Roll-up Tables
Roll-up Tables allow users to reduce a large, detailed data set to show only certain, customized aggregated column values. Roll-up Tables provide the option to group your data by a specified "Group By" column, and then display total values (such as sum or average) of other columns in the tables for those distinct items in the "Group By" column. In other words, if you select Sym as your "Group By" column, and then select the AskSize and BidSize columns to be aggregated as an average, your original table will reload into an expandable table with three columns showing the average AskSize and BidSize for each distinct Sym in the dataset.
Once created, Roll-up Tables can also be sorted or filtered to extract further insights.
Creating Roll-up Tables can be accomplished through the query language or in the Deephaven Classic console using the Create Roll-up option in the right-click table data menu. The following section details how to configure Roll-up Tables using the query language.
The syntax follows:
.rollup(AggCombo([Aggregations...]), groupByColumns...)
The following example creates a table using data from the StockQuotes table in the LearnDeephaven namespace. The final Roll-up Table, t2, will be grouped first by Sym, then Exchange, and show four other columns: the minimum Ask price, the average Ask Size, the maximum Bid price, and average Bid Size.
- This query generates the Roll-up Table, t2, by first applying the
rollupmethod. It then chains a series of aggregations using theAggCombomethod. - Be sure to give the new columns in your table unique names; i.e., this query calculates two averages, however, the column names are distinguished as "AskSize_Avg" and "BidSize_Avg". (Using two columns named Avg would cause the query to fail.)
- Finally, the query specifies the two columns by which to group data.
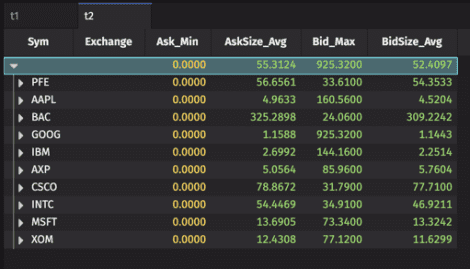
When the query runs, the t2 table will open in its collapsed state, as shown below.

Clicking the right-facing arrow in a root row opens the different levels of the Roll-up Table. Once a row is opened, its arrow faces downward.
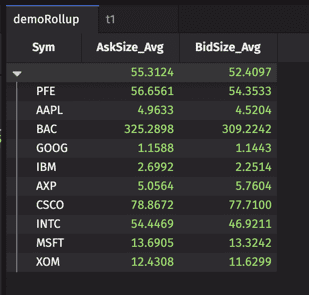
