Importing streaming data
While batch data is imported in large chunks, ticking data (or streaming data) is appended to an intraday table on a row-by-row basis as it arrives. Ticking data is also different from batch data in how Deephaven handles it. Normally, batch data that is imported to a partition with today's date is not available to users. The expectation is that such data will first be merged and validated before users should access it. Ticking data, on the other hand, is immediately delivered to users as new rows arrive. The quality of this newest data may be lower than that of historical data but having access to information with low latency is generally more important for ticking sources.
Another difference between batch and ticking data is that there are no general standards for ticking data formats. CSV, JDBC, JSON, and others provide well-known standards for describing and packaging sets of batch data. However, ticking data formats do not have such accepted standards, so there is often some custom work involved in adding a ticking data source to Deephaven.
Typical steps in adding a streaming data source to Deephaven:
- Create the base table schema.
- Add a
LoggerListenersection to the schema. - Deploy the schema.
- Generate the logger and listener classes.
- Create a logger application that will use the generated logger to send new events to Deephaven.
- Edit the host config file to add a new service for the tailer to monitor.
- Edit the tailer config file to add entries for the new files to monitor.
- Restart the tailer and DIS processes to pick up the new schema and configuration information.
The last three steps above apply only if deploying a new tailer. If the standard Deephaven Java logging infrastructure is used (with log file names that include all the details needed for the tailer to determine its destination), the existing system tailer should pick up new tables automatically.
Process overview
In addition to specifying the structure of the data in a table, a schema can include directives that affect the ingestion of live data. This section provides an overview of this process followed by details on how schemas can control it. Example schemas are provided as well.
Streaming data ingestion is a structured Deephaven process where external updates are received and appended to intraday tables. In most cases, this is accomplished by writing the updates into Deephaven's binary log file format as an intermediate step.
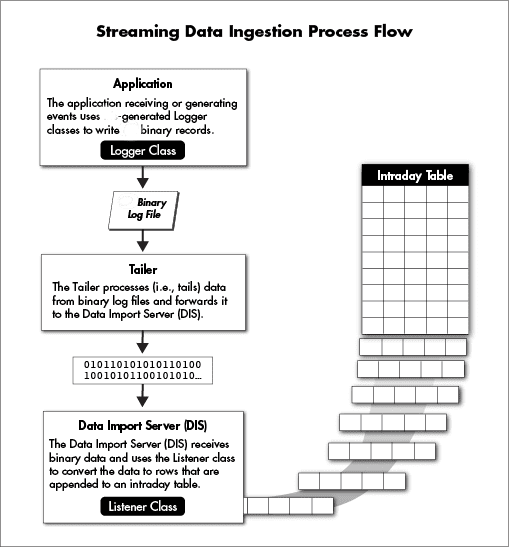
To understand the flexibility and capabilities of Deephaven table schemas, it is important to understand the key components of the import process. Each live table requires two custom pieces of code, both of which are generated by Deephaven from the schema:
- a logger, which integrates with the application producing the data.
- a listener, which integrates with the Deephaven Data Import Server (DIS).
The logger is the code that can take an event record and write it into the Deephaven binary log format, appending it to a log file. The listener is the corresponding piece of code that can read a record in Deephaven binary log format and append it to an intraday table.
The customer application receives data from a source such as a market data provider or application component. The application uses the logger to write that data in a row-oriented binary format. For Java applications or C#, a table-specific logger class is generated by Deephaven based on the schema. Logging from a C++ application uses variadic template arguments and does not require generated code. This data may be written directly to disk files or be sent to an aggregation service that combines it with similar data streams and then writes it to disk.
The next step in streaming data ingestion is a process called the tailer. The tailer monitors the system for new files matching a configured name and location pattern, and then monitors matching files for new data being appended to them. As data is added, it reads the new bytes and sends them to one or more instances of the Data Import Server (DIS). Other than finding files and "tailing" them to the DIS, the tailer does very little processing. It is not concerned with what data is in a file or how that data is formatted. It simply picks up new data and streams it to the DIS.
The Data Import Server receives the data stream from the tailer and converts it to a column-oriented format for storage using the listener that was generated from the schema. A listener will produce data that matches the names and data types of the data columns declared in the "Column" elements of the schema.
