Supplementing historical data
In some cases it may be desirable to add historical data to previous dates without re-merging the data that already exists for these dates. Because Deephaven is an append-only database, supplemental data can extend existing data, but cannot replace it. An effective exception to this, though, is for tables that store data as point-in-time values; in this case, a lastBy would be used to get the latest version of a row, and supplementing historical data could add newer versions to return from the lastBy.
One example use case for supplementing historical data would be when a historical data set contains information for a set of symbols, and that set is to be expanded with some amount of backfill. In this case, the new data doesn't replace any existing data, but just adds more symbols for the historical dates.
See Table Storage and Merging Data for general background about how Deephaven stores historical data on disk.
For details on replacing individual columns of historical data, see Column Tools.
Importing and merging supplemental data
This section describes the process for adding data to existing historical partitions. This process is suitable for both Deephaven and Parquet format historical data.
In order to generate an additional data set that matches the layout of the historical data to be supplemented, it is easiest to use a separate namespace, with a table that uses a schema that is mostly a duplicate of the table to be supplemented. In this context, "mostly" means that the side-fill table must have the same names, types, and ordering of columns, and the same partitioning and grouping columns. However, the partitioning formula for the table can be different. Since the two tables are in different namespaces, they can (and should) have the same name. Using the same name for the two tables will simplify the process of moving the supplemental data into the storage of the main table.
If the data to be added is relatively small compared to the existing historical data (less than 10%), then it will generally be simplest to create the side-load namespace with a single internal partition.
In the illustration below, an existing historical table with ten internal partitions is being supplemented with data added to one internal partition in a separate namespace. Note that the internal partitions in the supplemental data's namespace should have names unique across the set of the two namespaces' internal partitions.
Important
If supplemental data is being added to provide newer "latest" values for rows, which will be selected using lastBy, then the naming of the new internal partition(s) becomes significant. Unsorted presentation of rows from disk is in the lexicographical order of their internal partition name, so, for supplemented rows to be presented later to the lastBy operator, they should be merged into internal partitions whose names sort after the original internal partitions of the permanent namespace. E.g. existing partitions 0 through 9, and new internal partition A, or A0, etc.
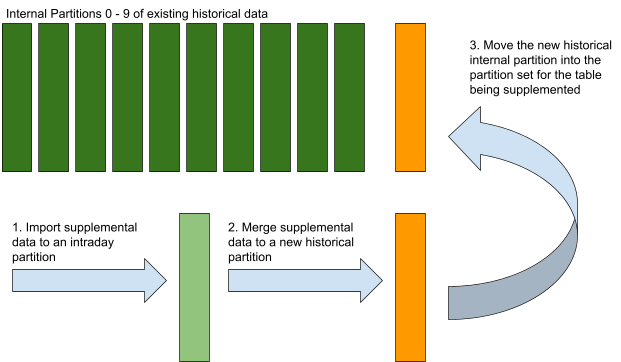
The overall process is:
- Import the data to be added to intraday for the side-fill table.
- Merge the side-fill table.
- Copy or move the partition from step 2 to a new internal partition for the table being supplemented. (If the base and side-fill tables have different names, then this step will also require renaming the level of the path just above the data.)
- Purge intraday data.
- Repeat 1 through 4 for each date that needs to be supplemented.
- Run the metadata indexer process to rebuild indexes for the base table namespace.
The metadata index from step 6 is a map of internal partitions and dates to accelerate the process of finding paths that are needed when querying across a table with many dates and internal partitions.
This process can be automated in a script that loops through a range of dates and uses the import, merge, and purge builder classes to process steps 1, 2, and 4. Step 3 can be automated to use Java or Python file system methods to execute directory move and rename operations.
Overall time to add data to a historical date via this process should be pretty close to the proportion of new data versus existing data, and the time that the original data took to process. For example, if the original import and merge process took 10 minutes, then adding 10% new data should take roughly 1 minute.
This process must be run in a merge worker, in order to have appropriate access to write new data to intraday and historical storage areas.
Note
Deephaven organizes internal partitions for a namespace by placing them in a Partitions directory. A peer of this directory is WritablePartitions.
- The query processor will look in the
Partitionsdirectory tree for data when reading. - The merge process will look for
WritableParititonswhen merging.
Typically, WritablePartitions subdirectories are linked to Partitions subdirectories so that all partitions are writable. When adding side-fill partitions to existing historical data, it is recommended to not link them as writable, so that only side-fill operations use those additional internal partitions.
Important
Each time data in a particular historical partition (date) needs to be supplemented, a new set of one or more internal partitions will be needed; i.e, if a date in a namespace with internal partitions 0 to 9 is supplemented to add some symbols using a temporary namespace with an internal partition called 0_incr, and, later, more data needs to be added to the same date, that new data will need to be merged into internal partitions with names other than the already used 0 to 9 and 0_incr. Alternatively, the supplemental partitions can be freed for reuse by re-merging the supplemented dates as outlined in the next section.
This example script is usable as a Groovy script to:
- run in a merge worker (console or persistent query) to iterate through a range of dates,
- import supplemental batch data from CSV files,
- merge them to a temporary namespace,
- move the internal partition(s) to the permanent namespace,
- and purge the imported intraday data.
This script should work with minor changes in a Java class as well. As written, the script expects CSV files that are compressed with GZip, with all files in the /tmp directory, and with the applicable date as part of the file name in the form yyyy-MM-dd.
Note
There is a use_parquet property, which defaults to false, which must be set to true when using the script with a table that is merged using Parquet format.
Click to see the full script.
Re-merging supplemented historical tables
Using the processes detailed above, the structure of supplemented tables on disk will be an initial set of WritablePartitions plus one or more read-only parititions that were added during one or more supplementation runs. If and when it becomes desirable to reorganize the historical data back to the core set of WritablePartitions, this can be accomplished by re-merging the data in place and then by deleting the read-only partitions' data for the re-merged date. More details about the steps involved in re-merging are covered in the Custom merge operations topic.
This script is similar to the example above in that it can be run in a merge worker (console or persistent query) and can also be adapted as a Java class with minor changes. This script also uses start and end dates to set a range of dates to be re-merged.
The script will re-merge one date at a time back into the original set of WritablePartitions for the namespace, and then delete supplemental data that was written into other non-writable partitions. Once all partitions have been merged, the script will update the metadata index for the table.
Important
The merge step in the script is restartable, but, if the script fails or is stopped after re-merging a date but before or during deletion of the non-writable partition data for that date, those non-writable partitions' data must be manually deleted. Restarting the script in this state could result in data duplication between the re-merged supplemental data, and the original supplemental data.
Note
There is a use_parquet property, which defaults to false, which must be set to true when using the script with a table that is merged using Parquet format.