Below, you can see the Roll-up Table opened to the first level of distinct Sym values. The other four columns in the table (Ask_Min, AskSize_Avg, Bid_Max, and BidSize_Avg) show the selected aggregations for each of the ten distinct Symbols.
Clicking the arrow next to GOOG will then reveal all of the rows for GOOG grouped by the unique values found in the Exchange column, and the values in each of the other four columns are aggregated accordingly.
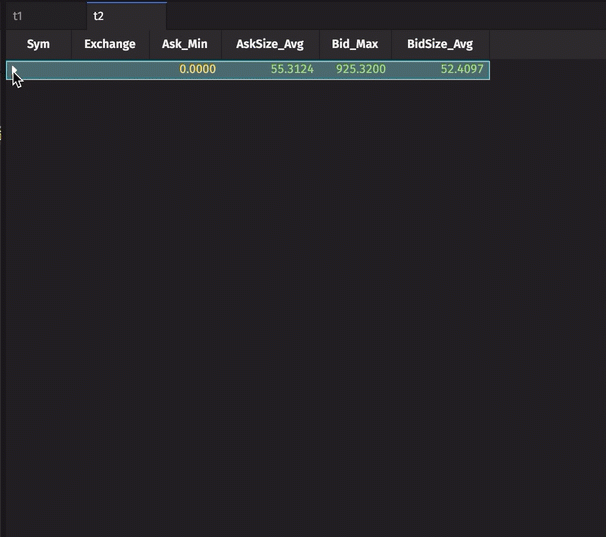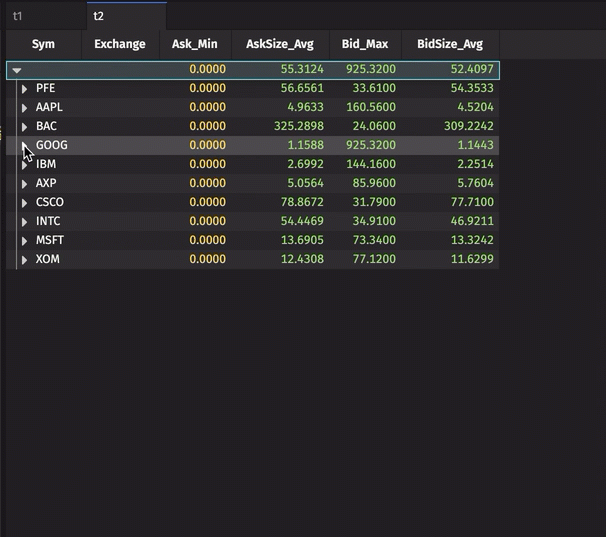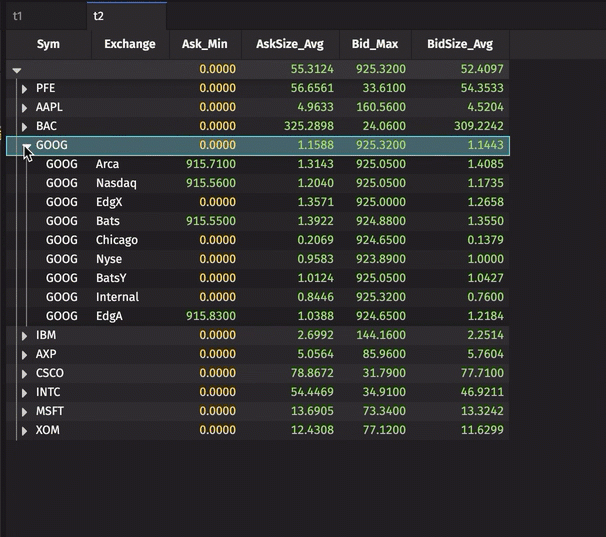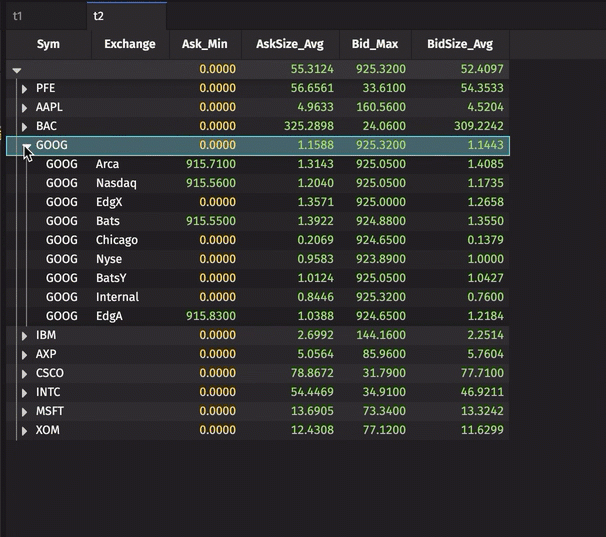
The aggregated values for all GOOG data (without regard to the Exchange) remains visible in the first row. However, the aggregated values for GOOG at each Exchange are also now included in the table. Rows can be re-collapsed by clicking the downward arrow.
As with any other tables created in Deephaven, the columns in the Roll-up Table can also be sorted, moved, or hidden in the UI. However, any changes to the aggregation parameters must be made in the original query.
All filter methods, including AutoFilters, are compatible with Roll-up Tables. However only Group By columns may be filtered in a Roll-up Table at this time. AutoFilters may be inherited from the source table, or applied directly to the Roll-up Table.
Caution
The rollup method must be the last method called on the table. For example, renameColumns cannot be used to change column names after the rollup method has been applied.
Available aggregation operations
The following aggregation operations may be used:
First- Displays the first value of the column.Last- Displays the last value of the column.Min- Displays the minimum of the column.Max- Displays the maximum of the column.Sum- Displays the total sum of the column.Avg- Displays the total average of the column.Std- Displays the standard deviation of the column.Var- Displays the variance of the column.Count- Displays the number of non-null items present.Skip- Does not display any aggregation information for this column.
Including constituent rows
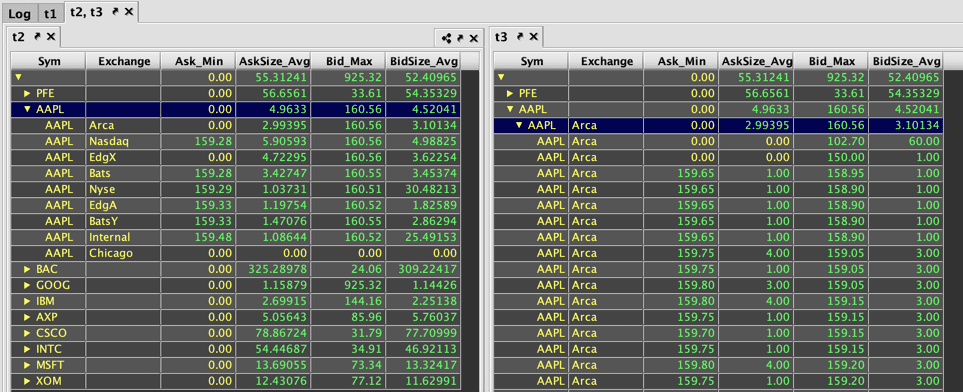
You can add an additional parameter, includeConstituents, to show what rows from the source table contributed to the hierarchy up to a particular level.
