Controlling table update frequency
There are two underlying processes used when updating tables with live data in Deephaven.
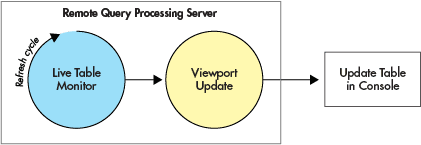
- When new data is generated on the server, the Live Table Monitor (LTM) first manages the process of updating the source tables and the derived tables with the new data. At this point, data updates are available within the server process.
- Once a table has been updated during the LTM refresh cycle, the Viewport Update process sends the new data to the console where rows are added to the table(s) that are presented in the user interface.
These processes are illustrated below.
Live Table Monitor
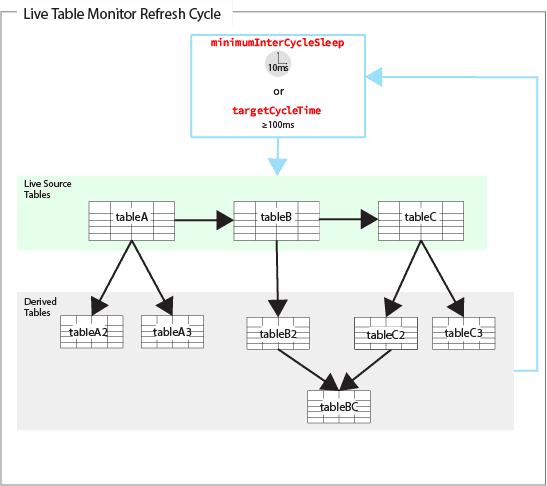
The Live Table Monitor ultimately controls how often data is refreshed on the server. At the beginning of a cycle, the LiveTableMonitor thread refreshes each source table. If one or more source table are updated with new data, then all the derived tables (if any) are incrementally updated. This includes when one of the derived tables is also the source table for subsequently derived tables. The source tables are refreshed serially, however independent derived tables may be refreshed in parallel if the LiveTableMonitor.updateThreads property is set to a value greater than 1. The refresh cycle is completed after all the derived tables are updated.
An illustration of the overall process follows:
The Live Table Monitor has six user-configurable properties:
LiveTableMonitor.refreshAllTablesLiveTableMonitor.targetCycleTimeLiveTableMonitor.intraCycleSleepLiveTableMonitor.minimumInterCycleSleepLiveTableMonitor.intraCycleYieldLiveTableMonitor.interCycleYieldLiveTableMonitor.updateThreads
Each property is described below.
refreshAllTables
The refreshAllTables property is true by default - this means that all source tables are refreshed before processing notifications. Each clock tick within the LTM will have a longer duration, but users may achieve greater parallelism and cycle savings by calculating fewer intermediate results. Setting this property to false will disable the refreshing of all tables at the start of the LTM cycle.
The syntax follows:
LiveTableMonitor.refreshAllTables=false
targetCycleTime
The targetCycleTime property sets the target time (in milliseconds) for one Live Table Monitor refresh cycle to complete. This includes updating each source table and the corresponding derived tables. The syntax follows:
LiveTableMonitor.targetCycleTime=<milliseconds>
For example, when the targetCycleTime is set to 500, the query engine attempts to complete the entire refresh cycle in 500 milliseconds.
The value set for this property does not guarantee the actual time for the cycle to complete. If the actual refresh cycle completes faster than the value set for targetCycleTime, the next refresh cycle is paused until the value has been reached. If the actual refresh cycle takes longer than the value set for targetCycleTime, the refresh cycle will start again as soon as possible after the cycle completes.
A variety of conditions can cause the actual refresh cycle to take longer than the targetCycleTime:
- The actual time needed for incremental update processing from refreshed tables may be longer than anticipated.
- The Live Table Monitor refresh thread may contend on the LiveTableMonitor lock, which prevents data refresh during the middle of an operation. For example, if two threads are changing the same data at the same time, placing a lock on the data prevents another thread from changing that data until the lock is once again available. This is especially important for the Live Table Monitor. See Live Table Monitor Lock.
- If the server is busy, the refresh thread may not be scheduled.