Loggers and listeners are both capable of converting the data types of their inputs, as well as calculating or generating values. Additionally, Deephaven supports multiple logger and listener formats for each table. Together, this allows Deephaven to simultaneously ingest multiple real-time data streams from different sources in different formats to the same table.
Logging Data
The Logger Interfaces
The customer application might have "rows" of data to stream in two main formats:
- sets of values using basic data types like double or String, and
- complex objects that are instances of custom classes.
The generated logger class will provide a log method that will be called each time the application has data to send to Deephaven, with its arguments based on the schema. To create the format for the log method, the logger class will always implement a Java interface. Deephaven provides several generic interfaces based on the number of arguments needed. For instance, if three arguments are needed, by default the Deephaven generic ThreeArgLogger is used. These arguments might be basic types such as double or String, custom class types, or a combination of both.
Deephaven provides generic logger interfaces for up to eight arguments, plus a special MultiArgLogger interface for loggers with more than eight arguments. The MultiArgLogger is more generic than the other interfaces in that the other interfaces will have their arguments typed when the logger code is generated, while the MultiArgLogger will simply take an arbitrarily long list of objects as its arguments. One known limitation of the MultiArgLogger is that it cannot accept generic objects among its arguments. In this case "generic objects" refers to objects other than String or boxed primitive types. The logger interfaces for fixed numbers of arguments do not have this limitation.
In many cases the events to be logged will have a large number of properties. Rather than use the MultiArgLogger there are two other approaches that are preferred: either create a custom logger interface or pass the event as a custom object.
In most cases the custom object is the easier solution, since such an object probably already exists in the API of the data source from which the custom application is receiving data. For example, if the custom application is receiving Twitter tweets as tweet objects, this object type could be added to the schema as a SystemInput, and Tweet properties could be used in the intradaySetters:
This way, the customer application only needs to pass a Tweet object to the log() method instead of having to pass each of the properties of the object.
Custom Logger Interfaces
The other option for logging more than eight properties is to define a custom logger interface. A custom logger interface extends IntradayLogger and specifies the exact names and types of arguments to be passed to the log() method:
Note the timestamp argument. This column is often included in Deephaven tables to track when a logger first "saw" a row of data. By default, this is "now" in epoch milliseconds at the time the event was received. If needed, a custom intradaySetter and dbSetter can be specified to use other formats or precisions for this value.
A custom logger interface should specify any exceptions the log() method will throw. For instance, a logger that handles BLOB arguments will need to include throws IOException as part of its log(...) method declarations:
In this case, the "1" in the name (TickDataLogFormat1Interface) is to denote this is the first version of this interface, which is helpful if we later need to revise it. This is convention and recommended, rather than an enforced requirement in naming logger interfaces.
Log Formats
Each logger and listener corresponds to a distinct version number, which is specified in a logFormat attribute when
defining a logger or listener in the schema. A listener will only accept data that has been logged with a matching
column set and version number. Log formats are helpful when making schema modifications: if columns are added or removed,
additional logger/listener elements can be added to support the new set of columns as a new log format, without losing
support for binary logs generated using earlier versions of the schema. The existing logger/listener elements can be
updated to ignore the new columns — for example, a new column can be excluded from loggers for an older log format by
setting intradayType="None", and default values for the new columns be configured within the listener by setting the
dbSetter attribute (such as dbSetter=NULL_LONG).
If a log format version is not specified, it will default to "0".
