Importing Binary Log Files
Deephaven provides a tool for importing binary log files directly into Deephaven tables. Binary logs are normally processed by a tailer in real time and ingested by a Data Import Server. The typical use for this tool would be the (re)import of old logs if an error occurred during the initial ingestion or the original table data is lost.
Quickstart
The following is an example of how to import a specific binary log file. This command assumes a typical Deephaven installation and a log file located at /var/log/deephaven/binlogs/.
This example will import the given log file into localhost/2018-10-01, replacing whatever data exists in that location already, if any. Note that unlike with other imports, the source file(s) must be located relative to the dbmerge user logs directory.
Schema Inference
There is no schema inference tool for Binary imports - it is anticipated that a table schema will already exist consistent with the binary log files to be loaded.
Import Query
A persistent query of type "Import - Deephaven Binary Logs" is used to import data from binary log files into an intraday partition. The binary log files must be available on the server on which the query will run; it is not for loading files on the user's system into Deephaven. The binary log files must be in the Deephaven binary log file format, usually generated by an application using a generated Deephaven logger.
Note
The "Import-Deephaven Binary Logs" option is only available in Deephaven Classic.
When Import - Deephaven Binary Logs is selected, the Persistent Query Configuration Editor window shows the following options:
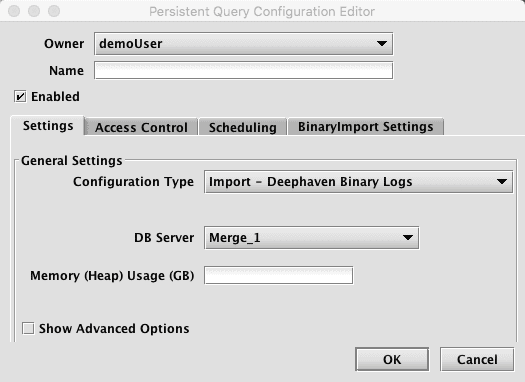
-
To proceed with creating a query to import Deephaven binary log files, you will need to select a DB Server and enter the desired value for Memory (Heap) Usage (GB).
-
Options available in the Show Advanced Options section of the panel are typically not used when importing or merging data. To learn more about this section, please refer to the Persistent Query Configuration Viewer/Editor.
-
The Access Control tab presents a panel with the same options as all other configuration types, and gives the query owner the ability to authorize Admin and Viewer Groups for this query. For more information, please refer to Access Control.
-
Clicking the Scheduling tab presents a panel with the same scheduling options as all other configuration types. For more information, please refer to Scheduling.
-
Clicking the BinaryImport Settings tab presents a panel with the options pertaining to importing a CSV file:
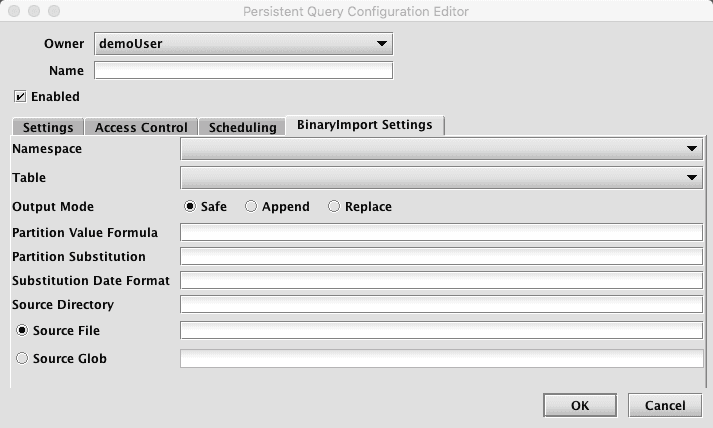
BinaryImport Settings
- Namespace: This is the namespace into which you want to import the file.
- Table: This is the table into which you want to import the data.
- Output Mode: This determines what happens if data is found in the fully-specified partition for the data. The fully-specified partition includes both the internal partition (unique for the import job) and the column partition (usually the date).
- Safe - if existing data is found in the fully-specified partition, the import job will fail.
- Append - if existing data is found in the fully-specified partition, data will be appended to it.
- Replace - if existing data is found in the fully-specified partition, it will be replaced. This does not replace all data for a column partition value, just the data in the fully-specified partition.
- Partition Formula: This is the formula needed to partition the binary log file being imported. If a specific partition value is used it will need to be surrounded by quotes. For example:
currentDateNy()"2017-01-01" - Partition Substitution: This is a token used to substitute the determined column partition value in the source directory, source file, or source glob, to allow the dynamic determination of these fields. For example, if the partition substitution is "PARTITION_SUB", and the source directory includes "PARTITION_SUB" in its value, that PARTITION_SUB will be replaced with the partition value determined from the partition formula.
- Substitution Date Format: This is the date format that will be used when a Partition Substitution is used. The standard Deephaven date partition format is
yyyy-MM-dd(e.g., 2018-05-30), but this allows substitution in another format. For example, if the filename includes the date inyyyyddMMformat instead (e.g., 20183005), that could be used in the Date Substitution Format field. All the patterns from the JavaDateTimeFormatterclass are allowed. - Source Directory: This is the path to where the binary log file is stored on the server on which the query will run.
- Source File: This the name of the binary log file to import.
- Source Glob: This is an expression used to match multiple binary log file names.
Importing Using Builder
There is currently no Builder for binary imports.
Import from Command Line
Binary imports can be performed directly from the command line, using the iris_exec tool.
Command Reference
iris_exec binary_import <launch args> -- <binary import args>
Binary Import Arguments
| Argument | Description |
|---|---|
| Either a destination directory, specific partition, or internal partition plus a partition column must be provided. A directory can be used to write a new set of table files to specific location on disk, where they can later be read with TableTools. A destination partition is used to write to intraday locations for existing tables. The internal partition value is used to separate data on disk; it does not need to be unique for a table. The name of the import server is a common value for this. The partitioning value is a string data value used to populate the partitioning column in the table during the import. This value must be unique within the table. In summary, there are three ways to specify destination table partition(s):
|
-ns or --namespace <namespace> | (Required) Namespace in which to find the target table. |
-tn or --tableName <name> | (Required) Name of the target table. |
-om or --outputMode <import behavior> | (Optional):
|
| sourceDirectory, sourceFile, and sourceGlob are all optional. If none of these are provided, the system will attempt to do a multi-file import. Otherwise, sourceDirectory will be used in conjunction with sourceFile or sourceGlob. If sourceDirectory is not provided, but sourceFile is, then sourceFile will be used as a fully qualified file name. If sourceDirectory is not provided, but sourceGlob is, then sourceDirectory will default to the configured log file directory from the prop file being used. |