- Configuration settings such as the
intraCycleSleeporminimumInterCycleSleepmay cause the cycle to be longer than the target.
intraCycleSleep
The intraCycleSleep property sets the minimum length of time (in milliseconds) to wait between the update of one set of tables (both source and derived) and the next set of tables (if any) within the same cycle. This cycle will only occur if refreshAllTables is set to false. The syntax follows:
LiveTableMonitor.intraCycleSleep=<milliseconds>
For example, if intraCycleSleep is set to 100, the Live Table Monitor will enforce a 100 millisecond waiting period between each set of tables (both source and derived) being refreshed in a given cycle.
minimumInterCycleSleep
The minimumInterCycleSleep property sets the minimum length of time (in milliseconds) to wait before starting another refresh cycle after the previous cycle has completed. The syntax follows:
LiveTableMonitor.minimumInterCycleSleep=<milliseconds>
If the actual cycle time plus the minimumInterCycleSleep value is greater than the targetCycleTime value, the new cycle will begin after the minimumInterCycleSleep period has elapsed, as shown below.

If the actual cycle time plus the minimumInterCycleSleep value is less than the targetCycleTime value, the new cycle will begin after the targetCycleTime period has elapsed, as shown below.

For instance, assume a situation where the targetCycleTime is set to 500ms, and the actual time to complete a refresh cycle is 450ms. If the value for minimumInterCycleSleep was set to 0ms (or was not set at all), the Live Table Monitor would start a new refresh cycle once the targetCycleTime value was reached (at 500ms). However, if the minimumInterCycleSleep was set to 100ms, the Live Table Monitor would wait for 100ms after the end of the actual cycle (450ms) before starting a new refresh cycle. In this case, the new cycle would start at 550ms (actual time plus the value set for minimumInterCycleSleep).
intraCycleYield
The intraCycleYield property is used to set whether the thread should be allowed to yield to the CPU between refreshing tables within a cycle.
When the intraCycleYield property is set to true, the Live Table Monitor process yields to the CPU so it can allow other threads to run, such as filter or sort operations. If the property is set to false, the Live Table Monitor will not yield to the CPU and will immediately begin processing the next source table. The syntax follows:
LiveTableMonitor.intraCycleYield=<true or false>
Use of this property is designed to prevent the Live Table Monitor refresh thread from starving other threads within the worker, without introducing the latency associated with sleeps.
interCycleYield
Similar to intraCycleYield, the interCycleYield property is used to set whether the thread should be allowed to yield the CPU between refresh cycles.
- When the
interCycleYieldproperty is set totrue, the Live Table Monitor process yields to the CPU between cycles. - If the property is set to
false, the Live Table Monitor will not yield to the CPU and will immediately proceed to the next cycle.
The syntax follows:
LiveTableMonitor.interCycleYield=<true or false>
Use of this property is designed to reduce latency while preventing the Live Table Monitor from starving other threads.
updateThreads
The LiveTableMonitor.updateThreads property allows multithreading within the LTM refresh cycle. If a table has multiple derived tables, all the incremental updates will be run in parallel (respecting dependencies) within one loop. The syntax follows:
LiveTableMonitor.updateThreads=N
N is the number of update threads.
For example, table A incrementally updates tables A2 and A3, and table A3 updates A4. When table A is updated, then tables A2 and A3 will update at the same time, followed by table A4. Then, the cycle proceeds to table B. This improves the efficiency of the LTM cycle, allowing the use of more CPU to reduce latency.
To take advantage of multithreading, you may need to restructure your query using the byExternal() method, which divides a single table into multiple derived tables that are defined by key-value pairs in a TableMap. This – in combination with the TableMap.asTable() operation – enables parallelism in the LTM cycle by allowing a TableMap to be operated on as if it were a single table. Then, any table operation will apply to each of the derived tables produced by the byExternal() method across multiple threads. To combine the independent tables, merge() must be used at the end of the query to recombine the independent tables into a single table. Care must be taken that the parallelism is performed along natural boundaries in the data. For example, if you perform a sumBy() operation but more than one of the independent tables has a given key, your result table will have multiple rows for that key.
In the following example, t1 is divided by USym, independently filtered on the Price column, and the results are combined into a new table:
Live Table Monitor Lock
The LiveTableMonitor interacts with query artifacts (tables, listeners, etc.) to drive update propagation throughout the query graph. The LiveTableMonitor lock prevents data refresh during the middle of an operation. For example, if two threads are changing the same data at the same time, placing a lock on the data prevents another thread from changing that data until the lock is once again available. This ensures the operation executes correctly.
Users can choose between a shared lock or an exclusive lock:
- An exclusive lock means update propagation is stopped and no other threads can make progress when the LTM has the lock.
- A shared lock allows others users to make progress when the LTM has the lock. Only threads that do not require an exclusive lock will continue to run.
