Importing XML Files
Deephaven provides tools for inferring a table schema from sample data and importing XML files. Because XML can represent nested/hierarchical data in many different ways, mapping to Deephaven tables is more complex that for a simple format like CSV. The XML importer described here can handle a few common variations - extraction of value from either attributes or element text, and different levels of nesting, but some XML formats may require a custom importer.
Quickstart
The following is an example of how to generate a schema from an XML data file, deploy it, and import a file from the command line. These commands assume a typical Deephaven installation and a sample file located at /data/sample.xml.
Generate a schema from the sample XML data file above
The schema file will be generated in the "XMLExampleNamespace" directory.
Deploy the schema
See Deploying schemas to Deephaven for further details.
Import a single data file into the specified Intraday partition
This example will generate a table schema from sample.xml with the namespace XMLExampleNamespace and table name XMLExampleTableName, with a Name column of type String and a Value column of type double. The default behavior creates a directory for the namespace in the current directory and places the output schema file inside this directory. Once deployed, other XML files matching the structure of sample can be imported.
Schema Inference
XML schema inference generates a table schema from a sample XML file. Table columns and types are inferred from the data in a number of different ways, depending on the -xi, -xd, -xt, -ev, -av, and -pv options. Since XML files don't provide metadata in a consistent way, this inference process uses the same algorithm as the CSV schema inference in order to determine column types. This is necessarily imperfect, and generated schemas should always be inspected before deployment.
Command Reference
The following arguments are available when running the XML schema creator:
| Argument | Description |
|---|---|
-ns or --namespace <namespace> | (Required) The namespace to use for the new schema. |
-tn or --tableName <name> | (Required) The table name to use for the new schema. |
-sp or --schemaPath <path> | An optional path to which the schema file will be written. If not specified, this will default to the current working directory and will create or use a subdirectory that matches the namespace. |
-sf or --sourceFile <file name or file path and name> | (Required) The name of the XML file to read. This file must have a header row with column names. |
-xi or --startIndex | Starting from the root of the document, the index (1 being the first top-level element in the document after the root) of the element under which data can be found. |
-xd or --startDepth | Under the element indicated by Start Index, how many levels of first children to traverse to find an element that contains data to import. |
-xm or --maxDepth | Starting from Start Depth, how many levels of element paths to traverse and concatenate to provide a list that can be selected under Element Name. |
-xt or --elementType | The name or path of the element that will contain data elements. This is case-sensitive. |
-ev or --useElementValues | Indicates that field values will be taken from element values; e.g., <Price>10.25</> |
-av or --useAttributeValues | Indicates that field values will be taken from attribute values; e.g., <Record ID="XYZ" Price="10.25" /> |
-pv or --namedValues | Positional Values: When omitted, field values within the document will be named; e.g., a value called Price might be contained in an element named Price, or an attribute named Price. When this option is included, field names (column names) will be taken from the table schema, and the data values will be parsed into them by matching the position of the value with the position of column in the schema. |
-pc or --partitionColumn | Optional name for the partitioning column if schema is being generated. If this is not provided, the importer will default to "Date" for the partitioning column name. Any existing column from the source that matches the name of the partitioning column will be renamed to "source_[original column name]". |
-gc or --groupingColumn | Optional column name that should be marked as columnType="Grouping" in the schema. If multiple grouping columns are needed, the generated schema should be manually edited to add the Grouping designation to the additional columns. |
-spc or --sourcePartitionColumn | Optional column to use for multi-partition imports. For example if the partitioning column is "Date" and you want to enable multi-partition imports based on the column "source_date", specify "source_date" with this option (this is the column name in the data source, not the Deephaven column name). |
-sn or --sourceName <name for ImportSource block> | Optional name to use for the generated ImportSource block in the schema. If not provided, the default of "IrisXML" will be used. |
-sl or --skipHeaderLines <integer value> | Optional number of lines to skip from the beginning of the file before expecting the header row. If not provided, the first line is used as the header row. |
-fl or --setSkipFooterLines <integer value> | Optional number of footer lines to skip from the end of the file. |
-lp or --logProgress | If present, additional informational logging will be provided with progress updates during the parsing process. |
-bf or --bestFit | If present, the class will attempt to use the smallest numeric types to fit the data in the XML. For example, for integer values, short will be used if all values are in the range of -32768 to 32767. If larger values are seen, the class will then move to int and eventually long. The default behavior, without -bf, is to use long for all integer columns and double for all floating point columns. |
-om or --outputMode | Either SAFE (default) or REPLACE. When SAFE, the schema creator will exit with an error if an existing file would be overwritten by the schema being generated. When set to REPLACE, a pre-existing file will be overwritten. |
Import Query
A persistent query of type "Import - XML" is used to import data from an XML file into an intraday partition. The XML file must be available on the server on which the query will run; it is not for loading a file on the user's system into Deephaven.