Loggers in Deephaven Schemas
Loggers are defined in a <Logger> element, only required when a Java or C# logger is needed. A logger element has the
following attributes:
| Element Name | Optional/Required | Default | Description |
|---|---|---|---|
logFormat | Optional | 0 | Specifies the logger's version number. |
loggerPackage | Required | N/A | Specifies the Java package for the generated code. |
loggerClass | Optional | Generated from logFormat and table name | Specifies the Java class name for the generated code; defaults to a value that includes the table name and log format version (if non-zero); e.g., TestTableLogger, TestTableFormat2Logger. If specified, the value (class name) must include "Logger" somewhere within its definition. |
loggerInterface | Optional | Determined from SystemInput elements | Specifies a Java interface that the generated logger class will implement. Defaults to a generic interface based on the number of system input parameters; e.g., com.illumon.intradaylogger.FourArgLogger. The class name must include the word "Logger". |
loggerInterfaceGeneric | Optional | N/A | The use of this attribute is deprecated. |
loggerLanguage | Optional | JAVA | Specifies the logger language. If not specified, a default value of JAVA will be used. Supported values are:- JAVA - CSHARP or C# |
tableLogger | Optional | false | If specified as true this indicates that a logger should be generated that can write data directly to a Deephaven table. |
verifyChecksum | Optional | true | If specified as false then the logger loaded by a logging application will not be checked against the latest logger generated by the schema. This configuration is not recommended. |
Logger code generation elements
Logger code generation is supplemented by the following elements:
| Element Name | Optional/Required | Description |
|---|---|---|
<LoggerImports> | Optional | Specifies a list of extra Java import statements for the generated logger class. |
<LoggerFields> | Optional | Specifies a free-form block of code used to declare and initialize instance or static members of the generated logger class. |
<SystemInput> | Required unless the loggerInterface attribute was specified | Declares an argument that the Logger's log() method will take, with two attributes:- name - the name of the argument, available as a variable to intradaySetter expressions.- type - the type for the argument; any Java type including those defined in customer code. |
<ExtraMethods> | Optional | If specified, these are extra methods added to the generated logger class. |
<SetterFields> | Optional | If specified, these are extra fields (variables) added to the setter classes within the generated logger. |
The application should call the log() method once for each row of data, passing the data for the row as arguments.
Logger interfaces
All generated loggers must implement the com.illumon.intradaylogger.IntradayLogger interface, which defines the
base methods required of a Deephaven logger. This does not include the log() method that is actually used by
applications for logging data.
Generated loggers will automatically implement an interface that defines a log() method that takes as many arguments
as there are <SystemInput> elements. There are specific interfaces for up to eight input parameters; beyond that,
the MultiArgLogger interface is used, which defines a varargs log() method.
| Interface | Signature of log() method |
|---|---|
com.illumon.intradaylogger.OneArgLogger | log(T1 value) throws IOException |
com.illumon.intradaylogger.FourArgLogger | log(T1 value1, T2 value2, T3 value3, T4 value4) throws IOException |
com.illumon.intradaylogger.MultiArgLogger | log(Object... values) throws IOException |
These interfaces can be used to develop applications that must log data, but do not have access to the generated logger code at compile time.
Custom logger interfaces
Custom logger interfaces are helpful because they allow application development with a log() method specific to the
intended argument types, without generating copies of the logger on the development workstation (e.g., when not
developing with the Deephaven Gradle plugin). This allows logger
interfaces with a log() method that can take primitive arguments (rather than only Java Objects) and that can have
more than eight method arguments (without using varargs). For some cases of high-throughput logging, using Java boxed
types instead of primitive types (such as java.lang.Double instead of double) can adversely affect performance. This
is true of varargs calls as well, since Java varargs calls require copying all arguments into a new array.
A custom logger interface must extend the IntradayLogger interface and define a log() method whose signature matches
the <SystemInput> elements. Specifically:
- The
log()method in the custom interface must have the same number of arguments as there are<SystemInput>elements for the log format. - The
typeof each<SystemInput> must match the argument types in the custom interface'slog()method for the same position. For example, if thelog()method's signature islog(char myFirstVal, Number mySecondVal), then thetypeof the first<SystemInput>must bebyte, and thetypeof the secondSystemInputmust be aNumberor a subclass ofNumber(such asInteger,Double, orBigInteger).
See Appendix F for an example custom logger interface.
Logger <Column> elements
The <Column> elements declare the columns contained in the logger's output. A logger's column set typically matches the destination table's column set, but this is not a requirement, as the listener can convert the data from the logger's format to the columns required for the table. Each column in the table's Column set must exist in the Logger Column elements.
