Think like a Deephaven ninja
How to write clean, efficient, and concise queries which dynamically update
As Deephaven’s Chief Data Scientist and as a co-inventor of the Deephaven system, I have had the opportunity to bring many new users onto the Deephaven platform. These onboarding experiences have demonstrated that one of the largest hurdles for new users is learning to “think in Deephaven.” To achieve exceptional power and usability, Deephaven is different than other technologies. Just as Pandas, SQL, R, etc. encourage a certain approach, so too does Deephaven. Like other users, I hope you find that "thinking in Deephaven" is intuitive and natural, because the system's capabilities can uniquely empower your use cases - particularly as it relates to updating or large data. To realize Deephaven's potential, I encourage you to consider the tips below.
In this document, I present major concepts that will allow you to think in Deephaven. I make no effort to be comprehensive, and I assume that you have a basic understanding of how to write a Deephaven query. Such details are documented elsewhere. Here, I provide a very high-level view of how Deephaven works and how to use this knowledge to produce powerful, clean, efficient, and concise queries.
Let’s get started.
-- Chip Kent
Chief Data Scientist, Deephaven Data Labs
Query Language
To achieve maximum performance and real-time query results, you must use the Deephaven Query Language (DQL) to interact with Deephaven.
Let’s begin by dissecting a simple Python query.
First, emptyTable(10) creates a table with 10 rows and no columns. Next, update("X = i", "Y = X*X") adds two columns, X and Y, to the table. Here "X = i" and "Y = X*X" are known as query strings. Query strings are special. When the query is evaluated, the query strings are dynamically converted into code and compiled, yielding very concise syntax for users with high-performance execution.
Now, let’s make the query a little more complex by adding a table, t2, with a new column, Z.
Column Z is computed with the query string "Z = X + 2*Y + 2 + a + (int)f.call(Y)". When this query string is compiled, Deephaven must determine what each of the variables is. These variables can be:
- columns in the table, such as
XandY, - constants, such as
2or3, or - values present in the query scope, such as the variable
a.
For convenience, top-level Python variables and Groovy binding variables are automatically added to the query scope by Deephaven. This would allow our query to be shortened to:
Because the Deephaven query engine is written in Java, it is also possible to call Java functions from query strings.
Here I have explicitly provided the fully qualified Java class location so that the function can be resolved when the query string is compiled. The syntax can be made more concise with db.importClass(...) or db.importStatic(...). These methods make either the class or the static methods from the class available to the query string. This allows us to make the query string short and readable.
Because the query strings are just strings, you can do some very cool meta-programming.
This simple loop and format string creates five new columns - C0, C1, C2, C3, C4 - with values equal to 0, 2, 4, 6, 8. Carefully applying this technique can make messy code clean and concise.
Query As A Graph
Deephaven’s query syntax is very natural and readable. Under the hood, the queries are converted into directed acyclic graphs (DAGs) for efficient real-time processing. Let’s look at an example to understand DAGs.
Here, table t1 is a table that ticks every second and has a Timestamp column as well as a Label column, which alternates between zero and one. Table t2 contains the most recent row for each Label value, and t3 joins the most recent Timestamp for a Label, from t2, onto t1.
Represented as a DAG, this query looks like:
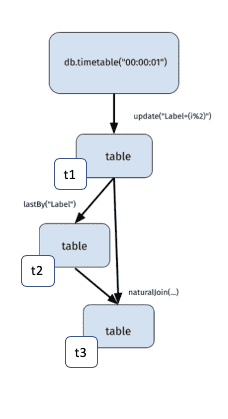
Here you can see each part of the query as connected components - aka a “graph”. The graph starts with the data sources, timeTable(...) in this case. In real time, data flows from the data sources through the graph, dynamically updating the tables. Because this data flow is in one direction, the graph has no loops. This is where the “directed acyclic” part of the directed acyclic graph (DAG) name comes from.
The variables t1, t2, and t3 are simply references to tables within the DAG. These variables allow the tables to be displayed as well as used in further query operations. If a table is not associated with a variable, it is still part of the DAG, but it is not accessible to users. There is one exception. Tables that are not used in the calculation of any variables are garbage collected and removed from the DAG. For example, if the variable t3 is set to None, there are now no references to the result of the naturalJoin(...), so that table is removed from the DAG.
The Deephaven query engine is smart. When data flows through the DAG, instead of recomputing entire tables, only necessary changes are recomputed. For example, if only one row changes, only one row is recomputed. If 11 rows change, only 11 rows are recomputed. If you use static data tables obtained from db.t(...), large sections of the DAG may never recompute. This is one reason Deephaven is so fast.
When processing real-time data changes, Deephaven batches the changes together every 1000 ms (this is configurable). All of the changes within a batch are processed together. These processing events are called Live Table Monitor (LTM) cycles, and the change messages which propagate through the DAG are called Add Modify Delete Reindex (AMDR) messages. Just as it sounds, AMDR messages indicate which rows have been added, modified, deleted, or reindexed (reordered).
Note
See also: Controllng Table Update Frequency
Most users never interact directly with AMDR messages, but it is possible to write custom listeners, which execute code when a table changes. Custom listeners are non-table components of the DAG, which listen to AMDR messages of table changes. For example, if you have a query that monitors how full disks are on a cluster, you can write a custom listener to send an email or Slack message every time a table in your monitor query gets a new row, indicating that disks are starting to fill up.