Note: an exclusive lock acts like any other mutex, in that it provides strong ordering guarantees for code that operates while it is held. Code using the shared lock might need to introduce finer-grained locking of its own if it mutates data structures that will be used by other threads under the shared lock. The locks returned by LiveTableMonitor.exclusiveLock() and sharedLock() support reentrant locking, and do not support escalation. Please refer to Oracle's documentation for more information.
Shared Lock
The shared lock will prevent other threads from mutating query artifact data (i.e. , the indexes and column sources that make up refreshing tables), but will allow other read-only processing to proceed. This lock is suitable if you do not need to invoke any methods that require or acquire the exclusive lock. The shared lock is recommended for most use cases.
The following methods lock and unlock a shared lock:
LiveTableMonitor.sharedLock().lock- gets the shared lock for this LTM.LiveTableMonitor.sharedLock().unlock- unlocks the shared lock from this LTM.
Warning
The shared lock must be unlocked before locking the exclusive lock.
Exclusive Lock
The exclusive lock will prevent refresh or read-only processing from proceeding concurrently. It is recommended in the following cases:
- If you need to prevent other threads from mutating query artifact data (i.e., the indexes and column sources that make up refreshing tables), and you need to invoke any methods that require or acquire the exclusive lock.
- If you are mutating data that the LiveTableMonitor interacts with (query update propagation, generally).
- If you need to use a condition variable to wait for changes that will be propagated by the operation of the LiveTableMonitor. This includes
com.illumon.iris.db.v2.DynamicTable#awaitUpdate()andcom.illumon.iris.db.v2.DynamicTable#awaitUpdate(long), which internally acquire the exclusive lock and must not be invoked while the shared lock is held.
The following methods lock and unlock an exclusive lock:
LiveTableMonitor.exclusiveLock().lock- gets the exclusive lock for this LTM.LiveTableMonitor.exclusiveLock().unlock- unlocks the exclusive lock this LTM.
Other Methods
Both .exclusiveLock() and .sharedLock() return an AwareFunctionalLock, so all the methods for AwareLock, FunctionalLock, and Lock are available. The AwareLock class allows users to check whether they already hold the lock on the current thread, and the FunctionalLock class provides many convenience methods to pass lambdas for execution under the lock.
Note
Please see the Deephaven Javadoc for complete details.
Viewport Updates
As mentioned earlier, after a table has been updated during the Live Table Monitor refresh, the Viewport Update process sends the new data to the console where rows are added to the table(s) presented in the user interface. The timing for the updates is configurable through the viewport.updateInterval property. The syntax follows:
viewport.updateInterval=<milliseconds>
The updateInterval property determines how often table data can be sent from the server to the console for display. Each table has an independent viewport update job, which is started immediately after a table is refreshed. For example, if the updateInterval is set to 1000ms, new data will appear in the console every second, regardless of how often the data refreshes on the server. The lower the value, the more frequently the table can be updated, assuming there is new data to update and the bandwidth is sufficient. If updates are sent too frequently, they may overwhelm the network. For best performance, the updateInterval should be set so the tables are responsive without updating so frequently they distract the user.
Using a Snapshot Viewport
It is possible to set up a snapshot viewport, which updates table data visible in the UI every time the window repaints (determined by the viewport.updateInterval property) rather than automatically each time a table ticks.
An example follows of how to configure a snapshot viewport instead of one that will automatically update on every tick:
Let's break down this query into five parts:
- The first line of the query opens a source table, quotes, of ticking market data. The
lastBymethod finds each distinct symbol in the table and returns only the last/most recent row for each. - Next, we configure column sources. The final snapshot table will include these five columns.
symbolGetandsymbolGetPrevare the names of two functions that map key tosymbol.get(key)andsymbol.getPrev(key)respectively. These ask the column source (symbol) what is the value for key, which will be an index.- We then create an object (a ToMapListener) named "quoteHash", which is used in the formulas that create the snapshot viewport. The
listenForUpdatessubscription will only deliver new row changes to quoteHash. In the next section, the query asks quoteHash to return the most recent bidPrice, askPrice, bidSize, and askSize for each distinct symbol. - The last part of the query creates two additional tables. The "sd" table includes one column with each distinct symbol in the quotes table. When then add
updateViewto create the snapshot table, which includes a column for each of the five column sources created above, and finally set the table attribute to the two constants,VIEWPORT_TYPE_ATTRIBUTEandSNAPSHOT_VIEWPORT_TYPE.
Every time the default 1 second elapses, Deephaven attempts to read the five columns in the viewport. However, the updateView will only be evaluated when it is read, in this case evaluating only the rows visible in the UI.