Ingest batch data using wizards
The Schema Editor makes it easy to ingest batch data into Deephaven. Let's show you how.
Walkthrough
The following example shows the common steps in setting up schema and an import job for a new CSV batch data source.
We're using U.S. Federal College Scorecard data from www.data.gov. To follow along with this walk-through exactly, please download and unzip the CollegeScorecard_Raw_Data.zip file from: https://catalog.data.gov/dataset/college-scorecard-c25e9.
Click the Advanced button at the top of the Deephaven Console and then select Schema Editor.
Caution
Note: The Schema Editor menu item is only available if you are a member of the iris-schemamanagers group.
Accept the defaults and click OK.
The Schema Editor panel will open, as shown below:
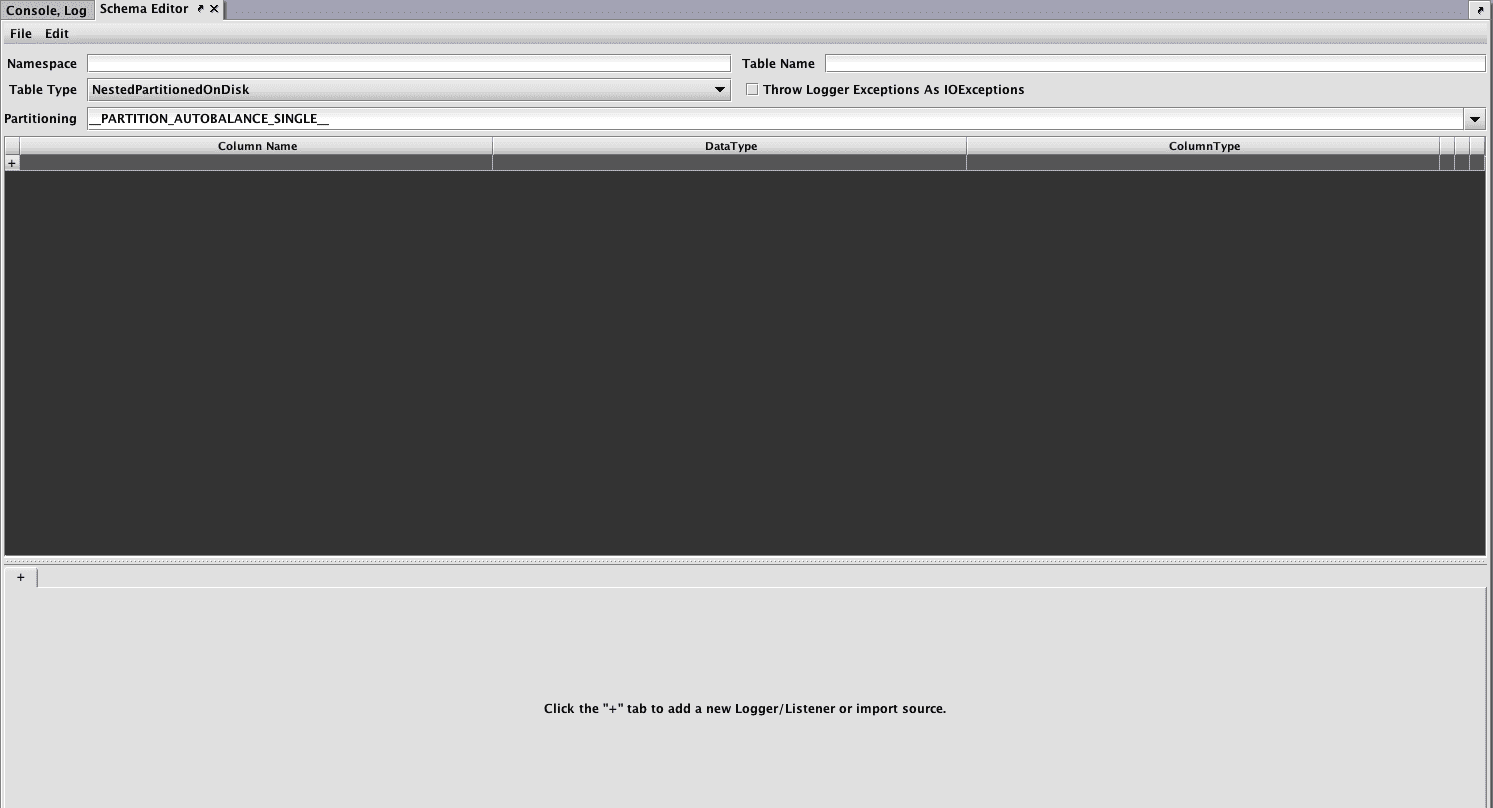
Click the File menu and the select the Discover CSV Schema... option:
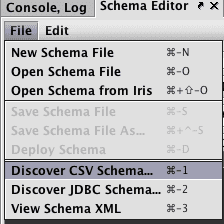
When the Discover Schema panel opens, select the ellipsis button to the right of the Source File field, (circled below).
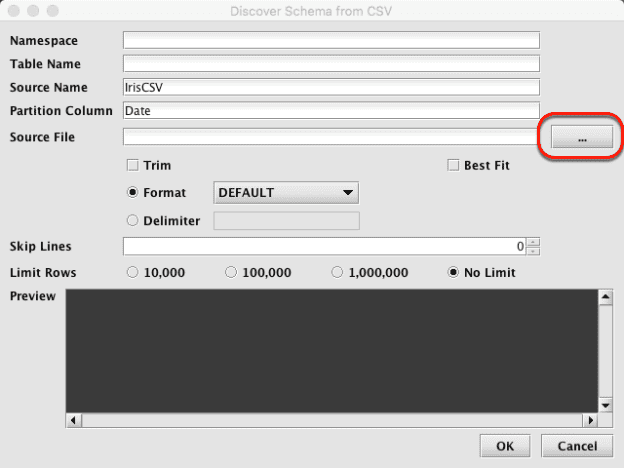
Browse for the CSV file you downloaded earlier and select Open.
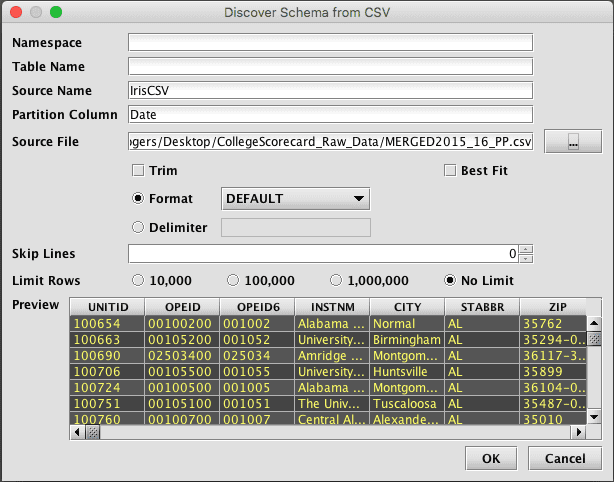
After selecting the file, enter the name of the Table Name and Namespace. (It can also be entered in the main Schema Editor window in the next step.) Format, Skip Lines, and Delimiter should be set here to result in a good preview of the data. For very large files, it may be desirable to limit how many rows are analyzed to infer the data types of the columns. The entire file does not need to be scanned, as long as there is enough representative data in the selected top lines of the file.
Click OK once the preview looks correct. Depending on the size of the file, it may take several seconds or longer to process the file. A progress bar will be shown at the bottom of the window during processing.
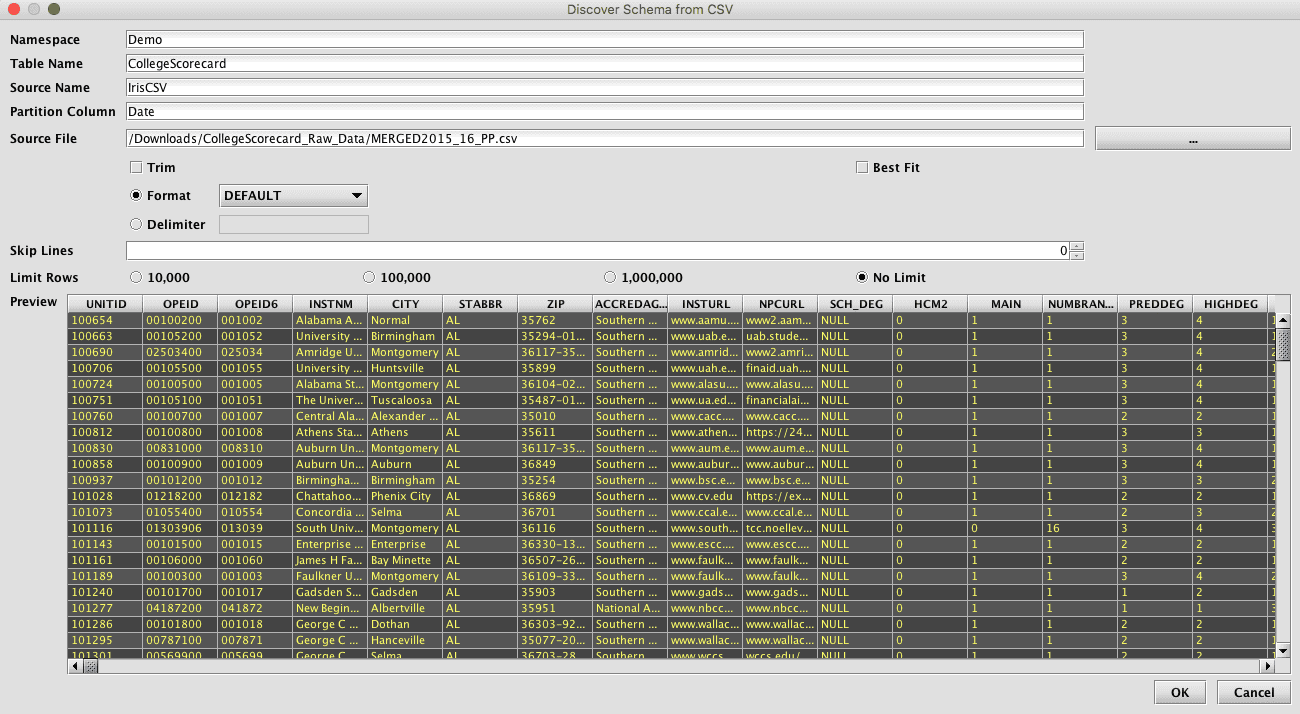
Once processed, the schema details will be shown in the main Schema Editor window. The schema can then be edited from here to change column names, types, order, and import processing.
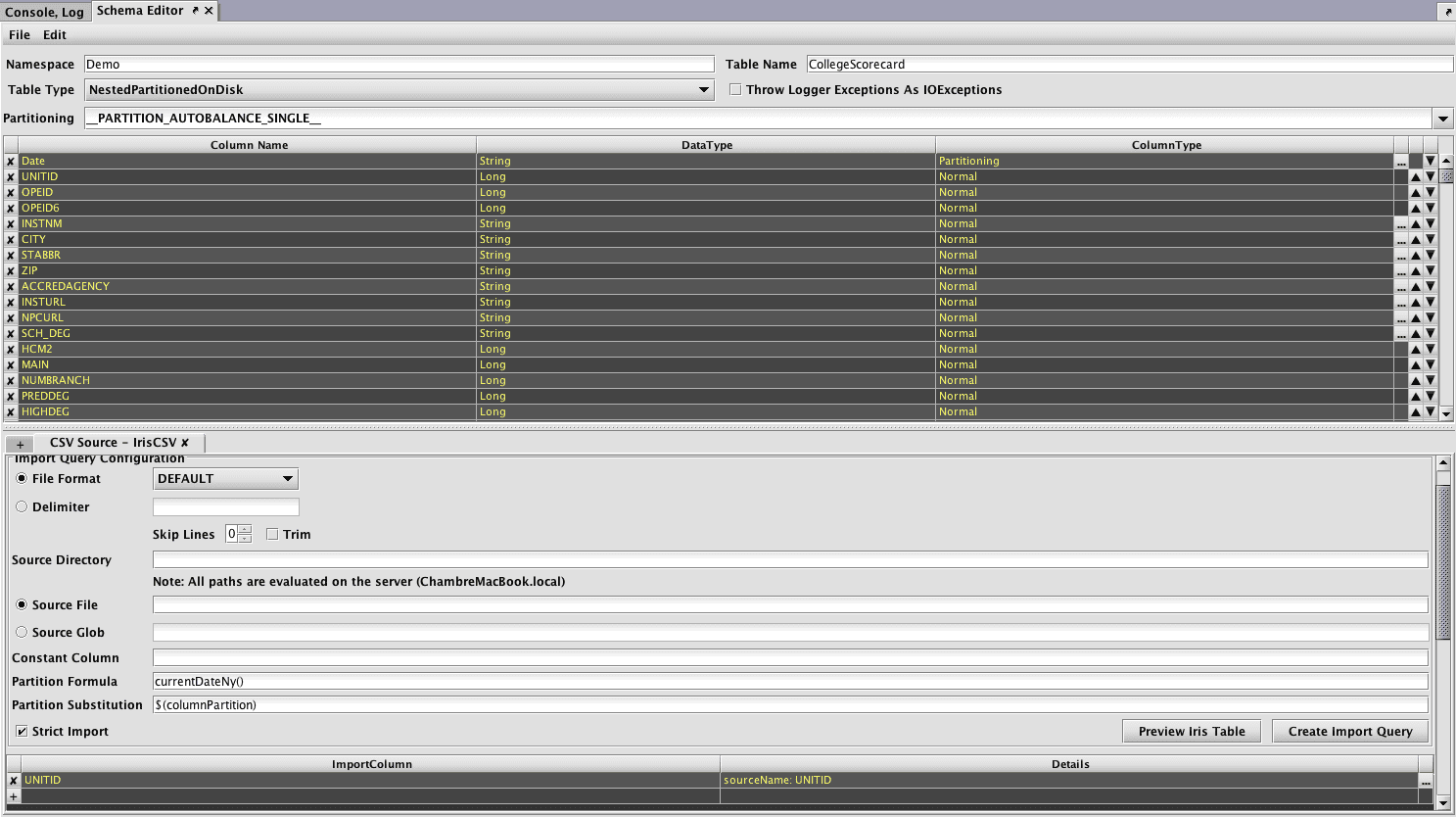
The expected results of an import to Deephaven can then be previewed using the Preview Table button. This action requires that the Source Directory, and Source File or Source Glob be completed for a path to source files relative to the query server where the Schema Editor is being run.
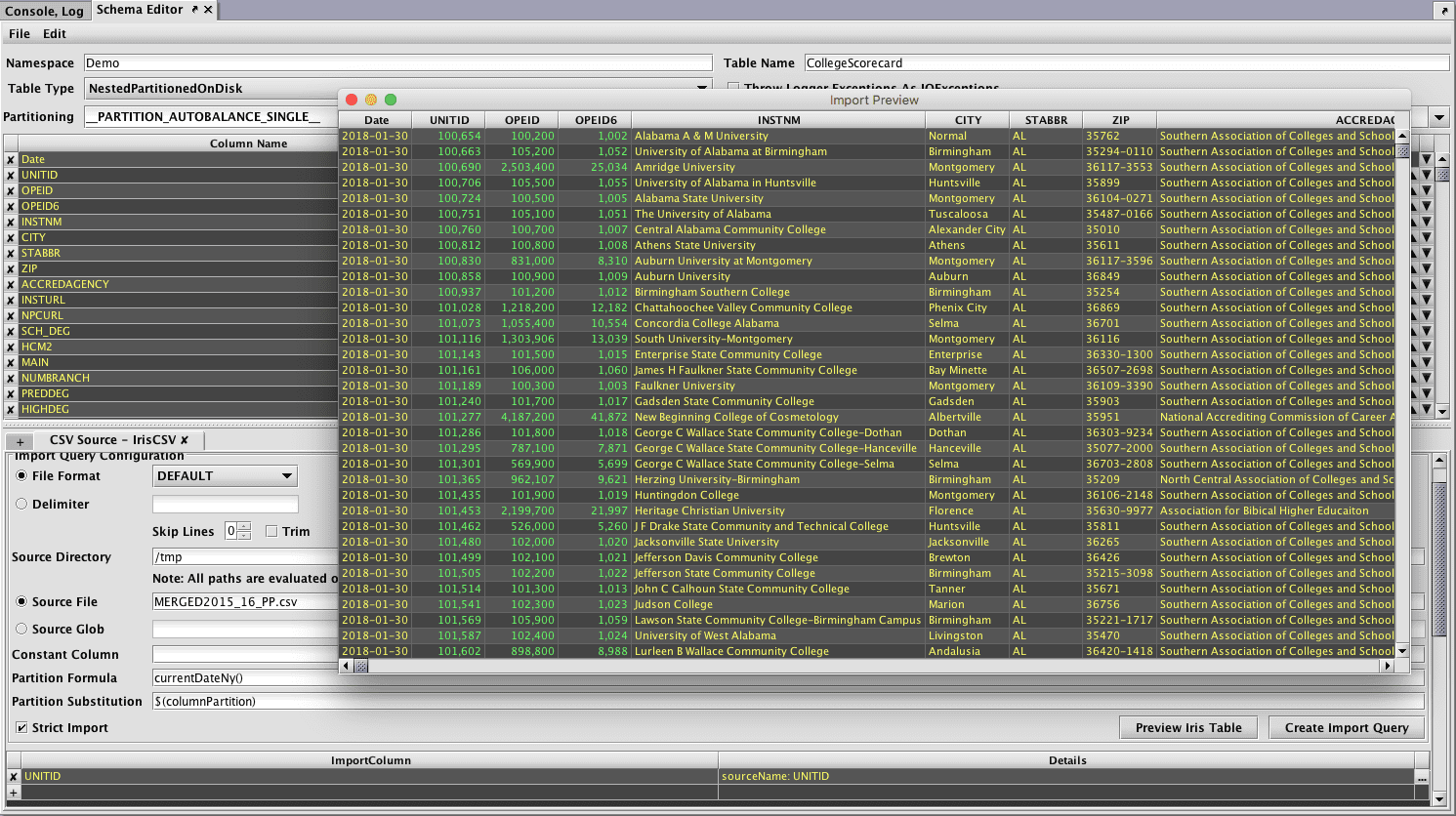
Once the schema and results of a test import are as desired, the schema can be deployed to Deephaven to create a new table definition.
Open the File menu again, and select the Deploy Schema option to deploy the new table to Deephaven. Optionally, the schema file could instead be saved to disk for later use or manual deployment.
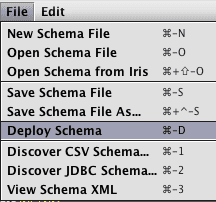
Once the schema is deployed, the Create Import Query button can create an import query or deploy the schema.
Alternatively, an Import Query can also be created later from the Query Config panel of the Deephaven console. It will be necessary to set basic settings on the Settings tab, at least a timeout on the Scheduling tab, and details of the source file path and name on the CsvImport Settings tab.
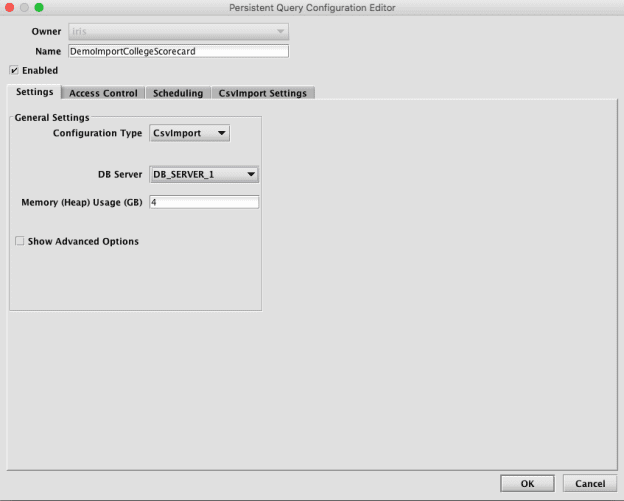
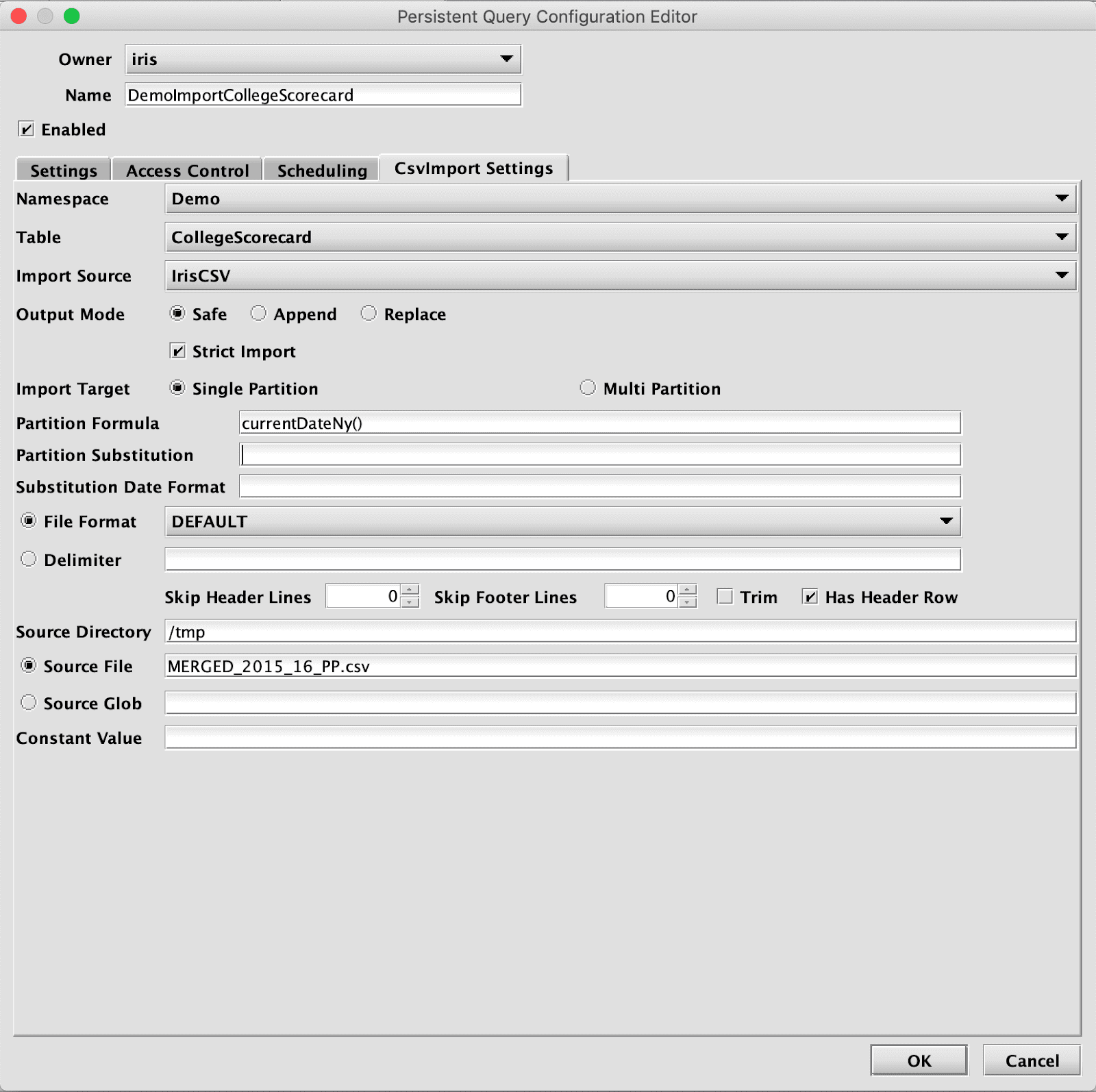
After completing this process, the new Import Query will be displayed alphabetically in the Query Config panel.

Backfilling Batch Data
Often when loading batch data there is a set of data files from previous dates which also need to be loaded.
For small data sets it may be practical to have a single file that includes data to load into multiple date partitions. This can be done with a single execution of an import query. It requires that the data file includes a column with the partition values. To configure this import query, change the Import Target to Multi Partition, and set the Import Partition Column to indicate the column in the data file that will be used for the partition value.
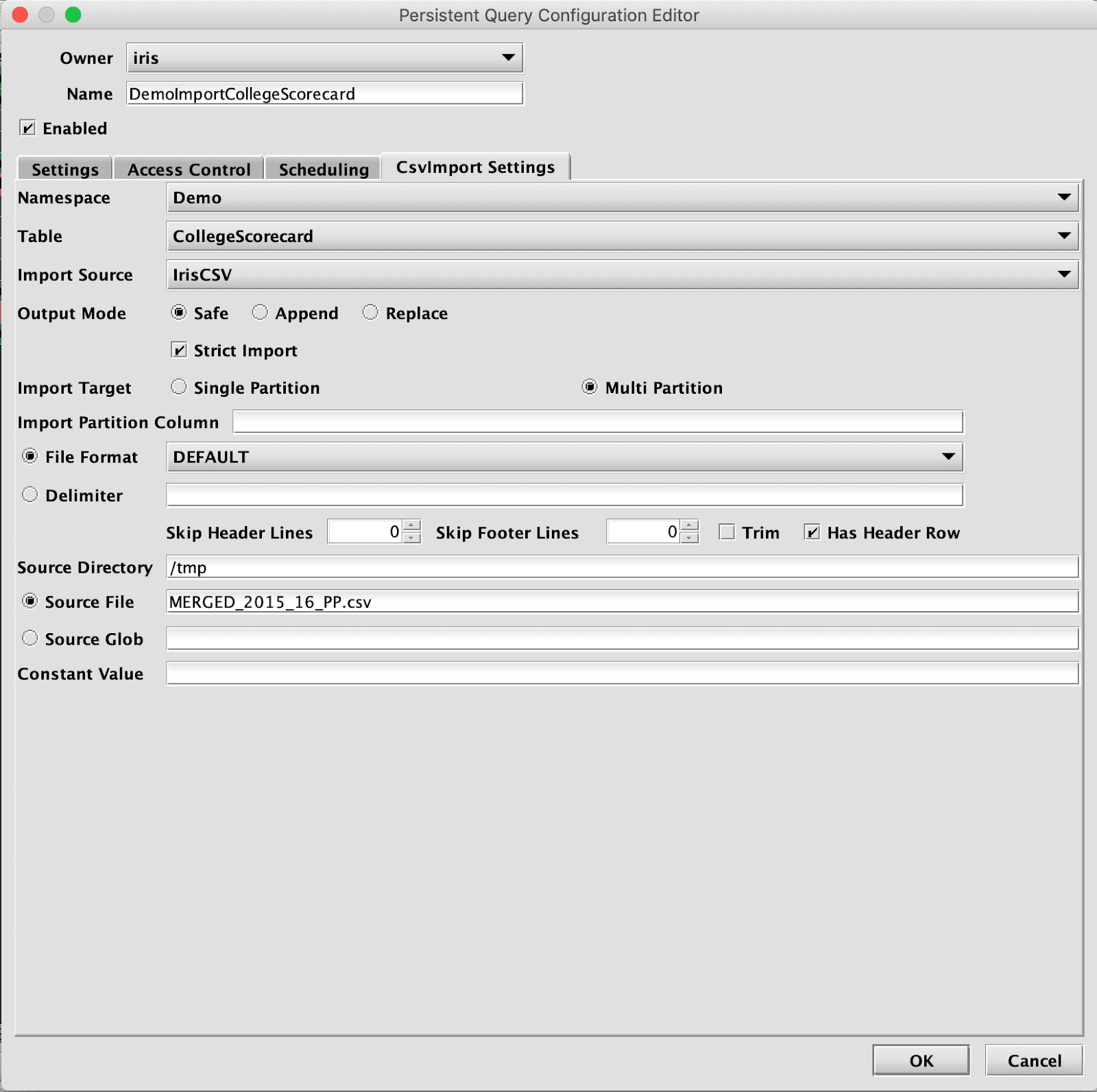
For backfill from sets of files, which will be more common for larger data sets, Deephaven provides bulk-copied temporary queries.
The bulk copy process can be used once an import query has been set up as detailed above. The basic process is:
- Stage backfill import files with file or directory names that can be matched to the partitions in which they should be loaded.
- Configure the import query with corresponding file matching properties to find files based on partition being loaded.
- Bulk copy the import query to set up temporary queries, one per date, to batch process the backfill.