Note
See also: Listeners in Deephaven Schemas
Thinking in terms of DAGs, LTM cycles, and AMDR messages can be insightful when trying to understand the real-time performance of a Deephaven query. Each source table change creates a cascade of changes (AMDRs), which must be processed before the next LTM cycle can begin. If the source table changes trigger many AMDRs, AMDRs with many changed rows, or slow to compute AMDRs, it may be impossible to calculate all of the necessary updates before the next LTM cycle begins. Now your query is unresponsive. Yuck.
Deephaven’s performance analysis tools can help you dig into an unresponsive query to locate which operations are causing slow LTM cycles. Once you understand what operations are slow, you can rearrange your query so that fewer changes are being processed, add table snapshotting to reduce the frequency of changes, etc.
Finally, DAGs are not limited to one query. Preemptive tables allow tables (and AMDRs) to be shared between queries. You may have Query1 perform a difficult or secret calculation. Query2 can use the shared results of Query1 without having to recompute and without being able to see the secret sauce that went into Query1’s calculation.
Data Layout
To achieve maximum performance on massive datasets, Deephaven uses (1) column-oriented tables, and (2) a tree-like table representation. Understanding these two concepts will allow you to write the fastest possible queries.
First, let’s look at column-orientation. Most tabular databases are row-oriented. This means that all of the data for a row is stored together. Such storage can be convenient if rows are frequently changed, but it results in slow queries because the whole row must be processed by the database, even if only one element is needed.
Deephaven is column-oriented. This means that all of the data for a column is stored together. As a result, Deephaven needs to read less data to perform a query. Only the required data is read. Also, because data does not need to be moved when adding a new column, adding columns to a Deephaven table, for example by using update(...), is very fast.
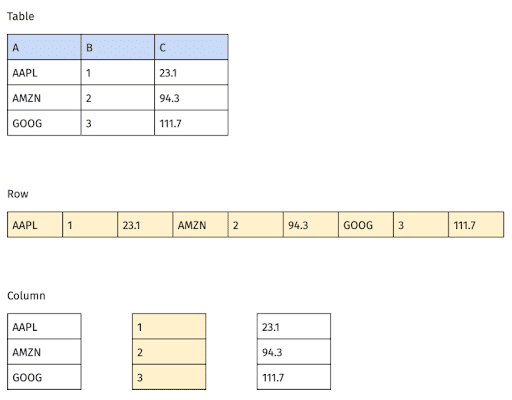
This figure illustrates a table in both the row-oriented and column-oriented format. If we filter the table to the rows where column B is odd (t.where("B%2==1")), the column-oriented representation only reads the 3 values from the B column, while the row-oriented representation must read almost the entire table in order to access the 3 values it needs to perform the query.
Now that you understand how column-orientation works, let’s look at a simple performance tuning example.
Here, tables t2 and t3 contain the same values. Which is faster to compute? Because Deephaven is column-oriented, neither t2 nor t3 must read the values in column Y. Both t2 and t3 must read the values in column X, but because t2 breaks the X filter into two, it reads column X twice. t3 is faster!
Note
Simple X>2 type filters do not need to be compiled, but X>2&&X<6 type filters do. This could potentially add a few milliseconds to the run time. This will only matter for very small data sets where the compilation time is large relative to the run time.
If the column being filtered on is a partition column or a grouping column, the more complex filter (e.g., X>2&&X<6) may throw out all of the partition/grouping information, resulting in a slower query.
Next, let’s look at Deephaven’s tree-like table representation. A single Deephaven table can contain billions of rows and petabytes of data. Loading all of this data, when your query only needs a tiny bit, would be inefficient. To minimize the data a query needs to access, Deephaven uses a tree-like representation.
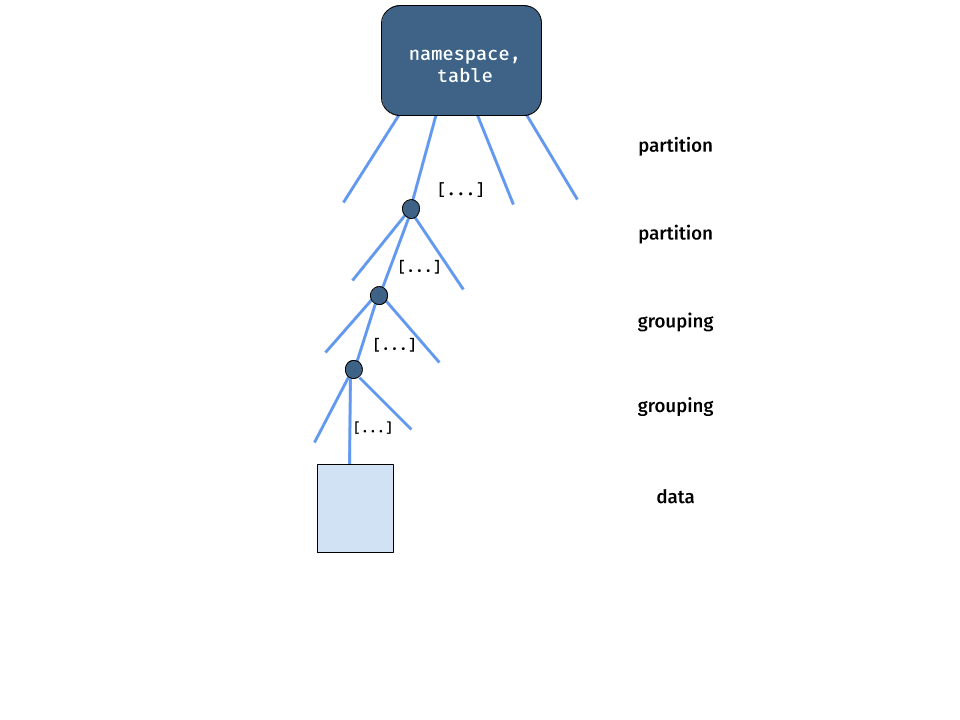
This figure shows the tree. The top branches of the tree are known as partitioning columns, the lower branches of the tree are known as grouping columns, and finally, at the bottom, is the actual data. Partition and grouping columns may not be present in all tables. For example, real-time tables frequently have partition columns but no grouping columns.