The <Column> element for a logger supports the following attributes:
| Attribute Name | Optional/Required | Description |
|---|---|---|
datePartitionInput | Optional | Specifies that if the logger is Java, the column's value can be used to automatically calculate the column partition value for every logged row. The column's time precision must be specified in the attribute. Available values include: - seconds - millis - micros - nanos To use this option the logging program must initialize the logger with an appropriate time zone name. See the Dynamic Logging Example. |
directSetter | Optional | A Java expression that uses the logger arguments as inputs to produce the value to be used in this column. This should be set whenever the intradaySeter is set. The directSetter should produce the same result for a column as the corresponding dbSetter in the listener for this log format. To automatically use the intradaySetter expression as the directSetter, use the special value "matchIntraday". |
intradayType | Optional | The data type for values in the log, which may be different from the dataType for the Column. If intradayType is not specified, then the column' s dataType is used. An intradayType of none indicates that this column should not be included in the log. |
intradaySetter | Required | A Java expression to produce the value to be used for this column in the binary log file. This can customize how a value from the logging application should be interpreted or converted before writing it into the binary log file. The expression may use the names of any <SystemInput> elements as variables and perform valid Java operations on these variables. The expression must return a value of the intradayType. |
functionPartitionInput | Optional | If set to true, this attribute specifies that if the logger is Java, the column's value can be used to calculate the column partition value for every logged row by using a lambda provided in the logger initialization. To use this option the logging program must initialize the logger with an appropriate lambda. See the Dynamic Logging Example. |
name | Required | The name of the column in the logger's output. A corresponding <Column> element with the same name must exist in the listener that corresponds to the logger's logFormat version. |
partitionSetter | Optional | This attribute is only valid for the partitioning column. It specifies that the value will be specified by a dynamic-partitioning function using a defined system input specified by the directSetter attribute. Without this attribute, the value passed to a functionPartitionInput is taken from a stored column, but this allows it to be passed to the function without linking it to another column's data. For example, if DataType was the partitioning column, a system input with the name dataType could be passed to the dynamic partition function as follows: |
If a logger depends on a customer's classes, those classes must be present in the classpath both for logger generation (as it is required for compilation) and at runtime.
If a logger uses column partition values that are calculated for each row, it will only allow a limited number of open partitions at any time. If this number is exceeded, the least-recently-used partition will be closed before the new one is opened. If a large number of partitions are expected to be written to at any time, the default number of open partitions may not be sufficient, as quick rollover of partitions will cause the creation of a lot of new files or network connections. These values can be configured with the following properties:
MultiPartitionFileManager.maxOpenColumnPartitions- this is for loggers writing directly to binary log files. The default value is 10.logAggregatorService.maxOpenColumnPartitions- this is for loggers writing through the Log Aggregator Service. The default value is 10.
The following is an example logger for the basic example table in the Table and Schemas documentation.
Note the use of intradaySetter expressions to modify the logged data. These transformations are applied in the logging
application when the client code calls the log(). When an intradaySetter is specified, the output data in the binary
log file will reflect the data transformed via the setter expression, rather than the raw input passed to the log()
method.
This example logger also excludes the Echo column; a default value will have to be populated via the dbSetter in the
listener. See object serialization with autoblob for an example of logging
arbitrary Java objects (such as java.util.List).
Listeners in Deephaven Schemas
Listeners are defined in a <Listener> element.
A listener element has the following attributes:
| Element Name | Optional/Required | Default | Description |
|---|---|---|---|
logFormat | Optional | 0 | Specifies the logger's version number. |
listenerPackage | Optional | <SchemaConfig.defaultListenerPackagePrefix>.<namespace> | Specifies the Java package for the generated code. Defaults to the value of the SchemaConfig.defaultListenerPackagePrefix configuration property with the namespace converted to lowercase and appended (e.g., com.mycompany.testnamespace). |
listenerClass | Optional | Generated from logFormat and table name | Specifies the Java class name for the generated code. Defaults to a value that includes the table name and log format version (if non-zero); e.g., TestTableListener, TestTableFormat2Listener. The class name must include the word "Listener". |
Listener code generation elements
Listener code generation is supplemented by three elements:
<ImportState>- Optional – Specifies a state object used for producing validation inputs, with two attributes:importStateType- Required - a full class name, must implement thecom.illumon.iris.db.tables.dataimport.logtailer.ImportStateinterface.stateUpdateCall- required - a code fragment used to update the import state per row which may reference column names or fields; e.g.,newRow(Bravo).