The parameter is placed between the aggregrations and the "Group By" columns:
.rollup(AggCombo([Aggregations...]),includeConstituents, groupByColumns...)
When set to true, this adds an additional level will be added to the roll-up that contains the rows that were part of the aggregation.
Predefined Roll-ups
In many cases there will be a handful of roll-up configurations that are considered useful for a specific table. In these cases it may be desirable to give users a set of pre-configured roll-ups. Pre-Configured Rollups are created using the Builder pattern when the query is written using the RollupDefinition class. For this to work you must import the following two classes:
First, create a Builder, and then invoke the methods below to configure the builder as you see fit, then call buildAndAttach() to attach the configuration to a specific table, or tables. See the available aggregations above.
A new right-click option will appear:

You may also reuse and mutate the builder to create additional configurations. Note that builder state is cumulative, so if there is an aggregation that you do not want you must explicitly clear it.
RollupDefinition Builder API
Builder name(String name)- Set the name of the roll-up. This will be how it is presented in the menu.Builder groupingColumns(String... columns)- Set the grouping columns for the roll-up. Order matters.Builder agg(AggType type, String... columns)- Set the columns for a specific aggregation. An empty list clears the aggregation. Note thatCountrequires one parameter - the name of the column - although this name will not display.Builder includeConstituents(boolean include)- Include the rows from the original table at the lowest level of the roll-up.RollupDefinition build()- Create aRollupDefinitionfrom the current builder state.Builder buildAndAttach(Table to)- Create aRollupDefinitionand attach it to the specified table as a predefined roll-up.Builder buildAndAttach(Table to, boolean preCreate)- Create aRollupDefinitionand attach it to the specified table as a preconfigured roll-up, and optionally compute and cache the roll-up.
Linking behaviors
Roll-ups only allow their grouping columns to participate in linking to and from other tables. When operating as a link source, Roll-ups will only provide filters for columns that are valid at the level of the clicked row.
Note
See: Linker
Flat level filtering on hierarchical tables
When filtering hierarchical tables, the Engine attempts to maintain the structure of the tree. For Tree Tables, this means ensuring that any filtered ancestors of a particular row are also present.
For Roll-Ups, filtering is normally only allowed on the grouping columns because it is difficult to define a filtering behavior that is correct under all circumstances.
There are cases, however, when it is desirable to simply filter each level of table in place without performing expensive work to maintain the structure. For example, you may have a roll-up that computes min/max values for a column and you only want to see values with at least a specific value; or, you might want to filter a tree and discard subtrees that do not match, even if they have children that do.
A flat filter simply applies the filters to each visible level of the table. Flat filters are enabled on a per-column basis using the withFlatFilterColumns(String...) method on the table.
When columns have been marked for flat filtering, any filter application done by the UI to those columns will apply the filter to each visible level in the tree.
Note
For Roll-Ups this means that, at any single level, rows may be filtered out that are still contributing to the aggregation at the parent node.
For Tree Tables, any child nodes that fall underneath a parent that is filtered out are orphaned and will not be visible.
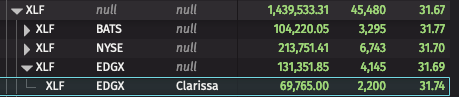
Below is an example query with some generated test data to illustrate how flat filters are used:
Let's consider one subtree of the table above, rooted at XLF, which is unfiltered in the image below:
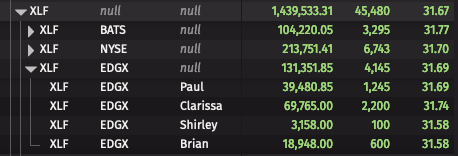
If we apply a filter Trader in `Clarissa` , we end up with the following result. Note that the deepest level is filtered to only contain Clarissa, but the values of the roll-up aggregation at the parent node have not changed. This filtering is much more efficient since the engine is not required to recompute the entire Roll-up.
Next, say there is a Tree Table created like this:
Note in the image that the value REM exists in the USym column for the first row, and also at the second level of the second row:
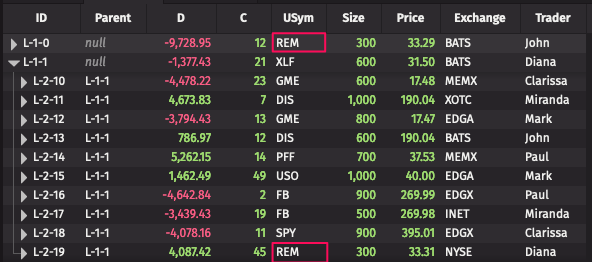
Now, if we apply a filter USym in `REM` , the result table contains only the first row, even though rows at the second level of the second row matched:
