How to Determine Symbol Table Efficiency
The DataImportServer configuration includes string caching hints that bound the size of the in-memory symbol tables that each partition may use. This protects the DIS heap from managing an unbounded number of strings, which may cause undesirable garbage collection behavior.
Note
For more detail, see Symbol Caching for Importers.
If the cardinality of your symbol table columns exceeds the configured in-memory size of your symbol table, then the DIS creates multiple IDs for each symbol, which results in higher disk usage and may negatively impact the performance of queries that need to read additional data. You can audit the symbol table efficiency of a table using the following Groovy snippet:
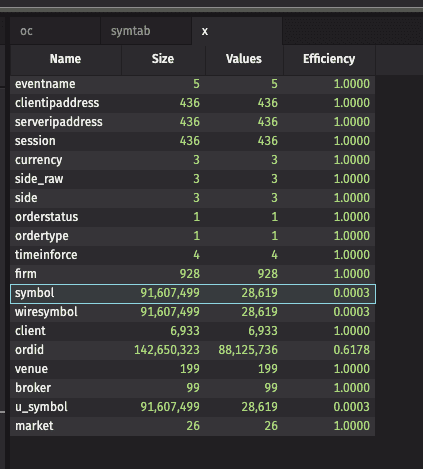
The query produces a table with one row per symbol table column; the “Values” column contains how many distinct values exist for that column, and the “Size” column contains the size of the on-disk symbol table. The “Efficiency” column is the ratio of Values to Size, which is ideally 1.00 (or 100%) for a single partition. When you have tables with multiple partitions, the symbol tables are independent.
You may also see that the number of Values is close to the size of the input table, in which case a symbol table column may not be appropriate (as is often the case for order IDs).
In the following example, we can see that the "symbol", "wiresymbol", and "u_symbol" columns all have low efficiency of only .03%; adjusting the DIS cache hints to allow sufficient headroom for the roughly 30,000 unique values is likely to improve query performance. Additionally, the “ordid” column is a symbol table column, but has over 88,000,000 unique values. Queries and ingestion are likely to be more efficient by changing the schema to include symbolTable="none".