| Element Name | Optional/Required | Description |
|---|---|---|
<ListenerImports> | Optional | Specifies a list of extra Java import statements for the generated listener class. |
<ListenerFields> | Optional | Specifies a free-form block of code used to declare and initialize instance or static members of the generated listener class. |
<ImportState> | Optional | Specifies a state object used for tracking additional state associated with the import (such as the position of the latest ingested row for each value in a key column). See import states for more details. |
Listener <Column> elements
Each <Listener> element contains an ordered list of <Column> elements. The <Column> elements declare both the columns expected in the data from the logger and the columns to write to the table. The <Column> elements for a listener support the following attributes:
name- Required – The name of the column. A column of this name does not necessarily need to exist in the table itself.dbSetter- Optional, unlessintradayTypeisnone– A Java expression to produce the value to be used in this column. This can customize how a raw value from the binary log file is interpreted when writing into a Deephaven column. The expression may use any fields or column names as variables, except columns for whichintradayTypeisnone.intradayType- Optional (defaults todataType) – The data type of this column as written by the logger. Use none if a column is present in the table but not in the logger's output - if this is the case, adbSetterattribute is required. This attribute is only required when the logger uses a different data type than the table itself.
DBDateTime
One special case is the DateTime or DBDateTime data type. (DateTime is an alias for Deephaven's DBDateTime type, which
is a datetime with nanosecond precision.) It is stored internally as nanoseconds from epoch. However, by default,
listener code will assume that a DBDateTime is logged as a long value in milliseconds from epoch (such as from
Java's System.currentTimeMillis() method). If the value provided by the logger is something other than milliseconds
from epoch, a custom setter must be specified in the dbSetter attribute.
For example:
dbSetter="com.illumon.iris.db.tables.utils.DBTimeUtils.nanosToTime(LoggedTimeNanos)"
In this case, the logging application is providing a long value of nanoseconds from epoch using the column name of LoggedTimeNanos.
The following is an example listener for the basic example table in the Table and Schemas documentation:
Combined Definition of Loggers and Listeners
It is possible to declare a Logger and Listener simultaneously in a <LoggerListener> element. A <LoggerListener> element requires both a listenerPackage attribute (assuming the default listener package name is not to be used) and a loggerPackage attribute. The <Column> elements declared under the <LoggerListener> element will be used for both the logger and the listener. This is useful as it avoids repetition of the <Column> elements.
An example of a <LoggerListener> declaration for the example table is provided below.
Combined Definitions of Table, Loggers, and Listeners
In past Deephaven releases, some schemas controlled code generation from the <Column> elements declared for the <Table>, without explicitly declaring the columns under a <Logger>, <Listener>, or <LoggerListener> attribute. The attributes normally defined on a <Column> element within <Logger>, <Listener>, or <LoggerListener> block were placed on the same <Column> elements used to define the table itself. This type of schema has been deprecated, as it does not allow for multiple logger or listener versions, or for maintaining backward compatibility during schema modifications.
Import States
Import states are extensions to the data ingestion infrastructure that allow additional state to be recorded as the data is ingested.
| Attribute | Description |
|---|---|
importStateType | The ImportState implementation to create. |
stateUpdateCall | The code to call for each new row that is ingested. Any columns available in the log file (i.e., columns whose intradayType is not "none") may be used as variables in this expression (as with the dbSetter attribute for listeners). |
Generating loggers
Introduction
Streaming data ingestion by Deephaven requires a table structure to receive the data, generated logger classes to format data and write it to binary log files, generated listeners used by Deephaven for ingestion, and processes to receive and translate the data. The main components are:
- Schemas — XML used to define table structure for various types of tables. These are described in detail in Schemas.
- Loggers — Generated class code that will be used by the application to write the data to a binary log, or to the Log Aggregator Service.
- Log Aggregator Service (LAS) — A Deephaven process that combines binary log entries from several processes and writes them into binary log files. The loggers may instead write directly to log files without using the LAS.
- Tailer — A Deephaven process that reads the binary log files as they are written and streams the data to a Data Import Server (DIS).
- [Data Import Server (DIS)] — A Deephaven process that efficiently writes streaming data to disk while distributing it over the network to downstream clients (such as queries).
- Listeners — Generated Java classes used in the DIS to convert the binary entries sent by the tailer into the appropriate columnar format for the target intraday table.
The logger and the listener work together, and both are generated based on the table's schema. The logger converts elements of discrete data into the Deephaven row-oriented binary log format, while the listener converts the data from the binary log format to Deephaven's column-oriented data store.
Although the typical arrangement is to stream events through the logger, tailer, and listener into the intraday tables as they arrive, there are also applications where only the logger is used, and the binary log files are manually imported when needed. The corresponding listener is then used when that later import is run.
