Using Python with Deephaven
Programming with Python
The purpose of this section is to address the usage of Python in a persistent query, or in a Deephaven (Swing) or Web console. This is not intended to address issues involved with using a Python client on a local workstation to perform certain tasks on a remote server outside of a console.
This guide augments, rather than replaces, the sections of the documentation describing basic usage of the Deephaven Query Language, and assumes a basic understanding of the query language.
Creating a Console or Persistent Query
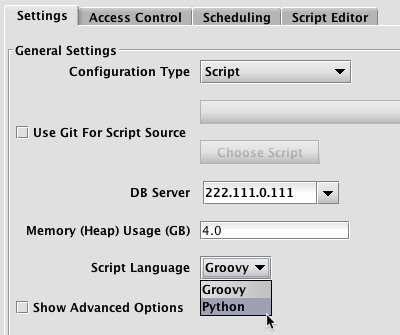
Python can be used in the Deephaven (Swing) console, Web console, or to script a persistent query. When a user launches a console or creates scripts for a persistent query, they will be prompted to choose between Groovy and Python.
When launching a Deephaven Console:
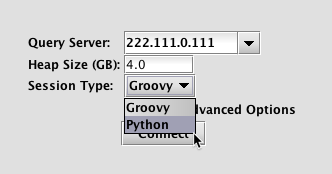
In the Persistent Query Configuration Editor:
The jvm initialization flags for the Python console, where the Python environment is initialized from Java by jpy, must be provided under Advanced Options.
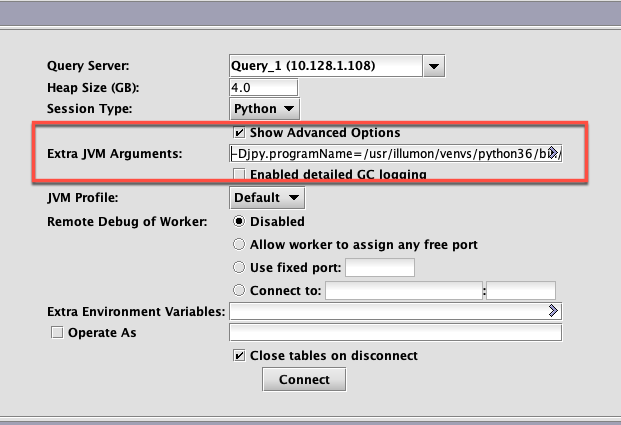
Note
Upon closure of the console, the user will be prompted to save the workspace. Answering Yes will result in these extra jvm arguments being saved for easy reuse.
Java/Python Interoperation
The jpy Java-Python Bridge
The entire Deephaven infrastructure is engineered in Java. This infrastructure is used from Python through the use of the jpy project to provide a bridge between the Python language and the Java language. To briefly summarize, jpy allows for the creation of a Java interpreter and then construction of and use of Java objects from within the Python interpreter, and vice versa.
For the following discussion, most of the details of this interoperability are not important. However, it is important to be aware that the underlying objects used by the Deephaven infrastructure are actually Java objects. The query language processing is handled by Java, and this has some impact of some basic query constructs.
One notable aspect of jpy usage is that each pass "across the bridge" between Python and Java - function arguments or other object passing - generally requires a translation, which comes at some computational expense. Please see the Python to Java Optimizations for a more thorough discussion of this issue, and explanation of best practices.
A Java class can be directly referenced from Python by using the jpy.get_type method, which returns a Python type object corresponding to a fully qualified Java type name. Public constructors and static fields and methods for the Java class can be directly accessed from this type in direct analogy to Python constructors and static methods are used from their type.
For more robust details please see the jpy project documentation.
When instantiating a Java object from Python, jpy performs a complicated matching scheme for the provided Python arguments and possible Java function signatures. This is subject to confusion in the face of more than one potentially matching Java function signature, or for objects in one language with no single clear analog in the other language.
Specifically for Deephaven, a Python package containing a variety of helper methods for specific Deephaven Java classes and common tasks has been constructed to help alleviate some of these issues. These methods are described below.
Basic Principles for the Query Engine
Let's start with a basic query statement that could be executed from a Python console or persistent query, and point out some basics:
or
Note
initial_table and derived_table are Java objects that are being manipulated from within the Python interpreter.
All interpretation of the contents of <statement> (the string being passed in to the query language parser) is actually being done in Java, and where appropriate, Java syntax must be used.
For the sake of clarity, some explicit examples follow.
Ternary statement:
This uses a Python ternary construct inside a query statement, which is being interpreted as Java. This will not execute, and will return a somewhat unclear syntax error about the statement ending prematurely.
This uses appropriate Java ternary construct, and will execute.
Object inside a query statement:
A Python list object cannot be successfully interpreted as a Java array analog from inside of Java.
This creates an appropriate Java object (convertToJavaArray is a Deephaven helper method), which can be successfully used inside of a query statement.
Deephaven Python Package Structure
The structure of the Deephaven Python package is best explored through the use of Python's interactive tools.
help
To get a basic summary of information for the deephaven package from the Python console, run the following:
This will print the constructed help for the deephaven package to the console log. The overall package structure is easily gleaned from this.
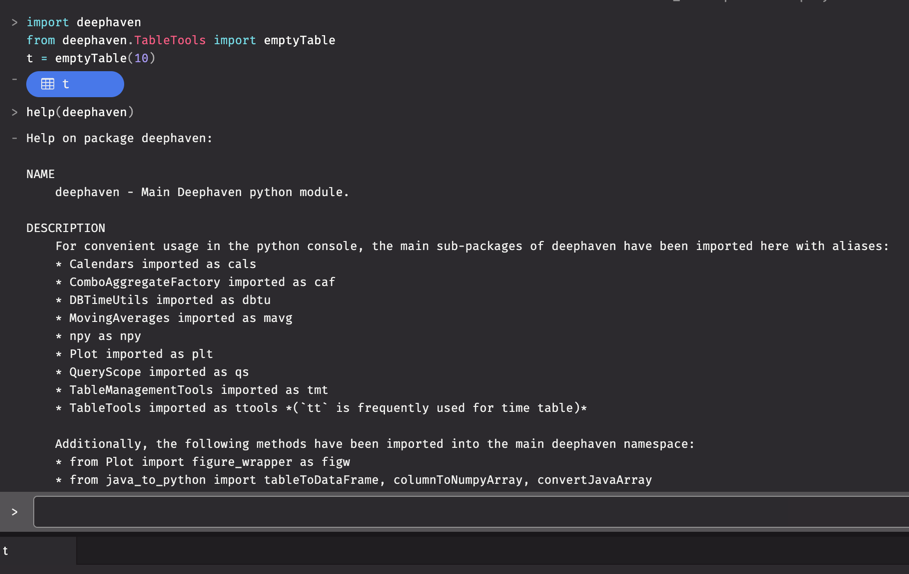
Note the sub-packages (Calendars, ComboAggregateFactory, DBTimeUtils, Plot, TableManagementTools, and TableTools) are generated from the static methods of corresponding Java classes. The proper usage of these sub-packages is best understood through a combination of Deephaven's Java documentation and the examples and provided in the Deephaven documentation.
You can also use the help method to print information about a method or object. For example:

Console Import of Deephaven Package
The deephaven package and all sub-packages (with suitable abbreviations) can be simply imported through two statements:
The package is constructed to provide a coherently constructed namespace.
Providing Default Python Imports
To add to or modify the console namespace, a collection of default imports can be specified by providing the name of a text file, with one import statement per line, to the console launcher. This is done by setting the python.default.imports property as an additional argument to the console launcher:
This assumes that the file is in location /usr/illumon/latest/etc/importpython.txt on the server where the worker is starting up. The only requirement for the referenced file is that it has read access by the user who is authenticated through the launcher. Any commands in this file that are not import statements will not be executed.
Note
This functionality assumes a default configuration, where core/illumon_jpy_init.py is run when initializing a worker.