To make this abstract concept concrete, let’s look at the "StockTrades" table in the "LearnDeephaven" namespace. Every table has metadata associated with it. This metadata describes all of a table’s columns, including whether a column is partitioning, grouping, or normal.
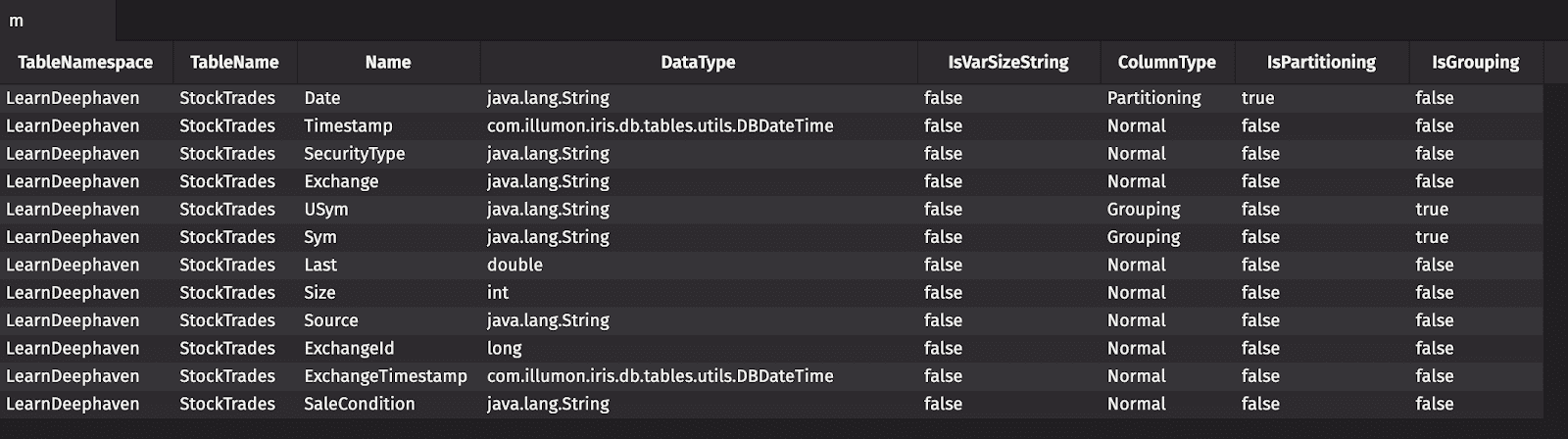
Here you can see that Date is a partitioning column, USym and Sym are grouping columns, and the other columns are normal columns. As a tree, this table looks like:
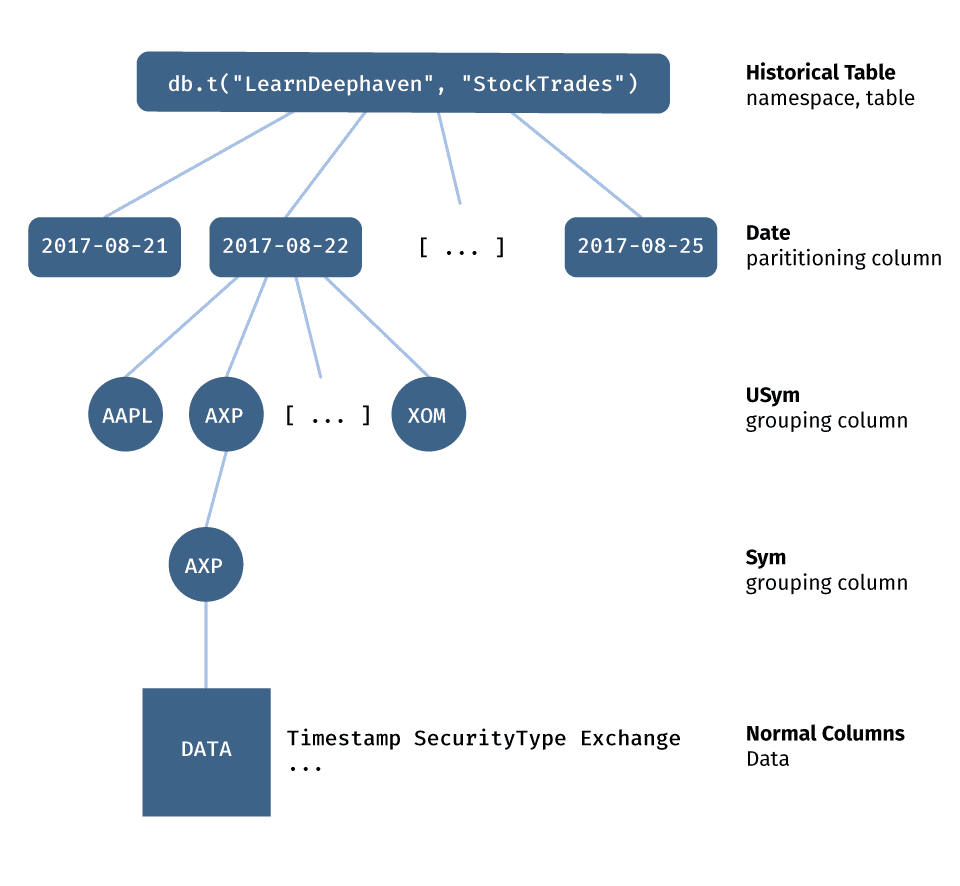
To produce efficient queries, you want to read as little data as possible as well as perform as few calculations as possible. The tree lets you do this.
