Using Deephaven’s Combined Aggregators
Dealing with massive amounts of data is not always straightforward. Often, a data scientist needs to trim down a large data table into a handful of key components that can be used for further analysis. In the example below, we want to take a very large table of stock quotes from a particular day and trim it down to show only the highest, lowest, opening, and closing underlying price for each stock symbol included. This can be accomplished with traditional filters and joins, but Deephaven has a unique functionality for tackling these kinds of problems: combined aggregators.
Practical Example
For this problem, we wanted to use the EquityQuoteL1 table from Deephaven’s database to create a table with information on a stock's performance in a given day; in particular, we wanted to construct a new table with OHLC prices for each stock in each day. The original data table, called "stocks", is formatted in this way:
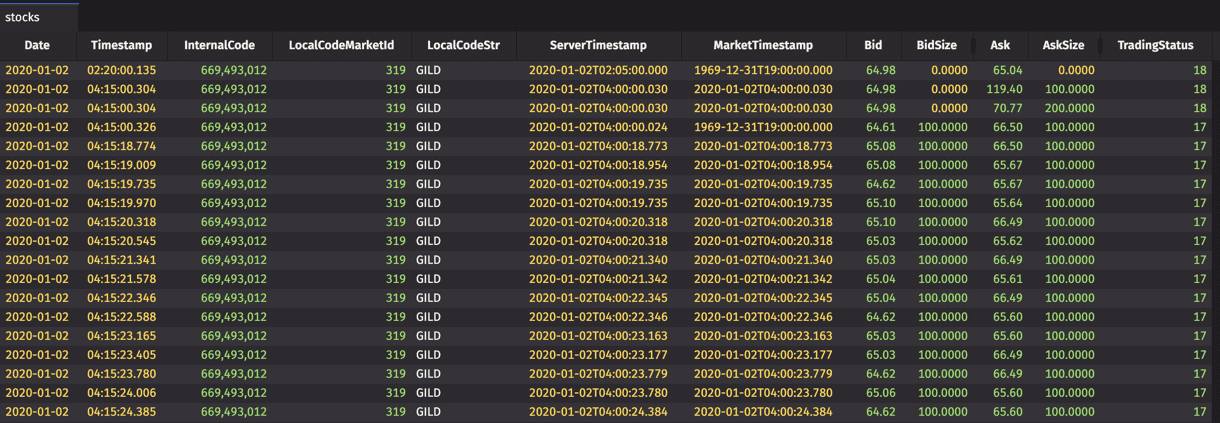
This dataset doesn’t actually contain underlying stock price, but we can compute it like so:
Here we have used a weighted mid formula for underlying price and appended it to our original table as a new column called "UndStockPrice".
Now, this dataset is about 600,000 rows strong, on January 2nd alone. That puts us on the order of hundreds of millions of rows across a full year. Your computer doesn’t like this, so you have to find a way to trim it down if you want a timely analysis. If you want to get the OHLC prices for each stock within a particular day, you could use the following code which makes use of traditional aggregators and filters:
This code is logically correct, but it is quite clunky, and all of the aggregation filters and joins may take a while (only nanoseconds, but every nanosecond counts with millions of rows). Fortunately, this type of problem is common for traders, so we’ve developed a cleaner, quicker system of aggregating your data called combined aggregators. With this new approach, we can rephrase the above code block in the following way:
This code is much easier to read and much faster (about 5 seconds per day) than the previous block because of the dedicated functionality. Either way, we get the following table:
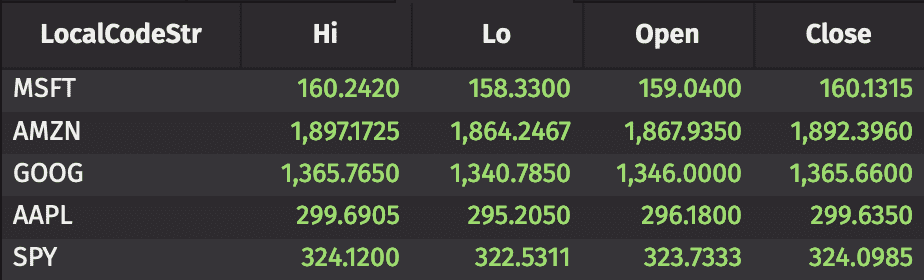
While logic is the most fundamental tool in any programmer’s or data scientist’s toolkit, good code is not only a logically coherent solution to the problem at hand. Good code is elegant, fast, readable, and makes use of any kind of dedicated functionality available. Deephaven has already designed efficient solutions to common problems for the sake of good code, so it would be a mistake to ignore them. Combined aggregators are just one of the many such solutions native to Deephaven that separate it from the pack, and hopefully this short example demonstrates the effectiveness of these solutions in a real word application.