Customers can generate custom loggers and listeners based on the definitions contained in schemas, and this will be
required to use the streaming data ingestion described above. Logger generation is normally done through the use of
the generate_loggers script, provided as part of the software installation. Listeners are generated dynamically when
needed.
When Deephaven loads a logger class, it will first verify that the class matches the current schema for the table in
question. An error will occur if the logger class is not compatible with the current schema — for example, if it was
generated based on an earlier version of the schema. Accordingly, whenever a table schema is modified and redeployed
(e.g., with the dhconfig schema import command or the schema editor), any related
loggers must also be recreated.
generate_loggers Script
Once the schemas are defined, the generate_loggers script will normally be used to generate logger classes. It finds schemas, generates and compiles Java files based on the definitions in these schemas, and packages the compiled .class files and Java source files into two separate JAR files which can be used by the application and Deephaven processes, or by the customer for application development. The IntradayLoggerFactory class is called to perform the actual code generation, and it uses the properties described above when generating the logger and listener code.
To use it with default behavior, simply call the script without any parameters, and it will generate the loggers for any customer schemas it finds through the schema service. It will also generate listener classes and compile them to ensure that schemas are valid, but it won't save the generated listener code.
The simplest way to call this script is:
This call will generate all loggers that are not internal Deephaven ones, and place a default jar file in a location where it will be accessible to the application.
The script will use several default options based on environment variables in the host configuration file's generate_loggers entry.
ILLUMON_JAVA_GENERATION_DIR- the directory into which the generated Java files will be placed. If this is not supplied, then the directory$WORKSPACE/generated_javawill be used. This can also be overridden with thejavaDirparameter as explained below. Two directories will be created under this directory:build_generated- used to generate the compiled Java class files.java- used to hold the generated Java code.
A typical value for this is: export ILLUMON_JAVA_GENERATION_DIR=/etc/sysconfig/illumon.d/resources:
ILLUMON_CONFIG_ROOTindicates the customer configuration root directory. If defined, the script copies the generated logger/listener JAR file to the java_lib directory under this. A typical value for this is:export ILLUMON_CONFIG_ROOT=/etc/sysconfig/illumon.d.ILLUMON_JAR_DIR- the directory in which the generated JAR files will be created. If it is not defined, then the workspace directory will be used. This is not the final location of the generated JAR file that contains the compiled .class files, as it is copied based on theILLUMON_CONFIG_ROOTenvironment variable. The JAR file that contains the logger Java sources is not copied anywhere.
Several options are available to provide flexibility in logger/listener generation. For example, a user could generate loggers and listeners from non-deployed schema files for use in application development:
-
outputJar- specifies the filename of the JAR file generated by the logger/listener script. If the parameter is not provided, the default JAR file name isIllumonCustomerGeneratedCode.jar. -
packages- a comma-delimited list which restricts which packages will be generated. If a logger or listener package doesn't start with one of the specified names, generation will be skipped for that logger or listener. If the parameter is not provided, all loggers and listeners for found schema files will be generated. Customer logger and listener packages should never start withcom.illumon.iris.controller,com.illumon.iris.db, orio.deephaven.iris.db, as these are reserved for internal use. -
javaDir- specifies the directory which will be used to write generated Java files. A logs directory must be available one level up from the specifiedjavaDirdirectory. If the parameter is not provided, the directorygenerated_javaunder the workspace will be used. In either case, under this directory a subdirectorybuild_generatedwill be used to contain compiled .class files, and this subdirectory will be created if it does not exist. -
schemaDir- specifies a single directory to search for schema files. The specified location is searched for schema files. If this parameter is provided, the schema service is not used to retrieve schemas; instead, only the location specified by this parameter is used. Especially combined withjarDir, this may be useful to test logger and listener generation before deploying a schema and the associated loggers and listeners. Note: This directory must be readable by the user that will run the command, usuallyirisadmin. -
jarDir- specifies a directory to hold the generated JAR file. If the parameter is not provided, then the workspace directory (as defined in the host configuration file) will be used. The generated JAR file will always be copied to a location specified by$ILLUMON_CONFIG_ROOT/java_lib, which defaults to a location where the Deephaven application will find it (currently/etc/sysconfig/illumon.d/java_lib). -
javaJar- specifies a JAR file in which the generated logger source (java) files will be placed. This will be placed in the same directory as the generated JAR file. If the parameter is not specified, then a JAR file with the name "IllumonCustomerGeneratedCodeSources.jar" will be created. -
listenerCreationOptions- by default, thegenerate_loggersscript generates and compiles listener classes to verify that they can be created from the schemas, but does not write the class code. This behavior can be overridden.-
listenerCreationOptions=COMPILE_ONLY- creates the listener classes and try to compiles them but does not write Java files (this is the default). -
listenerCreationOptions=CREATE_JAVA_FILES- creates the listener java files. -
listenerCreationOptions=SKIP- does not attempt to create or compile listener classes.
-
For example, the following command will generate a logger/listener jar using several custom options:
- The
WORKSPACEenvironment variable will be used to store temporary files (in this case,/home/username/workspace, which must already exist). - The
ILLUMON_JAVAenvironment variable tells it where to find Java. - The
JAVA_HOMEenvironment variable tells it where to find the JDK. -d /usr/illumon/latest/indicates where Deephaven is installed.-f iris-common.propindicates the property file to use (this is a common property file that will exist on most installations).-j -Dlogroot=/home/username/logsindicates the root logging directory; logs will be placed in subdirectories under this directory, which should already exist.- The
schemaDirparameter tells it to look for schema files in the directory/home/username/schema, instead of using the schema service. - The
outputJarparameter tells it to generate a JAR with the name "test.jar". - The
packagesparameter tells it to only generate classes that start with packagescom.customer.gen. - Because it is only operating out of the user's directories it can be run under the user's account.
Note: in this example we are calling generate_loggers directly, rather than through /usr/illumon/latest/bin/iris.
If the generation process completes correctly, the script will show which Java files it generated and indicate what was added to the JAR files. The final output should be similar to the following:
Generating loggers for local development
When developing locally (i.e., building or running on your desktop/laptop), Deephaven's Gradle plugin can automatically
generate logger classes based on locally-available schema files. This allows code to be written and compiled based on
the columns in local versions of the schema files, rather than the schemas deployed to the server. Typically, the schema
files are stored in git alongside the code that depends on them. The locally-generated loggers are used during
compilation and local execution, but are not packaged into .jar files that are deployed on the server, since
the server will already have versions of the loggers generated from the generate_loggers script.
Please see the section on local query development for more details.
Column codecs in loggers and listeners
If a column codec is used when reading a column, the codec generally should be integrated into the logger and listener as well. This requires three changes to both the logger and the listener:
- Importing the codec class into the logger and listener in the
LoggerImportsandListenerImportselements. - Instantiating the codec class in the
LoggerFieldsandListenerFieldselements. Note that codecs may take constructor arguments that influence their behavior (such as configuring caching or buffer sizes). - Updating the
intradaySetter/directSetterfor the column in the logger, and thedbSetterin the listener, to call the codec'sencode()/decode()methods when writing/reading the data.
Additionally, the logger's intradayType for the column must be set to "Blob" to set the column's expected data type in
the binary log file.
For example, the following schema uses codecs to efficiently store byte array, BigDecimal, and BigInteger objects
(the Foxtrot, Echo, and Golf columns).
Object serialization with autoblob
In addition to custom column codecs, Deephaven loggers/listeners can handle any serializable Java object by enabling autoblob. Autoblob serialization is controlled by setting the following properties:
| Attribute Name | Optional/Required | Default | Description |
|---|---|---|---|
autoBlobInitSize | Optional | -1 (disabled) | The initial size to use for the serialization buffer. Setting this property enables autoblob. This should be large enough to fit the expected serialized size of the data. Setting this value too low will impact serialization performance, as data must be copied when the buffer is increased to a larger size. Setting this value too high may unnecessarily increase memory usage and the allocation rate, which may increase the JVM's garbage collector (GC) activity. |
autoBlobMaxSize | Optional | The maximum size the serialization buffer can grow to. If the serialized form of an object exceeds autoBlobMaxSize bytes, the logger will throw an exception. |
Dynamic Logging Example
This section provides a simple example to show how to define simple schemas that determine column partition values based on the logged data, and how to write Java loggers based on these schemas. This involves several steps:
- Define the schemas for the data to be logged.
- Deploy the schemas.
- Generate the Deephaven logger classes from these schemas.
- Create a Java class to log some data for these tables.