Note
The "Import - XML" option is only available in Deephaven Classic.
Deephaven's support for XML files allows loading files into a single table. See the Tables & Schema section for more details about the layout considerations of XML files when importing into Deephaven.
When Import - XML is selected, the Persistent Query Configuration Editor window shows the following options:
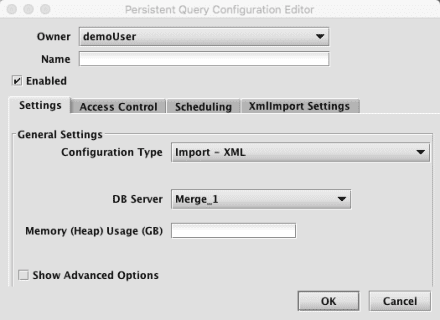
-
To proceed with creating a query to import an XML file, you will need to select a DB Server and enter the desired value for Memory (Heap) Usage (GB).
-
Options available in the Show Advanced Options section of the panel are typically not used when importing or merging data. To learn more about this section, please refer to the Persistent Query Configuration Viewer/Editor.
-
The Access Control tab presents a panel with the same options as all other configuration types, and gives the query owner the ability to authorize Admin and Viewer Groups for this query. For more information, please refer to Access Control.
-
Clicking the Scheduling tab presents a panel with the same scheduling options as all other configuration types. For more information, please refer to Scheduling.
-
Clicking the XmlImport Settings tab presents a panel with the options pertaining to importing an XML file:
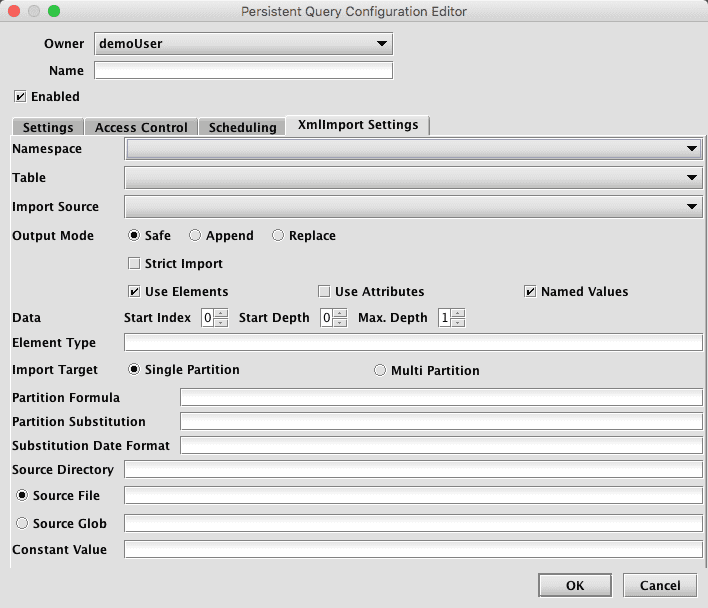
XmlImport Settings
- Namespace: This is the namespace into which you want to import the file.
- Table: This is the table into which you want to import the data.
- Output Mode: This determines what happens if data is found in the fully-specified partition for the data. The fully-specified partition includes both the internal partition (unique for the import job) and the column partition (usually the date).
- Safe - if existing data is found in the fully-specified partition, the import job will fail.
- Append - if existing data is found in the fully-specified partition, data will be appended to it.
- Replace - if existing data is found in the fully-specified partition, it will be replaced. This does not replace all data for a column partition value, just the data in the fully-specified partition. Import Source: This is the import source section of the associated schema file that specifies how source data columns will be set as Deephaven columns.
- Strict Import will fail if a file being imported has missing column values (nulls), unless those columns allow or replace the null values using a default attribute in the
ImportColumndefinition.
