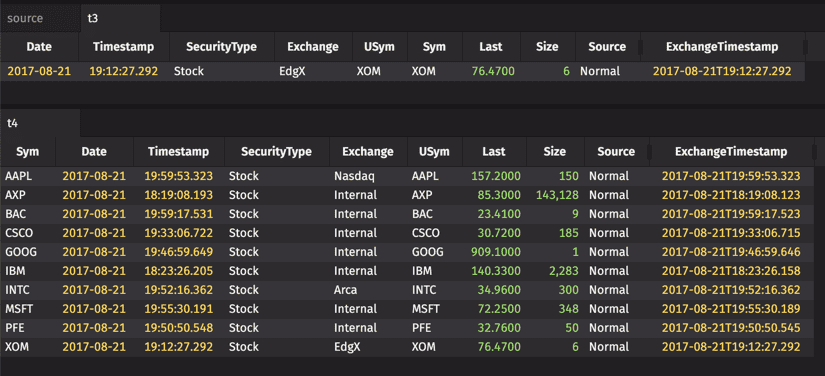
Note
If there is no value in the groupingKey argument, grouping is not performed.
Math-Driven AggTypes
These aggTypes include:
- sumBy
- avgBy
- stdBy
- varBy
- medianBy
- minBy
- maxBy
Again, the basic syntax for applies to all aggTypes:
agg = sourceTable.aggTypeBy("groupingKey")
Inside the aggType argument, one identifies the grouping key(s)), then all remaining columns in the table are aggregated.
Caution
Since the aggregation calculation will be performed on all non-key columns, these math-driven methods (will trigger an error if string, char, boolean types are represented in the non-key fields.
It is the user's responsibility to ensure the aggregation formula is compatible with the data type of each column being aggregated. For example, if you perform an avgBy on a column containing strings, the query will throw an error.
Note
Nulls are generally ignored in the aggregations. For example, a null record will not pollute an avgBy calculation. However, NaNs in the input will affect the output of the aggregation defining it to be a NaN. You can use a filter to remove NaN’s: .where("!isNaN(FieldName)").
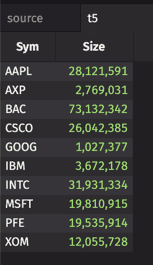
sumBy
The sumBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the sum of the data in each of the other columns.
avgBy
The avgBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the average (mean) of the data in each of the other columns.
stdBy
The stdBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the standard deviation of the data in each of the other columns.
varBy
The varBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the variance of the data in each of the other columns.
medianBy
The medianBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the median of the data in each of the other columns.
minBy
The minBy method each distinct value or set of values for the grouping column(s), and for each group, calculates the minimum of the data in each of the other columns.
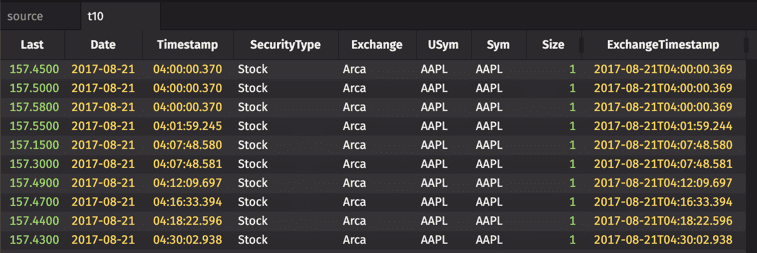
maxBy
The maxBy method finds each distinct value or set of values for the grouping column(s), and for each group, calculates the maximum of the data in each of the other columns.
countBy
The countBy method finds and groups each distinct value or set of values for the grouping column(s), and counts the number of rows in each group.
Warning
countBy with no arguments will fail.
Both queries below create and name a column to house the count. The second query first groups the data by each distinct Sym value, then performs the count.
Note
The count aggregation simply counts rows. It does not in any way review the data, so nulls and NaNs will be included unless the query dictates otherwise.
If you do not want nulls and NaNs to be included in the count, simply add:
headBy and tailBy
The headBy method finds and groups each distinct value or set of values for the grouping column(s), and returns the first n rows for each group.