Console Namespace Contents
Whether the import above is used or not, the user is encouraged to understand the content of the console namespace to avoid unusual errors resulting from redefinition of symbols already defined there. The namespace contents can be easily inspected by executing the following statement:
Package Structure
As summarized in the help('deephaven') entry, the statement from deephaven import * will import the subpackages with these abbreviations:
Calendarsimported ascalsComboAggregateFactoryimported ascafDBTimeUtilsimported asdbtuPlotimported aspltQueryScopeimported asqsTableManagementToolsimported astmtTableToolsimported asttools(Note:ttis frequently used for time table)
Additionally, the following methods have been imported into the main Deephaven namespace:
from Plot import figure_wrapperasfigwfrom java_to_python import tableToDataFrame,columnToNumpyArray,convertJavaArrayfrom python_to_java import dataFrameToTable,createTableFromDatafrom conversion_utils import convertToJavaArray,convertToJavaList,convertToJavaArrayList,convertToJavaHashSet,convertToJavaHashMap
It is encouraged that individual doc strings, such as for the tableToDataFrame method, should be inspected via the help method. This can be accomplished after the import given above with:
or before/without the import using the following:
Helper Functions for Converting Objects
Python Conversion to Java Analog
Python list, tuple or numpy.ndarray to Java array, List, ArrayList, or HashSet
For many Deephaven purposes, an underlying object of importance will be a simple collection. In Python, this would most likely be represented as a list, tuple, or numpy.ndarray. In Java, this could most appropriately match up to an array, List, ArrayList, or HashSet.
Whether for specific safe use in a query, or helping jpy to overcome failed function signature matching, it may be required to directly construct the appropriate Java object from within Python. To do this, the following convenience methods have been provided as part of the Deephaven package:
convertToJavaArray(input)convertToJavaList(input)convertToJavaArrayList(input)convertToJavaHashSet (input)
These convert the Python object input, assumed to be an instance of Python list, tuple, or numpy.ndarray, to an appropriately constructed Java array, List, ArrayList, or HashSet as the name of each method suggests.
In the conversion, the most natural type mapping will occur from numpy.ndarray to Java, and the type mapping is described in the convertToJavaArray method docstring, see help(convertToJavaArray):
- basic numpy primitive
dtype(bool,int8,int16,int32,int64,float32,float64) are converted to their Java analog, andNaNvalues in floating point columns are converted to their respective DeephavenNULLconstant values. dtypedatetime64[*]are converted to Deephaven'sDBDateTime.dtypeof one of the stringdtypes(unicode*,str*,bytes*) and all elements are one character long, then converted to char. Otherwise, converted to String.dtypenumpy.objectand empty (zero length) or all array elements are null are converted to Java Object. Otherwise, the first non-null value is used to determine the type:bool- the array is converted to an array of Java Boolean with null values preservedstr- the array is converted to an array of Java String type with null represented as the empty stringdatetime.dateordatetime.datetime- the array is converted to an array of Deephaven'sDBDateTimenumpy.ndarray- all elements are assumed None, or annumpy.ndarrayof the samedtypeand compatible shape, or an exception will be raised.dict- unsupported- other iterable type - naive conversion to
numpy.ndarrayis performed, then as above
- any other
dtype(namelycomplex*,uint*,void*, or customdtypes) unsupported
If the input is a Python list or tuple, naive conversion to numpy.ndarray is performed, then as above.
Note that Java arrays or HashSets have a variety of uses in Deephaven queries, while all of these Java types may be useful in specifically matching a desired function signature.
Constructing a Java HashMap
Whether for use in a Deephaven query or function signature mapping, it may be necessary to construct an appropriately typed Java HashMap. This can be accommodated via the convertToJavaHashMap method, which takes either a Python dict or iterable keys and values collections (list, tuple, numpy.ndarray). If a dictionary is provided, the first step is to extract keys and values as numpy.ndarray. Type conversions are performed precisely as in the above conversion methods.
Python Data Frame Viewer
When a user creates a data frame in Deephaven, a widget called the Pandas Data Frame Viewer opens with a view of the data, similar to what happens when a table is created.
Example
This query opens the widget shown below:
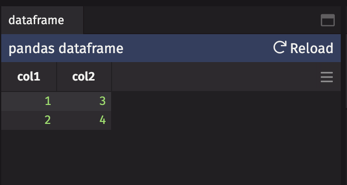
Sorts and filters can be applied as with a table. To implement these changes, hit the Refresh button.
Note that the Data Frame Viewer can be reopened from the Show Widget button in the Classic console, or opened from persistent queries using the Show Widget button in the Query Config panel.
Create Table from Python Data Structures
dataFrameToTable
The dataFrameToTable(dataframe, convertUnknownToString=False) method creates a Deephaven table from a pandas.DataFrame object. The type mapping for each column is identical to the above convertToJava* methods.