- Compile and run the Java class.
- Query the tables to see the logged data.
All of the examples work within a standard Deephaven installation. In customized installations, changes to some commands may be required.
Define the Schemas
For this example, two schemas are provided to illustrate the two dynamic logging options.
ExampleNamespace.LoggingDate.schema(see Appendix A) is for a table where the column partition value will be determined by each row's logged timestamp.ExampleNamespace.LoggingFunction.schema(see Appendix B) is for a table where the column partition value will be determined from each row's logged SomeData column.
The following lines create the schemas:
Import the Schemas
The schemas must be imported into the schema service so the infrastructure can access them.
Generate the Logger Classes
This step involves running the procedure that generates the Deephaven logger classes from the schemas. The logger classes will be used in the example to log some data, while the listener classes will be generated as-needed (not with this command) by the Deephaven infrastructure to load the data. The command will restrict the logger class generation to just the package named in the schema, and will give the generated JAR file a specific name to distinguish it from other generated JAR files.
The generated classes are visible in the newly generated file, which has been placed in a location where Deephaven expects to find customer JAR files:
Create the Java Logger Program
It is easiest to create, compile and run the program under the irisadmin account:
The program that runs the generated loggers is a simple Java class that can be found in Appendix C. In this manual process, we need to put it on the system, compile it, and run it. In a more realistic scenario, the generated JAR files will be copied over to an IDE, which will be used to develop the application.
Create the Java File
You may need to type the following command before pasting to avoid formatting issues:
When creating the Java program, note the following:
- The Deephaven
EventLoggerFactoryclass is used to create the intraday logger instances. This factory returns fully initialized loggers, set up to either write binary log files or to send data to the Log Aggregator Service based on properties. - When creating the
dateLogger(for rows that will have column partition values based on the timestamp field), note the use of a time zone. This will be used to determine the actual date for any given timestamp (a timestamp does not inherently indicate the time zone to which it belongs). - When creating the
functionLogger, note the lambda passed in the final parameter of thecreateIntradayLoggercall. This will use the first 10 characters of the SomeData column to determine the column partition value. Since a String can be null or empty, it uses a default value to ensure that an exception is not raised in this case. - The
fixedPartitionLoggeris created to write all data in a single column partition value, "2018-01-01". It will use the same table as the date logger.
For the actual log statements, hard-coded values are used.
Compile the Java Logger Program
Compile the Java code into a JAR file as follows:
Run the Compiled File
This is best done when logged in as the irisadmin account, which will still be the case if these example steps are being followed in order.
Use the iris_exec script to run the program. It will set up the classpath appropriately, and can include additional parameters. The first of these parameters will specify the LoggingExample class, while the second one tells the EventLoggerFactory to use the dynamic (row-based) partitioning. The -j tells the script that it is a Java parameters to be passed through to the JVM.
You can see the generated binary log files for the two tables with:
The location into which these logs are generated can be changed by updating the log-related properties as defined in the Log Files section of the Deephaven Operations Guide.
Query the Data
When logged in to a Deephaven console, the data can be queried with statements like the following examples, each of which looks at one of the partitions. The examples assume that the user has privileges to view the table.
Column rename example
This section provides an example on how to rename a column between the application log file and the table schema.
The table below has three columns (Date, Destination and SameName) while The logger has two columns (SameName and Source).
Datecolumn is not present in the log file, but rather determined by the logging process.SameNamecolumn is in both the log file and table schema, and does not need to be transformed.Sourcecolumn in the logger is renamed asDestinationin the table.
To rename Source column as Destination, the Listener class should include both Source and Destination columns and their attributes should be:
- Source: A value of
nonefordBSetterattribute. This indicates that the column is not present in the table. Additionally, the attributeintradayTypeshould be set to the appropriate dataType. - Destination: A value of
SourcefordBSetterto identify its input source. A valuenoneforintradayTypemeans it is not present in the log file, and cannot be used as part of adbSetter.
An example schema with only a Listener class defined is below:
For an example schema that includes Listener and Logger classes, see Appendix E
Appendix
Appendix A: Dynamic Date-Based Schema
Appendix B: Dynamic Function-Based Schema
Appendix C: Example Java Class
Appendix D: Java Compilation Script
Appendix E: Example schema to rename column
Appendix F: Example custom logger interface
Below is an example logger interface that can be used to