- XML File Reading Settings:
- Use Elements - Take import values from the contents of XML elements. At least one of Use Elements or Use Attributes must be selected.
- Use Attributes - Take import values from the values of XML attributes. At least one of Use Elements or Use Attributes must be selected.
- Named Values - When checked, element or attribute names are used for column names; when cleared, values will be assigned to columns positionally in the order they are found. Note that positional values will be parsed from the XML in the order of the columns in the table. As such, the table schema for documents that do not used Named Values, must closely match the layout of columns in the XML document.
- Data:
- Start Index - The number of the element, starting with the root itself (0), from the root of the XML document where the importer will expect to find data.
- Start Depth - How many level down, under the Start Index element, the importer should traverse to find data elements.
- Max. Depth - When data elements may contain data in child elements, this determines how many levels further down the importer should traverse while looking for import values.
- Element Type - The string name of the data element type. In some cases, this may be a / delimited path to the types of elements that should be imported.
- Single/Multi Partition: This controls the import mode. In single-partition, all of the data is imported into a single Intraday partition. In multi-partition mode, you must specify a column in the source data that will control to which partition each row is imported.
- Single-partition configuration:
- Partition Formula: This is the formula needed to partition the XML being imported. If a specific partition value is used it will need to be surrounded by quotes. For example:
currentDateNy()"2017-01-01" - Partition Substitution: This is a token used to substitute the determined column partition value in the source directory, source file, or source glob, to allow the dynamic determination of these fields. For example, if the partition substitution is "PARTITION_SUB", and the source directory includes "PARTITION_SUB" in its value, that PARTITION_SUB will be replaced with the partition value determined from the partition formula.
- Substitution Date Format: This is the date format that will be used when a Partition Substitution is used. The standard Deephaven date partition format is
yyyy-MM-dd(e.g., 2018-05-30), but this allows substitution in another format. For example, if the filename includes the date inyyyyddMMformat instead (e.g., 20183005), that could be used in the Date Substitution Format field. All the patterns from the JavaDateTimeFormatterclass are allowed.
- Partition Formula: This is the formula needed to partition the XML being imported. If a specific partition value is used it will need to be surrounded by quotes. For example:
- Multi-partition configuration:
- Import Partition Column: This is the name of the database column used to choose the target partition for each row (typically "Date"). There must be an corresponding Import Column present in the schema, which will indicate how to get this value from the source data.
- Single-partition configuration:
- Source Directory: This is the path to where the XML file is stored on the server on which the query will run.
- Source File: This the name of the XML file to import.
- Source Glob: This is an expression used to match multiple XML file names.
- Constant Value: A String of data to make available as a pseudo-column to fields using the CONSTANT sourceType.
In most cases, it will be easier to test XML parsing settings using the Discover Schema from XML option of the Schema Editor utility. This allows a quick preview of the results of different settings, so the correct index, element type, etc, can be easily determined.
Importing Using Builder
Example
The following script imports a single XML file to a specified partition. This import uses options consistent with the XML Quickstart example.
Import API Reference
The XML import class provides a static builder method, which produces an object used to set parameters for the import. The builder returns an import object from the build() method. Imports are executed via the run() method and if successful, return the number of rows imported. All other parameters and options for the import are configured via the setter methods described below. The general pattern when scripting an import is:
XML Import Options
| Setter Method | Type | Req? | Default | Description |
|---|---|---|---|---|
setSourceDirectory | String | No* | N/A | Directory from which to read source file(s).. |
setSourceFile | String | No* | N/A | Source file name (either full path on server filesystem or relative to specified source directory). |
setSourceGlob | String | No* | N/A | Source file(s) wildcard expression. |
setDelimiter | char | No | , | Allows specification of a character when parsing string representations of long or double arrays. |
setElementType | String | Yes | N/A | The name or path of the element that will contain data elements. This will be the name of the element which holds your data. |
setStartIndex | int | No | 0 | Starting from the root of the document, the index (1 being the first top-level element in the document after the root) of the element under which data can be found. |
setStartDepth | int | No | 1 | Under the element indicated by Start Index, how many levels of first children to traverse to find an element that contains data to import. |
setMaxDepth | int | No | 1 | Starting from Start Depth, how many levels of element paths to traverse and concatenate to provide a list that can be selected under Element Name. |
setUseAttributeValues | boolean | No | false | Indicates that field values will be taken from attribute value; e.g., <Record ID="XYZ" Price="10.25" /> |
setUseElementValues | boolean | No | true | Indicates that field values will be taken from element values; e.g., <Price>10.25</> |
setPositionValues | boolean | No | false | When false, field values within the document will be named; e.g., a value called Price might be contained in an element named Price, or an attribute named Price. When this option is included, field names (column names) will be taken from the table schema, and the data values will be parsed into them by matching the position of the value with the position of column in the schema. |
setConstantColumnValue | String | No | N/A | A String to materialize as the source column when an ImportColumn is defined with a sourceType of CONSTANT. |
* The sourceDirectory parameter will be used in conjunction with sourceFile or sourceGlob. If sourceDirectory is not provided, but sourceFile is, then sourceFile will be used as a fully qualified file name. If sourceDirectory is not provided, but sourceGlob is, then sourceDirectory will default to the configured log file directory from the prop file being used.