Important
Just order your where clauses as follows:
- partitioning
- grouping
- normal
Here are five queries that produce the same result. Which is the fastest? Which is the slowest?
They are actually ordered from fastest to slowest. The filters in t1 are ordered with (1) partitioning, (2) grouping, and (3) normal. By ordering the clauses like this, massive sections are removed from the tree with each consecutive filter, and very little data needs to be read. On the other hand, the least efficient query, t5, orders the filters with normal first, grouping second, and partitioning third. This order causes the entire table to be read. Ouch.
Like filters, joins can be sensitive to ordering. By ordering your join columns in partitioning, grouping, normal order, your queries will be fastest.
By understanding Deephaven’s tree-like representation and using getMeta() to find column types, you can easily order your filters and joins for optimal performance. Also, by thinking in terms of trees, you can determine the most efficient way to represent your data as a tree.
Deephaven is constantly improving the system; column ordering may become less important in the future, but if you always order your columns in partitioning, grouping, normal order, you will always have the fastest performance.
Choose The Right Quotes
The Deephaven Query Language (DQL) uses three types of quotes: ‘ (single quote), “ (double quote), and ` (backtick). Choosing the right quote can be confusing. Let’s explore where each should be used.
DQL query strings are strings. In Python, strings can be defined with either a single quote or a double quote. Both yield valid query strings, as illustrated in this example.
Backticks surround strings within a query string. This is easier to understand with an example.
In table t1, column X is created and set equal to the string “A”, and column Y is set equal to either the string “P” or the string “Q”. In table t2, the StockTrades table is filtered to only include the rows where the USym column is equal to the strings “SPY”, “AAPL”, or “AMZN”.
Times, time periods, and characters are the most complex quoting case. Similar to strings, single quotes surround times, time periods, or characters within a query string.
In this example, column X is created and is set equal to a date-time. Column Y is also a date-time and is set equal to 10 minutes after the date-time stored in X. Column Z is a date-time and is set equal to one year after the date-time stored in X. Column A is a character. A single quote is used both to surround the date-time, the time difference, the time period, and the character. (Note: Date columns are frequently stored as strings, which use backticks.)
There is one catch. You need to use double quotes for your query strings if you are going to use single quotes within the query strings.
For example:
s1 = "This is 'OK'"
s2 = 'This is 'NOT''
There is no downside to using double quotes for query strings. When in doubt, use double quotes around query strings. You can use single quotes with escapes, but they are more difficult to read.
Let’s wrap up with an advanced problem. Here all three types of ticks are used in one query string. What does the query do?
Looping: Don’t Do It!
Common programming languages, such as Python, Java, C, C++, and Go, have instructions that operate upon a single piece of data at a time. In order to operate upon multiple pieces of data, users must write loops. Deephaven is similar to NumPy, TensorFlow, or PyTorch, where a single command operates upon multiple pieces of data.
Because looping is so common in standard programming languages, new Deephaven users rely on loops to perform calculations. Their code often looks like:
This code is fairly complex. It has multiple loops, multiple queries, and multiple table merges. It is slow. It also does not work correctly as a dynamic query. The loops iterate over the values in the Date and Sym columns. If a new value is added to the Sym column, the loop does not handle the dynamic data change, and the loops no longer iterate over the correct data. Oops.
A more experienced Deephaven user would write the same query as:
This piece of code is:
- much easier to read ✅
- faster ✅
- dynamically updates ✅
Win, Win, Win.
Every time you write a loop or call getColumn(...) in your Deephaven code, ask yourself how you can accomplish the same goal without the loop and without directly accessing the contents of the Deephaven table. Most changes will involve using key columns in aggregations and join columns in joins. At first, these changes will seem foreign, but soon it will become natural.
As with most rules, there are a few exceptions to the “don’t use loops” rule. Most commonly, the rule is broken to get around RAM limitations. If you are applying complex calculations to a huge dataset, your calculation may exhaust the RAM available to your job. To avoid RAM limitations, a loop can be used to break the massive dataset into smaller, more manageable datasets, which fit sequentially into RAM. Such exceptions to the rule are rare.
Select, Update, View, UpdateView, or LazyUpdate?
update(...), updateView(...), and lazyUpdate(...) add new columns to a table. select(...) and view(...) retain a subset of columns from a table, as well as adding new columns. While it may seem redundant to provide the same functionality multiple ways, each method uses RAM and CPU differently. This allows you to choose the method with the best performance characteristics for your use case.
Note
See also: Select methods
First, let’s look at update(...), updateView(...), and lazyUpdate(...).
In this example, the contents of t1, t2, and t3 are identical. All three are tables with two columns, X and Y, plus 10 rows of identical data.
In the case of t1, update(...) is used. update(...) causes RAM for the two columns to be allocated, ncols * nrows * sizeof(int) bytes, and then the formulas are evaluated once to populate the RAM. Every time a cell from X or Y in t1 is accessed, the value is retrieved from the values already stored in RAM. This can be good if your table is small, your formulas are expensive to calculate, or if your cells are accessed many times. But, you may run out of RAM if your table is too large.
In the case of t2, updateView(...) is used. updateView(...) creates a formula column. No RAM is allocated and no evaluations are performed. But, every time a cell from X or Y in t2 is accessed, the formula is recomputed to get the value. This can be good if your table is large or if your cells are fast to compute. But, if your formulas are slow to compute and are accessed many times, your performance will suffer.
Finally, lazyUpdate(...) is a compromise between update(...) and updateView(...). lazyUpdate(...) evaluates the formulas on demand and memorizes the results. If the formula is called with the same inputs, the memorized value is used, and the formula is not reevaluated. In the example, X is computed from i values from 0 to 9, so 10 values are memorized and computed. Y is computed from X values of 0 and 1, so only 2 values are memorized. As you can see, lazyUpdate(...) is especially suited/appropriate for expensive formulas that are repeatedly evaluated with the same inputs, as in the case of Y. It is not good for cases where formulas are evaluated with many different inputs, as in the case of X. Also, beware of formulas where the inputs do not map to unique outputs.
select(...) and view(...) are similar to the operations above. select(...) allocates RAM and computes values for each cell in the result table. When cells are accessed, the values are retrieved from the already computed values in memory. view(...) does not allocate RAM, does not compute cell values, and creates formula columns. Every time a cell is accessed, the formula is reevaluated.
Now, we can add select(...) and view(...) to the example.
This results in a very rich case. t1, t2, and t3 have identical contents. t4, t5, t6, t7, t8, and t9 have identical contents. Each is computed differently. For example, t4 has column Y, which is a copy of the column Y already in memory from t1, and t5 has column Y, which is just a reference to the column Y already in memory from t1. Take some time to think through each case. The insight will help you think through your own queries.
High Performance Filters
The secret to computational efficiency is being lazy - doing as little work as possible. For Deephaven, this means operating on the minimum possible amount of data.
Note
See also: Filter
For most use cases, where(...) is the most common way to filter a table. But, the same logic can be expressed in different ways.
Caution
This query allocates a billion row table in memory and so requires at least 8GB of heap. To see the distinction between each table's load time, run the queries separately.
In this query, t1, t2, and t3 produce the same result. However, t3 is the most efficient, because column X is only read one time; t1 and t2 read column X twice (see Data Layout). Furthermore, t2 is better than t1, because future improvements in the Deephaven query language will potentially allow reorderings and other optimizations for t2 that are not possible for t1.
As you can see below, t3 takes less than 1 second to run.
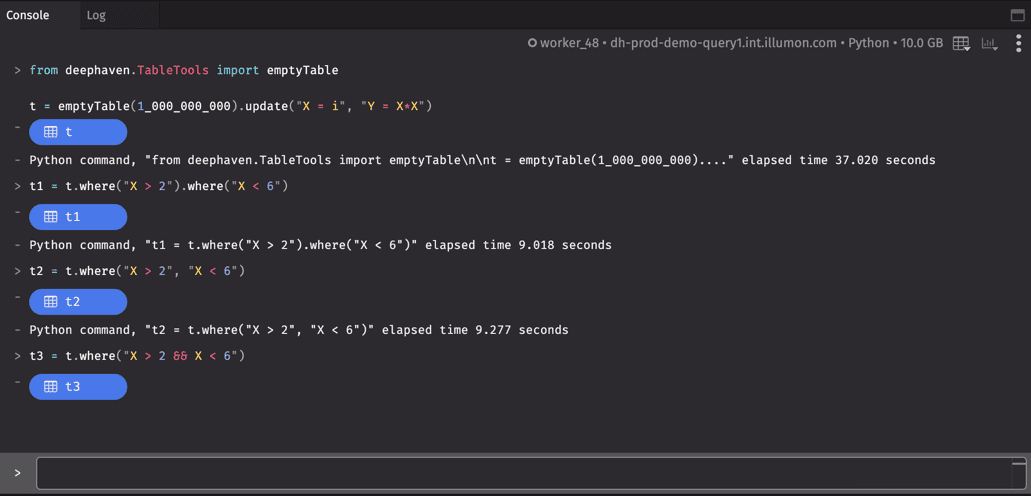
Note: The console will not print an elapsed time if the query takes less than 1 second.
Similarly, filtering performance is dictated by how a table is structured. It is most efficient to filter partition columns before grouping columns and grouping columns before normal columns. See Data Layout for more details.
Many filters can be expressed as either a conditional filter (e.g., where("X==1 || X==2 || X==3")) or a match filter (e.g., where("X in 1,2,3")). When a filter can be expressed either way, use the match filter. Deephaven can perform more advanced optimizations for match filters, and you should see higher performance.
Finally, your filtering criteria may dynamically change or may be driven by values in a table. For example, an input table may contain a list of values a user cares about. The user may add or remove items from this list during the day. where(...) cannot handle this dynamic case. Instead, you will need to filter using whereIn(...) or whereNotIn(...). To see this in action, try this query.
Important
To summarize: When performance tuning filtering:
- filter first, to minimize the data being computed upon,
- order your filters in partition, grouping, normal order,
- minimize the number of times a column is read,
- combine filters within a single
where(...), instead of chaining multiplewhere(...)s together, - prefer match filters to conditional filters, and
- use
whereIn()andwhereNotIn()for dynamic filtering.
? Is Your Friend
The ternary operator ? allows an if-else block to be expressed in a single line of code.
The query string "Z = (X%2==0) ? Y : 42" sets Z equal to Y, if X is even, or equal to 42 otherwise. Using the ternary operator results in concise queries and saves you from writing functions.
Note
See also: Conditional Operations
Aggregations: Group, Compute, Ungroup
When analyzing data, it is common to group related data together and then perform calculations on the groups. For example, when analyzing the weather, you may want to group data by day and then compute the high and low temperatures for each day. In the Deephaven lingo, such operations are called “aggregations.”
The most simple aggregation is an aggregation applied to an entire table.
This example computes the maximum value for a column using four different aggregations. t1 computes the maximum value for each column for the whole table. t2 and t3 compute the maximum values where the data is grouped by X or Y respectively. Finally, you can group by multiple key columns. t4 computes the maximum values where the data is grouped by both X and Y. Dedicated aggregations are available for common operations, such as max, min, first, last, count, etc.
Frequently, you may want to perform multiple different types of aggregations on the same table, for example, max and min. While you could compute maxBy(...) and minBy(...) tables and join the results, it is more efficient to compute the aggregations at once using an AggCombo.
AggCombos can include simple operations, such as min or max as well as more complex operations, such as standard deviation, weighted average, or percentiles.
Finally, data can be aggregated into arrays using by(...). Arrays allow more complex and customized calculations.
Note
See also: Arrays In The Query Language
This example groups the data using X,Y-keys, computes a custom value, and then ungroups the result. ungroup(...) can be thought of as the inverse of by(...). It undoes grouping.
Both the group-compute and group-compute-ungroup design patterns are very powerful. Use them to make your code more clean and more efficient. Be aware that recomputing custom calculations may be expensive if arrays are large. AggCombos are designed to incrementally update, without reanalyzing the entire dataset, so they are very efficient.
Choose The Right Join
Joins provide a way to combine results from multiple tables into a single resulting table. Many new users gravitate towards the join(...) method, because it sounds like what they want to do. However, Deephaven provides many types of joins. While join(...) will frequently accomplish the desired objective, there are other, similar joins which are more efficient.
Note
See also: Joining Data
It is worth the effort to read through the documentation on joins. Each join has a purpose. Knowing all of the joins is powerful.
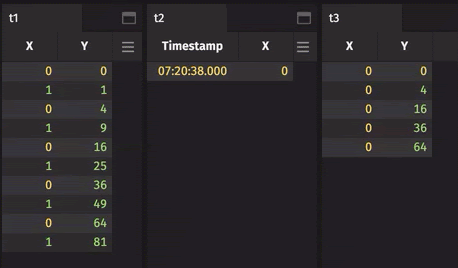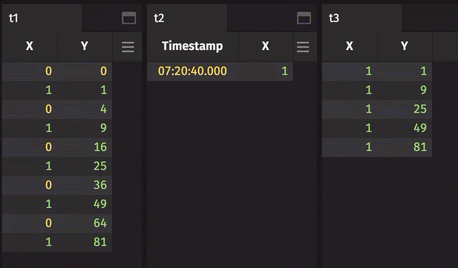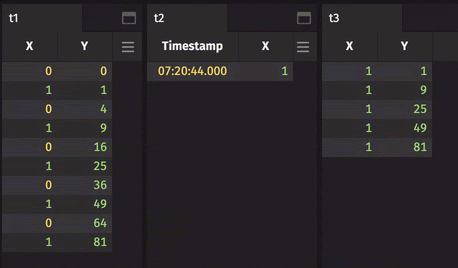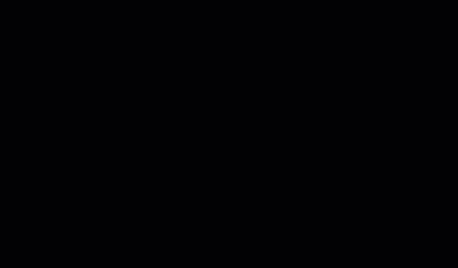
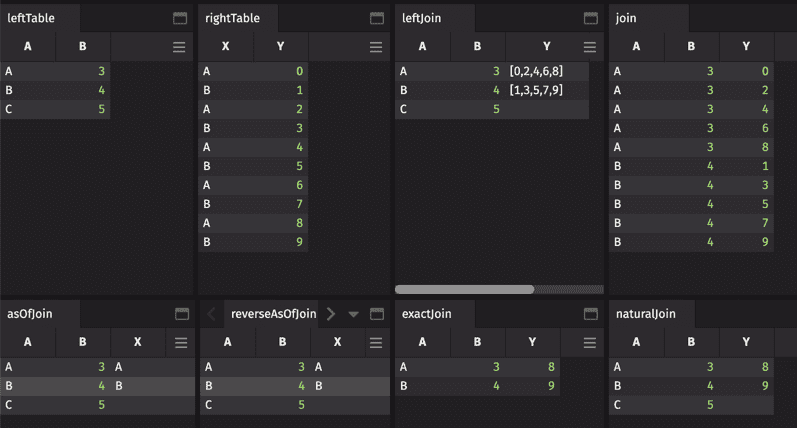
join(...)computes the cartesian join, where every row of one table is joined to every row of another table.join(...)is useful if the cartesian product is desired, but it is less efficient thannaturalJoin(...)orexactJoin(...)for adding data to an existing table.naturalJoin(...)appends values from the right table onto the left table. Nulls are appended for missing values.naturalJoin(...)is the most commonly used join.exactJoin(...)is likenaturalJoin(...), butexactJoin(...)requires that all values be present. Missing values in the right table result in an error.leftJoin(...)joins all matching values in the right table onto the left table as an array.aj(...)andraj(...)are timeseries joins. They join on values immediately before or immediately after a key. The key can have multiple items. Only the last item is matched appropriately. All other items are matched exactly.
Each join has particular requirements. It may be that the right table must have only one instance of each key, or maybe the table needs to be sorted a certain way. Before jumping in, make sure you understand the requirements for a join.
Give joins a try:
Handling NULL Values
Datasets frequently have missing values. In Deephaven, missing values are represented as null values. For performance reasons, each data type represents nulls differently. Complex data types, such as Objects are stored as standard “null” references - None in Python. For primitive types, such as doubles or integers, a single value from the type’s range is designated to be the null value.
A simple script can be used to see what the null values are:
| Type | Value |
|---|---|
| Byte | -128 |
| Short | -32768 |
| int | -2147483648 |
| Long | -9223372036854775808 |
| Float | -3.4028234663852886e+38 |
| Double | -1.7976931348623157e+308 |
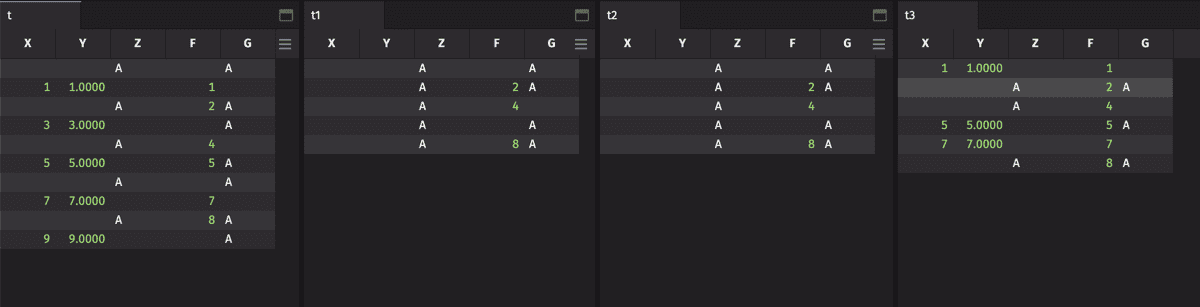
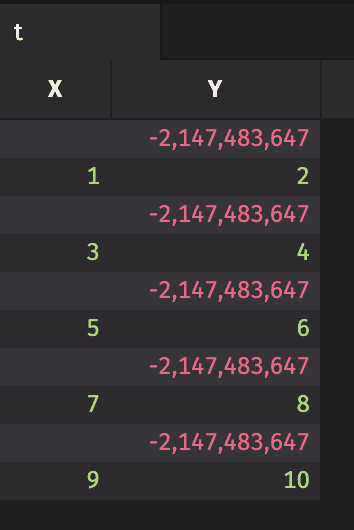
Here, column X contains null values, which result from using NULL_INT in the Deephaven Query Language. Column Y shows that NULL_INT is automatically converted to NULL_DOUBLE by a DQL type cast. Column Z shows null being used as the null value for a string object. Finally, columns F and G show user-created functions returning null values. Note that Python’s None value is used for null objects in user created functions. All of these columns can be filtered using the built-in isNull(...) function.
When writing your own functions, think carefully about how missing data (nulls) should be treated. Will there be null inputs? Should null values be returned?
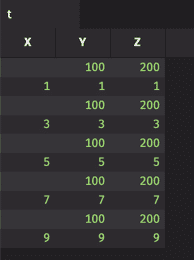
This example shows a built-in function, nullToValue(...), that replaces null values with 100. It also shows a user defined function that replaces null values with 200.
Deephaven’s built-in functions are designed to work with null. Make sure that your functions also handle nulls, or you will get some funky results.
Java Inside
Most user interactions with Deephaven happen via a programming language such as Python or Groovy, yet, under the hood, the Deephaven Query Engine is written in Java. Occasionally, it is beneficial to use the “Java inside.”
In this query, Java is used twice in the query strings. First, the sin(...) method from the java.lang.Math class is used to compute column A. If you find a Java library that implements functionality you need, just place it on the classpath, and it is available in the query language. (See Query Language for more details.) Second, Deephaven Query Language strings are java.lang.String objects. Here the split(...) method plus an array access have been used to retrieve the second token in the string. This inline use of Java String methods eliminates the need to write a custom string processing function.
Because of the deep integration of Java within the Deephaven environment, it is possible to create Java objects within a Python query. This technique isn’t often used, but it is occasionally helpful when using a Java package.
In this Python example, a Java ArrayList is created and used in a query filter. You now have the power of Python, Java, and Deephaven available within a single query!
Arrays In The Query Language
When performing complex analyses, arrays are an invaluable tool. Arrays group related data together, and arrays provide an easy way to access offset data from a time series. Arrays are built into the Deephaven Query Language.
Every column in a table has an associated array variable. For example, the data in column X can also be accessed through the X_ array.
Here, columns A and B are offset values of column X. Column C contains the size of column X. Column i is a special, built-in column which contains the row number and is useful for accessing arrays. Because column i is expensive to compute for ticking tables, it is only available for static tables. As a result, accessing a column’s values through the _-operator is used almost exclusively for analyzing static data.
Arrays can also be created when using by(...) to group data.
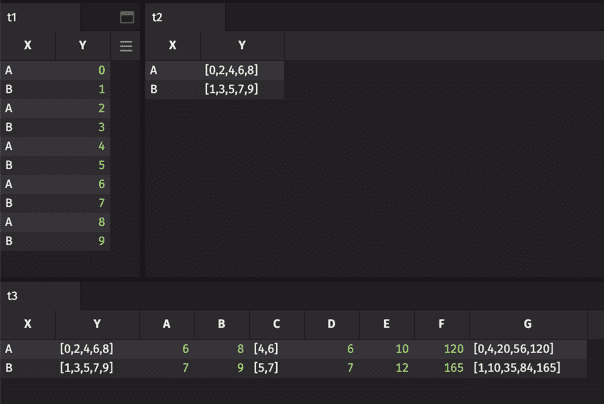
In this example, table t2 is grouped by the values contained in column X. This results in column Y containing arrays. These arrays can be indexed (columns A and B), sliced (columns C and D), operated upon by built-in functions (column E) or operated upon by user functions (columns F and G). The user function cumsum(...) even returns an array.
Use the power of arrays in the Deephaven Query Language to make your queries more powerful and concise.
Use User Tables
As a Deephaven user, you will want to create your own tables. These tables may contain the results of long-running calculations or imported data. Deephaven User Tables are designed for these cases. User Tables are created by you, the user, and can have access controls to limit which other users can view them.
Note
See also: Managing Data
User Tables can be one of a few types: partitioned, unpartitioned, or real-time. Unpartitioned user tables are for storing simple tables, without partitioning columns. Unpartitioned tables can be useful for simple cases, such as storing data from a CSV as a table. Partitioned user tables are for storing larger tables with a tree-like structure. Partitioned tables are useful for nightly persistent queries that add new data for each day (a partition). Real-time, centrally managed user tables are for persisting and sharing dynamic tables. Real-time user tables are always partitioned.
See Data Layout for more details on partitioning.
This example creates an unpartitioned user table named ExampleTable in the ExampleNamespace. First the user table is deleted, using db.rm(...), if it already exists, and then a new table is created using db.replaceTable(...). Finally, the saved table is loaded using db.t(...). Because the table is persisted, db.t(...) can now be used to access the table in any query with access to the table. For partitioned user tables, db.replaceTablePartition(...) is used in place of db.replaceTable(...). Real time user tables use db.appendCentral(...) to write tables and db.i(...) to read tables.
Clean Chained Queries
Query operations can be chained together to express complex ideas.
While powerful, these chained queries can quickly become difficult to read. Apply some formatting to clean things up.
If you want to include comments between your chained query operations or avoid trailing slashes, surround the code block with parentheses.
With some practice, you will get a feeling for how to format chained query operations for maximum readability.
Spreadsheet On Steroids
Spreadsheets are popular because a user can change a value in a cell, and the whole sheet recomputes to reflect the change. The same is possible with Deephaven. Deephaven Input Tables allow users to add, modify, and delete table values from within the GUI. The resulting table is a dynamic table, which updates with each change. Now you have the power of Deephaven combined with GUI-driven user input. A spreadsheet on steroids.
Note
At the time of this writing, GUI interactions with Input Tables are only possible in Deephaven Classic. The feature is coming soon to Deephaven Web.
Note
See also: Input Tables
In this example, an input table is created, if it is not already present. Once the input table has been created, it can be loaded by any script with access to the table. Here it is the input table. It is a dynamic table that can be used like any other table in queries. itl is the input table log, which contains the history of all changes to the input table. For example, the log will show you added, deleted, or modified rows in the table. Like other user created tables, input tables can be deleted using InputTable.remove(...).
To change values in the input table via the GUI, navigate to the input table or a LiveInputTableEditor (LITE) for the input table. From the table or LITE, you can modify values, add new rows, etc.
Self Help
To be productive, it is important to know where to find help. First, Deephaven has extensive documentation which can be found here. Python documentation can also be found using the built-in help(...) and dir(...) methods:
import deephaven
help(deephaven)
print(dir(deephaven))
help(deephaven.SmartKey)
Performance Tables
When a query is running, logging and performance information is written to tables in the DbInternal namespace. These dynamic tables are a godsend when trying to determine why a query failed or why a query is not performing as expected.
The ProcessEventLog and the QueryPerformanceLog are examples of useful DbInternal tables.
Note
See also: Internal Tables
Browser Logs
Finally, errors occasionally occur in the browser when using the Deephaven Web user interface. Details on these errors can be obtained from the browser console logs. Browsers have built-in tools to aid web developers. These tools allow you to view the console logs. Google “developer tools” for your browser to find out more.
If you are still unable to solve your problem, reach out to Deephaven Support using web chat, Slack, email, or phone. The team is there to help.
Conclusion
Now that you have made it this far, you will be able to think In Deephaven and will be able to write clean and efficient queries. You are ready for more advanced topics, such as parallelization or data replay.