The tailBy method finds and groups each distinct value or set of values for the grouping column(s), and returns the last n rows for each group.
Combined Aggregators
Deephaven also allows you to perform multiple aggregations at once. Each aggregation must be defined by the AggCombo method, created using methods in the ComboAggregateFactory class:
The arguments for these methods include the name of the source column(s) for the calculations and the name(s) for the columns to be used in the new table. The key(s) of the aggregation are identified at the end.
Caution
If multiple aggregations are applied to one column without renaming the output columns, the query will throw an error; e.g, .update("X = 42").by(AggCombo(AggSum("X"),AggAvg("X"))).
A list of the available aggregation types follows.
AggArray- Creates an array of all the values in the source column(s) and then aggregates the results into their own column(s).AggAvg- Computes an average value in the source column(s) and then aggregates the results into their own column(s).AggWAvg- Computes a weighted average in the source column(s) and then aggregates the results into their own column(s).AggCount- Counts the number of rows in the source column(s) and then aggregates the results into their own column(s).AggCountDistinct- Creates a distinct count aggregation. The output column contains the number of distinct values for the input column in that group.AggDistinct- Creates a distinct aggregation. The output column contains aDbArrayBasewith the distinct values for the input column within the group. Null values are ignored. Similar toAggArray, but returns a Set.AggFirst- Groups rows containing the same distinct value in the source column(s), returns the first row, and then aggregates the results into their own column(s).AggLast- Groups rows containing the same distinct value in the source column(s), returns the last row, and then aggregates the results into their own column(s).AggMax- Computes a maximum value in the source column(s) and then aggregates the results into their own column(s).AggMed- Computes a median value in the source column(s) and then aggregates the results into their own column(s).AggMin- Computes a minimum value in the source column(s) and then aggregates the results into their own column(s).AggPct- Computes the designated percentile of values in the source column(s) and then aggregates the results into their own column(s).AggSortedFirst- Aggregates the rows by the grouping keys, then sorts the values within those groups in ascending order, and then returns the first value for that group. Requires an array of sort column names.AggSortedLast- Aggregates the rows by the grouping keys, then sorts the values within those groups in descending order, and then returns the last value for that group. Requires an array of sort column names.AggStd- Computes standard deviations of values in the source column(s) and then aggregates the results into their own column(s).AggSum- Computes a total sum of values in the source column(s) and aggregates then the results into their own column(s).AggWSum- Computes a weighted sum in the source column(s) and then aggregates the results into their own column(s).AggVar- Computes the variance of the data of values in the source column(s) and then aggregates the results into their own column(s).
Example 1
For this example, the goal is to calculate the earliest timestamp and lowest price in a table containing data regarding the trade of securities for a single day.
The appropriate ComboBy method follows:
AggMin("EarliestTimestamp=Timestamp", "EarliestPrice=Price")
Because the resulting values are aggregated, it is important to rename the resulting columns with the aggregated title.
The syntax shown above applies to all of the ComboBy methods except AggCount(). The count is based on the number of rows rather than any particular source column, so the only argument to AggCount() is the desired result column name. For example, one could use AggCount("Count") or AggCount("Total").
Note
Important Python users must import the Python module that supports these methods:
from deephaven import ComboAggregateFactory as caf
Example 2
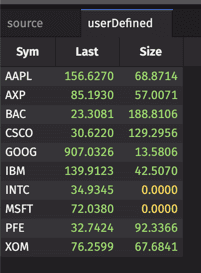
User-defined Aggregators
You can define your own aggregations using the following syntax:
source.applyToAllBy("formulaColumn","groupingKey")
The key groups data by columns and applies the formula defined in the formula column to each of the columns not altered by the grouping operation.
formulaColumn represents the formula applied to each column, and uses the parameter each to refer to each column to which it is being applied.
Caution
It is the user's responsibility to ensure the aggregation formula is compatible with the data type for each column being aggregated.
Example
This query imports an outside package to calculate the geometric mean of Deephaven table data.