Import from Command Line
XML imports can be performed directly from the command line, using the iris_exec tool.
Command Reference
XML Import Arguments
The XML importer takes the following arguments:
| Argument | Description |
|---|---|
| Either a destination directory, specific partition, or internal partition plus a partition column must be provided. A directory can be used to write a new set of table files to specific location on disk, where they can later be read with TableTools. A destination partition is used to write to intraday locations for existing tables. The internal partition value is used to separate data on disk; it does not need to be unique for a table. The name of the import server is a common value for this. The partitioning value is a string data value used to populate the partitioning column in the table during the import. This value must be unique within the table. In summary, there are three ways to specify destination table partition(s):
|
-ns or --namespace <namespace> | (Required) Namespace in which to find the target table. |
-tn or --tableName <name> | (Required) Name of the target table. |
-fd or --delimiter <delimiter character> | Field Delimiter (Optional). Allows specification of a character to be used when parsing string representations of long or double arrays. |
-xi or --startIndex | Starting from the root of the document, the index (1 being the first top-level element in the document after the root) of the element under which data can be found. |
-xd or --startDepth | Under the element indicated by Start Index, how many levels of first children to traverse to find an element that contains data to import. |
-xm or --maxDepth | Starting from Start Depth, how many levels of element paths to traverse and concatenate to provide a list that can be selected under Element Name. |
-xt or --elementType | The name or path of the element that will contain data elements. |
-ev or --useElementValues | Indicates that field values will be taken from element values e.g., <Price>10.25</>. |
-av or --useAttributeValues | Indicates that field values will be taken from attribute value, e.g., <Record ID="XYZ" Price="10.25" />. |
-pv or --namedValues | When omitted, field values within the document will be named, e.g., a value called Price might be contained in an element named Price, or an attribute named Price. When this option is included, field names (column names) will be taken from the table schema, and the data values will be parsed into them by matching the position of the value with the position of column in the schema. |
-om or --outputMode <import behavior> | (Optional):
|
-rc or --relaxedChecking <TRUE or FALSE> | (Optional) Defaults to FALSE. If TRUE, will allow target columns that are missing from the source XML to remain null, and will allow import to continue when data conversions fail. In most cases, this should be set to TRUE only when developing the import process for a new data source. |
| sourceDirectory, sourceFile, and sourceGlob are all optional. If none of these are provided, the system will attempt to do a multi-file import. Otherwise, sourceDirectory will be used in conjunction with sourceFile or sourceGlob. If sourceDirectory is not provided, but sourceFile is, then sourceFile will be used as a fully qualified file name. If sourceDirectory is not provided, but sourceGlob is, then sourceDirectory will default to the configured log file directory from the prop file being used. |
-sn or --sourceName <ImportSource name> | Specific ImportSource to use. If not specified, the importer will use the first ImportSource block that it finds that matches the type of the import (CSV/XML/JSON/JDBC). |
One special case when importing XML data is columns in the target table with a type of Boolean.
- By default, the XML importer will attempt to interpret string data from the source table with 0, F, f, or any case of false, being written as a Boolean false.
- Similarly, 1, T, t, or any case of true would be a Boolean true.
- Any other value would result in a conversion failure that may be continuable, if, for instance, a default is set for the column.
- To convert from other representations of true/false, for example from foreign language strings, a formula or transform would be needed, along with a
sourceType="String"to ensure the reading of the data from the XML value is handled correctly.