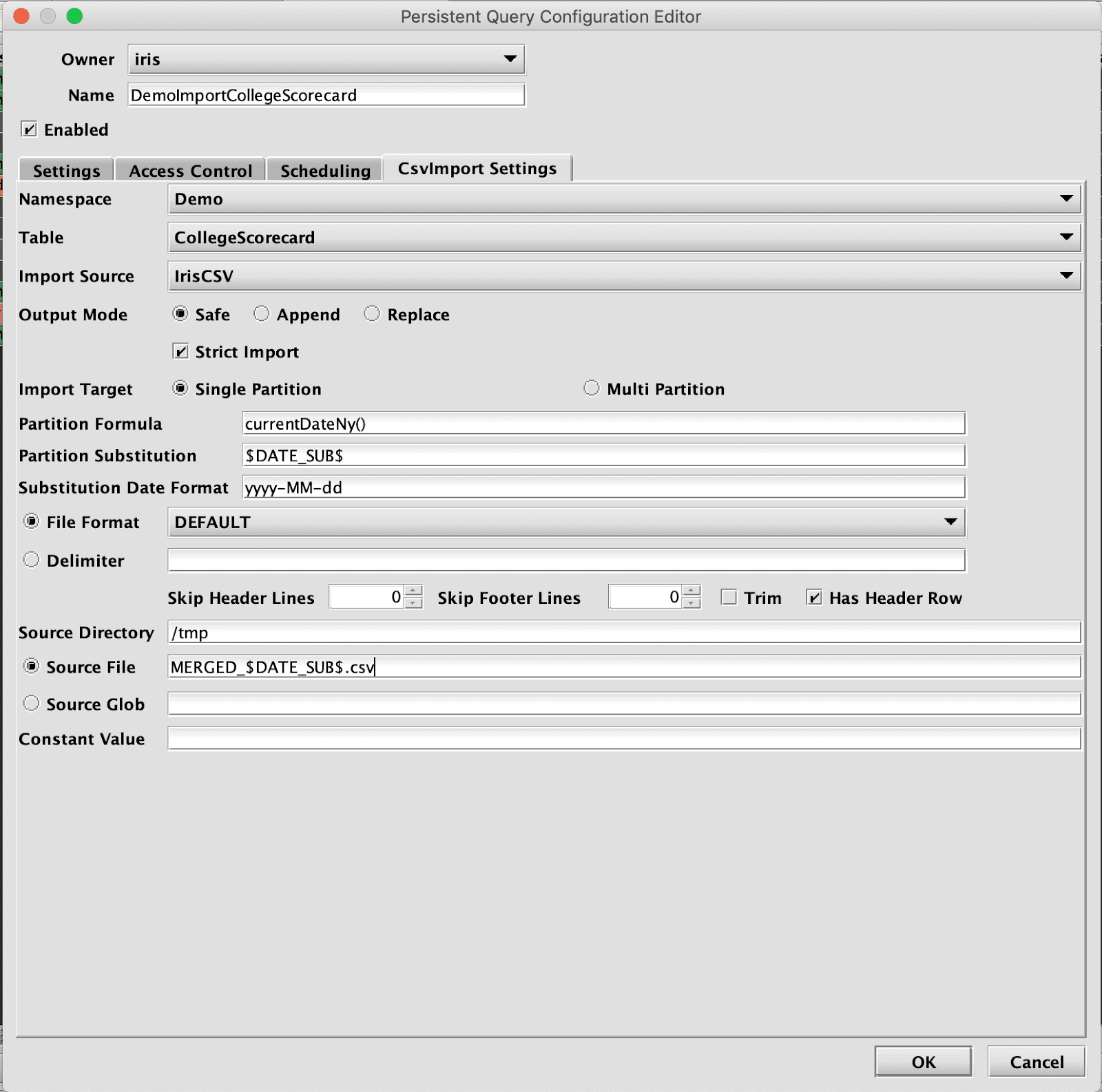
In this example, the token $DATE_SUB$ has been configured for Partition Substitution, with a format of yyyy-MM-dd. This means that whatever value is provided for the Partition Formula, will be used as a date String with yyyy-MM-dd formatting, and that will then be used in place of the $DATE_SUB$ token when constructing the filename to import.
For example, if "2020-09-24" is the Partition Formula, the job will attempt to find a file in /tmp named MERGED_2020-09-24.csv.
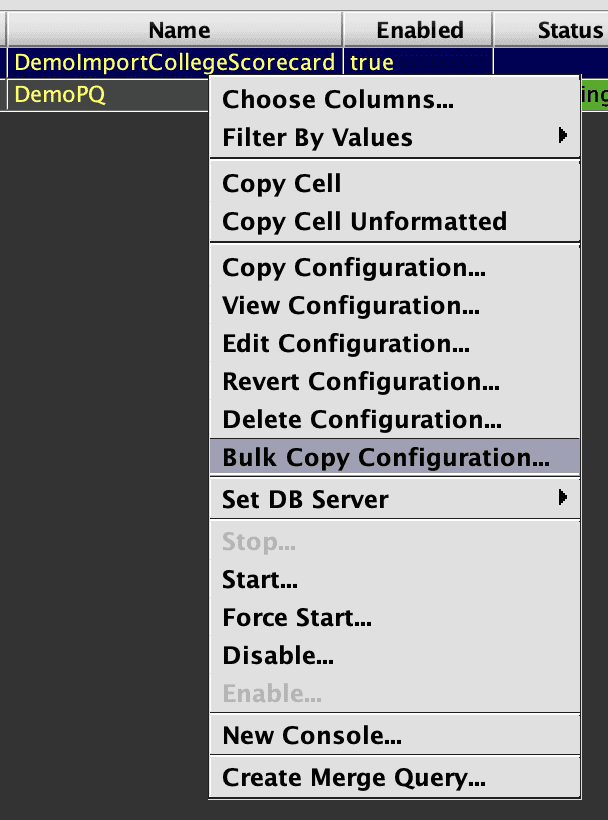
When Bulk Copying the import query, the Partition Formula values will be provided by the Bulk Copy Wizard, rather than using the expression (currentDateNy() in this example) that was entered in the configuration of the query being copied.
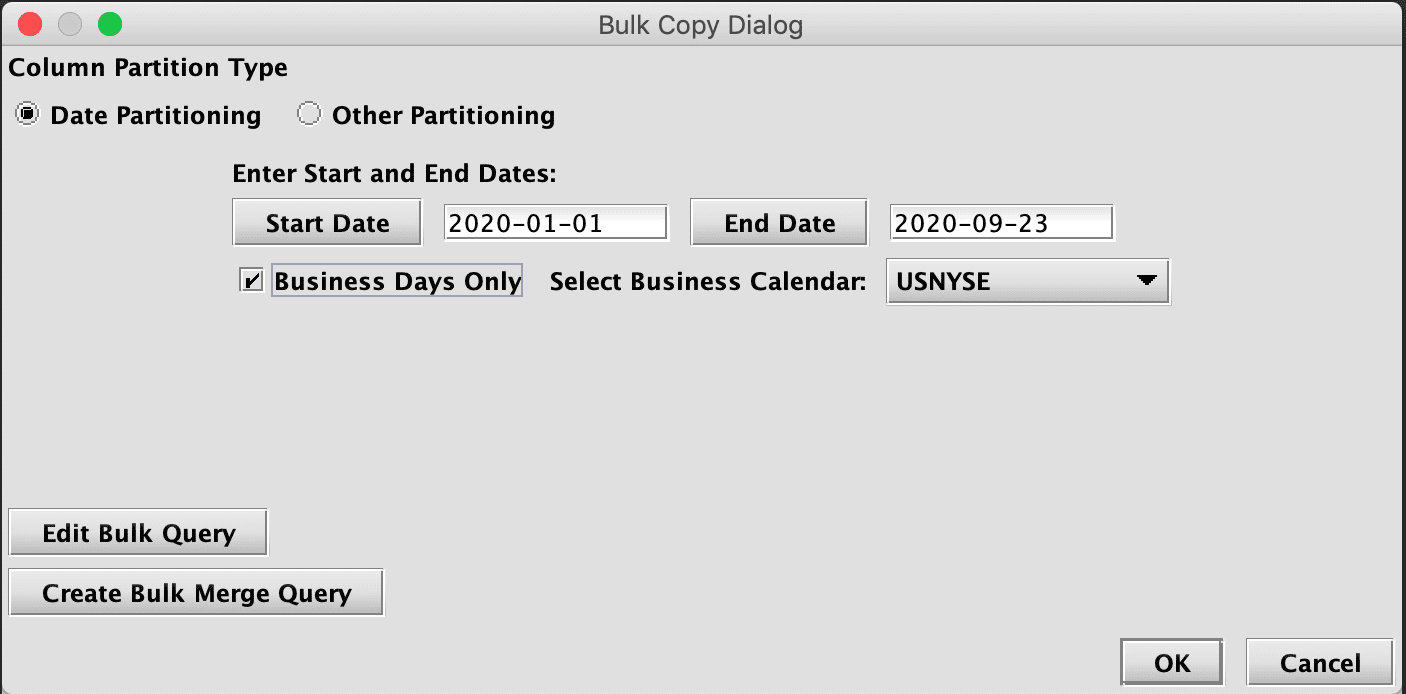
This Wizard can also be used to create data merge and data validation queries that will be chained to the import queries. Merge queries require that historical data storage has been set up for the namespace being loaded by the import query. The Create Validation Query button will be displayed after a bulk merge query has been created. This allows batch automation of the whole backfill process:
- importing data,
- merging it,
- validating it,
- and deleting the intraday data that has been merged.
When the Bulk Copy Wizard is completed, it will create a series of queries - one per day per type (import, merge, and validate) - and will run them sequentially. By default the controller will run one temporary query at a time, and is limited to 2GB of heap for each query. These settings can be changed with these properties:
PersistentQueryController.temporaryQueryQueue.DefaultTemporaryQueue.maxConcurrentQueries=1PersistentQueryController.temporaryQueryQueue.DefaultTemporaryQueue.maxHeapMB=2048