Any column that is not valid to convert directly to a Java analog (i.e., dtype is complex*, uint*, void*, or custom dtypes) can be converted to a String column if convertUnknownToString=True. Otherwise, any encountered column that is not valid for conversion will result in an exception.
createTableFromData
The createTableFromData(data, columns=None, convertUnknownToString=False) method creates a Deephaven table from a collection of column data. There are two viable options for the structure of data:
- a
dictinstance of the form{'column_name': column_data} - a tuple or list of the form
[column0_data, column1_data,...]
The optional argument convertUnknownToString has the same purpose as above.
The optional argument columns is expected to be of the form [<column 0 name>, <column 1 name>, ...].
If data is a dict, then columns (if provided) serves to provide column order, and only the entries of data keyed to an element of columns will be included. Otherwise, the key iteration order of data will determine column order.
If data is an iterable, then columns (if provided) serves to provide column names (order determined by data), and the length of data and columns must be identical. Otherwise, the column names will default to a basic enumeration {col_0,col_1,...}.
Examples
The previous query will result in default Python/Numpy typing, which will then get converted to corresponding Java type. In this case, we will have x column with Java type long and y column with Java type double. For more control over typing, use Numpy to enforce the desired type, as in:
Here the x column will be type byte and the y column will have Java type float.
Extracting Table Contents Into Python
tableToDataFrame
The tableToDataFrame(table, convertNulls=ERROR, categoricals=None) method clones a Deephaven table into the Python workspace as a pandas.DataFrame.
The value of the optional argument convertNulls is used to account for the fact that there is no built-in Pandas/Numpy version of "no value" in an integer dtype:
'ERROR'(default) leads to an exception in the case of a null in an Integer type field'PASS'directly copies over the numeric value of the null constant in an integer type column'CONVERT'recasts the converted column to floating point type and represents the null values asNaN
Null values in floating point types will always be converted to NaN values, regardless of the value of this flag.
The optional argument categoricals is used to provide a column name or collection of column names to instead convert to a pandas.Categorical series, which has unique values extracted and appropriate index into the values collection.
Type conversion for this method is based on the convertJavaArray method of the deephaven.java_to_python module, and is essentially just the inverse of the type conversion outlined in the convertToJava* methods above.
Note
The Deephaven table is likely a reference to (possibly down-selected) on-disk data, while a pandas.DataFrame is necessarily entirely represented in RAM. A call to this method blindly attempts to clone the specified table FULLY into memory. Ensure the appropriate down-selection of rows and dropping of unnecessary columns has been performed before calling this method, and give some thought to the size of that table.
columnToNumpyArray
The columnToNumpyArray(table, columnName, convertNulls='ERROR') method extracts a given column from a table as a numpy.ndarray. The null conversion behavior is also determined by the convertNulls flag. Either syntax below is acceptable:
df1=java_to_python.columnToNumpyArray(table, "ColName", convertNulls='ERROR')df2=java_to_python.columnToNumpyArray(table, "ColName", convertNulls=java_to_python.NULL_CONVERSION.ERROR)
Again, the entire column will be represented in memory, so some care should be taken in regards to the number of rows/size of the table/column.
Type conversion for this method is based on the convertJavaArray method of the deephaven.java_to_python module, and is essentially just the inverse of the type conversion outlined in the convertToJava* methods above.
Examples
Python to Java Optimizations
It is also worthwhile to note that each formula application against a Python variable will require traversing the jpy Python-to-Java translation layer. As mentioned above, these language transitions can heavily affect performance, and should be minimized.
For example, it is possible to use the contains method of a Python list within a query as shown below:
However, this will require that the Java-to-Python boundary be crossed once per each function evaluation; that is, once per row. This can be avoided by converting the Python object to the appropriate Java object, and then using that Java object in the query. This requires no Java-To-Python translation for each row, therefore it is much more performant for even a moderately sized table.
When operating on large data sets, it is important to be mindful of language transitions, and, when possible, recast your filters (where) or formulas (select, update, view, updateView) to minimize their use whenever possible.
Default Classpaths
The start_jvm.py script sets up default Deephaven Python integration including default classpaths. These are appended to any user classpath information provided by the jvm_classpath argument.
For client systems, the default classpath includes (under devroot):
For servers, the default classpath includes: