Scaling to multiple servers
Caution
We are in the process of updating the information contained in this document. If you need assistance with the steps/processes described within, please contact Deephaven Support.
This guide shows how to expand a single node running Deephaven into a multi-node installation, and provides the foundation necessary to scale Deephaven to support growing big data analysis requirements. A review of the Large Data Infrastructure and Performance Guidance document should be considered before implementing the changes.
To support a growing infrastructure, Deephaven allows you to easily add more capacity to loading data or querying resources by scaling horizontally. Additional servers or virtual machines running the Deephaven application stack can be configured to add capacity where it is needed.
Three-layer Application Stack Model
Whether a single node or multiple node deployment, the standard Deephaven application stack consists of three core components called layers, allowing for expansion of the layers independently when extra capacity is needed outside of the application software.
- The Network Layer
- The Storage Layer
- The Application Layer
The server deployment discussed in the Deephaven Installation guide implemented these three layers on a single server.
Before breaking out this single server into multiple servers, it is necessary to understand how Deephaven handles data.
Deephaven data lifecycle
The scaling of Deephaven to handle large data sets is mostly driven by the data lifecycle. Deephaven has been designed to separate the write-intensive applications (db_dis, importers) from the read/compute intensive applications (db_query_server, db_query_workers, etc.).
The diagram below shows a generalized version of the processes that are responsible for handling data as part of the Deephaven engine. An external data source can be imported via a stream by generating binary logs that are fed to the Data Import Service (db_dis) process or by manually running an import of data using one of Deephaven' many importers. Once in the system, either type can be queried by end-users via the db_query_server and its workers.
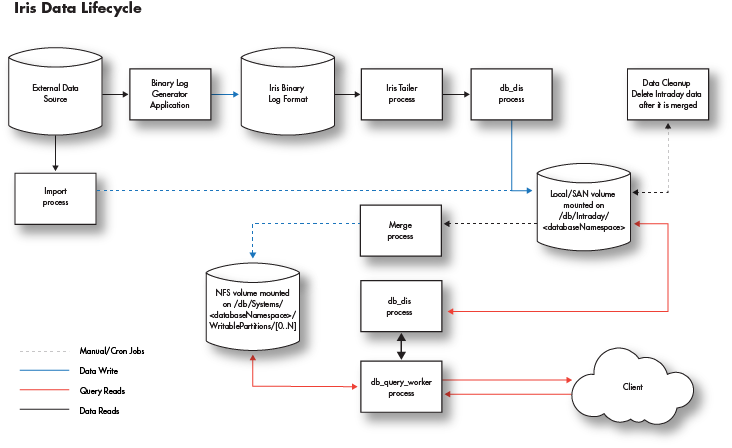
Two types of data
Deephaven views data as one of two data types: intraday (near real-time) data or historical data. Each data type is stored in different locations in the database filesystem.
Intraday data
- Intraday data is stored in
/db/Intraday/<databaseNamespace>/<tableName>. When deploying servers, it is advised that each of these be on low latency, high-speed disks connected either locally or via SAN. All reads and writes of this data are done through this mount point. Depending on data size and speed requirements, one or more mount points could be used at the/db/Intraday,/db/Intraday/<databaseNamespace>, or/db/Intraday/<databaseNamespace>/<tableName>levels - The
db_disprocess reads/writes data from/to these directories. - The
db_ltdsprocess reads data from these directories. - If the administrator doesn't create mount points for new namespaces and/or tables in advance of their use, Deephaven will automatically generate the required subdirectories when data is first written to the new tables.
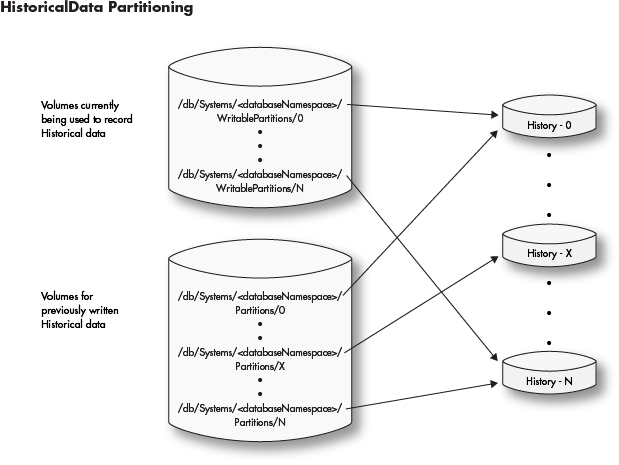
Historical data
-
Historical data is stored in
/db/Systems/<databaseNamespace>. -
Intraday data is merged into historical data by a manual or
cron mergeprocess. -
If the required subdirectories don't exist, an attempted merge will fail.
-
Each historical database namespace directory contains two directories that must be configured by the administrator:
WritablePartitions- used for all writes to historical dataPartitions- used for all reads from historical data The (historical)<databaseNamespace>is divided into aPartitionsandWritablePartitionspair of directories. The subdirectories of these two will contain the data. Each of these subdirectories are either mounted shared volumes or links to mounted shared volumes. Partitions should contain a strict superset ofWritablePartitions. It is recommended that each<databaseNamespace>be divided across many shared volumes to increase IO access to the data. When historical partitions are first set up for a namespace, theWritablePartitionsandPartitionssubdirectories will typically refer to the same locations. For example, if there are six Partitions named "0" through "5", then there will be six links named "0" through "5" in theWritablePartitionsto thosePartitionsdirectories. Over time the devices holding these directories will fill up and additional space will be required. Additional directories (such as "6" through "11) can be created in Partitions pointing to new storage, and theWritablePartitionslinks updated to point to these new directories. This should be done by deleting the old links inWritablePartitionsand creating new ones with the same names as the new Partitions directories. In this way the already written historical locations will become read-only, and future merges will write to the newly allocated storage.
-
All volumes mounted under
WritablePartitionsandPartitionsshould be mounted on all servers. However, since these are divided by read and write functions, you could potentially have a Query Server that only had the read partitions mounted or an Import Server with only theWritablePartitionsmounted. filesystem permissions could also be controlled in a like manner: the Partitions volumes only need to allow read-only access. A server that only performs queries would only need these mounted without theWritablePartitionsif desired. -
A large historical data installation will look like this:
Data lifecycle summary
- Intraday disk volumes (or subdirectory partitions thereof) should be provided for each database namespace via local disk or SAN and be capable of handling the write and read requirements for the data set.
- Intraday data is merged into historical data by a configured merge process.
- Once merged into historical data, intraday files should be removed from the intraday disk by a manually configured data clean up process.
- Historical shared (NFS) volumes (or subdirectory partitions thereof) should be provided for each database namespace via shared filesystem that is mounted under
/db/Systems/<databaseNamespace>/WritablePartitionsand/db/Systems/<databaseNamespace>/Partitionson all servers. - Historical data for each database namespace has
WritablePartitionsfor writing data andPartitionsfor reading data.
Scaling
Deephaven is designed with horizontal scaling in mind. This means adding capacity for services typically involves adding additional compute resources in the form of servers or virtual machines.
When considering how to scale Deephaven, the types of capacity needed should be determined before adding resources.
Scaling capacities
- Read capacity
- Queries requiring access to very large data sets might require more IO bandwidth or substantial SAN caching.
- Add more
db_query_serverprocesses with added IO bandwidth.
- Write capacity
- Handling multiple near real-time data streams quickly (through the Deephaven binary log/tailer/
db_disarchitecture). - Expanding IO for batch data imports or merges.
- Large batch imports of historical data.
- Query capacity (Memory and CPU)
- Queries may take large amounts of memory to handle large amounts of data, a lot of CPU to handle intensive manipulation of that data, or both.
- Support for more end-user queries.
- Support for analysis of large datasets that may consume smaller server's resources.
Server types
- Query servers
- Increase read and analysis capacity of the database for end-users.
- Large cpu and memory servers.
- Run the
db_query_serverand the spawned worker processes.
- Real-time import servers
- Increase write capacity for importing near real-time data.
- Increase write capacity for merging near real-time data to historical partitions.
- Run the
db_disanddb_ltdsprocesses.
- Batch import servers
- Increase write capacity for batch data imports to intraday partitions.
- Increase write capacity for merging batch data to historical partitions.
- Separate the batch data import function away from the near real-time data imports.
- Administrative Servers
- Run administrative Deephaven processes, such as the Deephaven controller, the authentication server, and the ACL write server
- May have additional requirements, such as access to MySQL.
A single host may run multiple server types. For example, the administrative processes do not require many resources, and consequently may be co-located with other services. The hardware information for each server type can be found in Appendix: Server hardware examples.
Single Server Architecture
The Deephaven Installation guide illustrates the provisioning of a server with a network interface and the loopback interface (network layer), local disk storage (storage layer), and the Deephaven software (application layer) to create a single server Deephaven deployment. The guide then used this single server to perform basic operations by connecting to Deephaven from a remote client.
With that in mind, this single-server installation looks like the following:
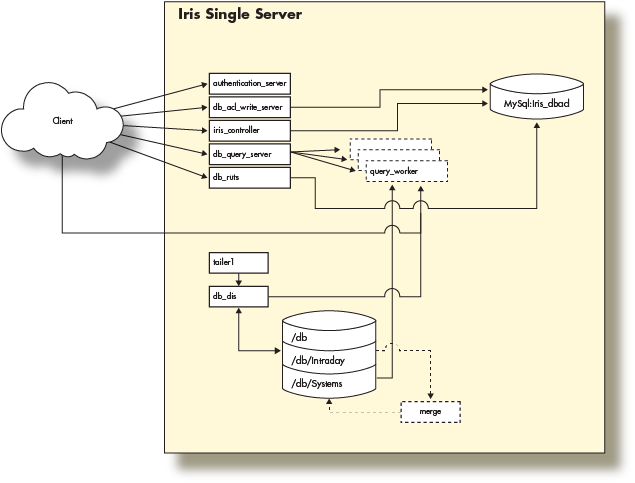
This fully functional installation of Deephaven is limited to the compute resources of the underlying server. As the data import or query capacity requirements of the system grow beyond the server's capabilities, it is necessary to distribute the Deephaven processes across several servers, converting to a multiple server architecture.
Multiple server architecture
The multiple server architecture is built by moving the network and storage layers outside the server, and by adding hardware to run additional data loading or querying processes. The network layer moves to subnets or vlans. The storage layer becomes a shared filesystem that is mounted across all servers. The application layer becomes a set of servers with the Deephaven software installed and configured to perform certain tasks.
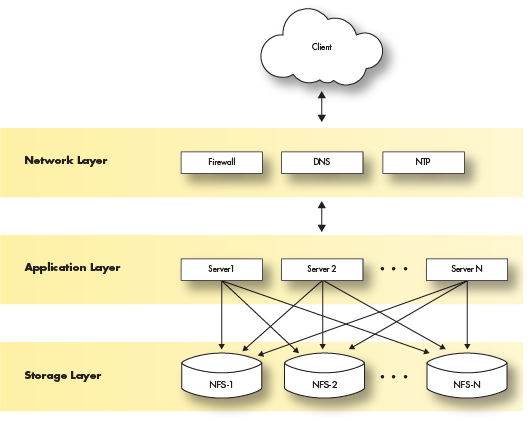
Deploying Deephaven on multiple servers has the following requirements:
- Modification of each layer in the three-layer model.
- Modification and management of the Deephaven configuration.
- Modification and management of the
monitDeephaven configuration.
The network layer
The network and necessary services (DNS, NTP, etc.) is supplied by the customer. Therefore, this document will not cover configuration or implementation of the network except to specify the network services on which Deephaven depends.
Deephaven requires a subnet or VLAN for the servers to communicate. Like all big data deployments, fast network access to the data will benefit Deephaven in query and analysis speed. If using FQDNs in the Deephaven configuration, a robust DNS service is also recommended.
It is recommended that the network layer provide the fastest possible access to the storage layer.
The storage layer
The storage layer has the most changes in a multiple server installation. Deephaven requires access to a shared filesystem for historical and intraday data that can be mounted by each server in the Deephaven environment.
Typically, these disk mounts are provided via the NFS protocol exported from a highly available storage system. Other types of distributed or clustered filesystems such as glusterFS or HDFS should work but have not been extensively tested.
As mentioned, Deephaven relies on a shared filesystem architecture for access to its data. Currently, the larger installations use ZFS filers to manage the storage mounts that are exported to the query and data import servers via NFS over 10g network interfaces.
Deephaven divides data into two categories:
- Intraday data is any data that hasn't been merged to historical storage partitions, including near real-time as well as batch-imported data. Depending on the data size and rate, the underlying storage should typically be high-throughput (SSD) or contain sufficient caching layers to allow fast writes.
Intraday data is written to the database via the Data Import Server or other import processes onto disks mounted on
/db/Intraday/<namespace>/. - Historical data is populated by performing a merge of the Intraday data to the historical file systems. As storage needs grow, further storage can be easily added in the form of writable partitions without the need to reorganize existing directory or file structures, as Deephaven queries will automatically search additional historical partitions as they are added.
Intraday data is typically merged to Historical data on the Data Import Servers during off hours by scheduled processes.
The historical disk volumes are mounted into two locations on the servers:
- For writing:
/db/Systems/<databaseNamespace>/WritablePartitions/[0..N] - For reading:
/db/Systems/<databaseNamespace>/Partitions/[0..N]
- For writing:
The Deephaven application layer
The software installation procedure for each server does not change from that posted in the Deephaven installation guide. Once the server is deployed, the network storage should be mounted on all the servers. Once this is done, the main configuration of Deephaven must now be managed and the Monit configuration modified to only run processes for each server type.
Users and groups
Deephaven requires three unix users and five unix groups that are created at install time by the iris-config rpm.
The uid and gids associated with the users and groups need to be created on the shared storage to allow them to read and write to the mounted file systems.
| Group Name | gid | Members |
|---|---|---|
dbquery | 9000 | dbquery |
dbmerge | 9001 | dbmerge |
irisadmin | 9002 | irisadmin |
dbmergegrp | 9003 | dbquery, dbmerge, irisadmin |
dbquerygrp | 9004 | dbquery, dbmerge, irisadmin |
| User Name | uid |
|---|---|
dbquery | 9000 |
dbmerge | 9001 |
irisadmin | 9002 |
Deephaven server types
In the Scaling section we described four server types: Data Import Server, Batch Import Server, Query Server and an Infrastructure Server. Each of these server types is defined by the Deephaven processes they run and defined by the hardware resources required for each. You can also easily combine server types into a single server to provide both sets of functionality given sufficient hardware resources. For instance, it is common to have administrative servers combined with a data import server.
As an example, a query server will require more CPU and memory than an administrative server, which requires a smaller CPU and memory footprint.
Example server types and associated resources are outlined below.
Administrative server
Server Hardware and Operating System
- 6 cores (2 core minimum) @ 3.0 Ghz Intel
- 10GB RAM
- Linux - RedHat 7 or derivative
- Network: 1g
- Storage:
- Root - sufficient local disk space
Processes
- MySql - ACL database
authentication_server- Securely authenticates users on logindb_acl_write_server- Serves as a single writer for ACL information stored within the ACL databaseiris_controller- Specialized client that manages persistent query lifecycles, and provides discovery - services to other clients for persistent queries
Real-time import server
Server Hardware and Operating System
- 24 cores (6 cores minimum) @ 3.0 Ghz Intel
- 256GB RAM (32GB minimum)
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Intraday data - SSD either local or iScsi
- Historical data - NFS mounts for all historical data
Processes
db_dis- receives binary table data from user processes and writes it to user namespaces, simultaneously serving read requests for samedb_ltds- serves read requests for local data, used for serving intraday data not managed bydb_disTailer1- The
tailer1application sends data from the processes in the stack to thedb_disfor theDbInternalnamespace. - A tailer application is used to read data from binary log files and send them to a
db_disprocess. - Tailer configuration is covered in Importing Data.
- The
Batch import server
Server Hardware and Operating System
- 24 cores (6 cores minimum) @ 3.0 Ghz Intel
- 256GB RAM (32GB minimum)
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Intraday data - SSD either local or iScsi
- Historical data - NFS mounts for all historical data
Processes
- Batch import processes run via
cronor manually to load intraday data from external data sources such as CSV files - Validation and merge processes run via
cronor manually to validate intraday data and add it to the historical database - Scripts to delete intraday data after it has been successfully merged
Query server
Server Hardware and Operating System
- 24 cores (6 cores minimum) @ 3.0 Ghz Intel
- 512GB RAM (32GB minimum)
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Historical data - 16 NFS mounts @ 35TB each
Processes
db_query_server- manages query requests from the client and forksdb_query_workerprocesses to do the actual work of a query
Deephaven resilience planning
High availability, fault tolerance, and disaster recovery
These topics have some amount of overlap. In the context of this document:
- High availability - continued operations with short downtime and some manual actions needed by administrators and/or users.
- Fault tolerance - continued operations with no user awareness of an issue other than possibly degraded performance.
- Disaster recovery - resuming operations after a significant loss of data center functionality or connectivity.
Besides the consideration of system availability, there is also planning for recovery time, tolerable data loss, and what amount of data reloading, if any, is acceptable in case of a failure. Typically, these are referred to as:
- Recovery Time Objective (RTO) - maximum down time after a system failure.
- Recovery Point Objective (RPO) - maximum acceptable data loss from a system failure.
Deephaven services and dependencies
3rd party services that support Deephaven clusters:
| Service Name | Location | FT Capability |
|---|---|---|
| etcd | Any servers, even separate nodes. | Automatically fault tolerant with 3 or more odd numbers of nodes. |
| MySQL/mariadb | Typically infra, but could be anywhere. | Some editions support clustering; default is not fault tolerant. |
| lighttpd | Infra | Not FT, but possible to add multiple CUS instances (which is the only service using this dependency), or switch to a different Web server. See client_update_service. |
| envoy | Infra (optional) | Possible to build a cluster. Usually running in docker, so easy to replace. |
| jupyterhub | Infra (optional) | Possible to build a cluster. |
Deephaven services:
| Service Name | Location | FT Capability |
|---|---|---|
configuration_server | Initially infra, can be on all DH nodes | Adding instances allows for fault tolerance. |
authentication_server | Typically infra, but can add others | Adding instances allows for fault tolerance. |
web_api_service | Infra. | Not fault tolerant. Web consoles and OpenAPI are dependencies. |
tailer | Can be anywhere in an environment. | Individual tailers are not fault tolerant, but multiple tailers can provide redundant processing. If a tailer fails, a new tailer typically starts where the previous one ended. |
log_aggregator_service | One per DH server. | Not FT, but scope of impact is one server. |
iris_controller | Infra. | Single point of failure for the DH install. Its data is protected by storage in etcd. A warm backup for the infra node would provide the best HA. |
db_tdcp | Usually one per DH server. | Not FT, but scope of impact is one server. Its use is optional. |
db_merge_server | Initially infra; can have additional instances. | Individual merge servers are not fault tolerant, but multiple merge servers can provide redundant processing. |
db_query_server | Each query server. | Individual query servers are not fault tolerant, but also don't own data resources, so other query server instances can run tasks that had been running on a failed node. |
db_ltds | Each merge server. | Redundant LTDSs can be configured for round robin and failover in the data routing setup. |
db_dis | Initially infra, but can add others | Redundant DISs can be configured for round robin and failover in the data routing setup. |
db_acl_writer | Usually whereever there is an authentication_server | Not FT. Loss of this service would prevent changes to DB permissions and accounts. |
client_update_service | Largely a wrapper around lighttpd (above). | Not inherently fault tolerant. Inability to launch new Swing consoles is the main user impact. Possible to manually add redundant instances and front them with Envoy to provide FT. |
In a default three-node Deephaven installation, the inherent fault tolerance is limited to losing one node of the three-node etcd cluster with no noticeable impact. It is, however, unlikely that a single instance of etcd will fail without a corresponding failure of the server on which it is running. In a default Deephaven installation etcd will be running on each of the three nodes (infrastructure and two query servers).
Loss of the infrastructure node will make the entire installation unavailable, as no workers can be launched without the authentication and controller functions which are hosted on the infrastructure node.
Loss of a single query server is a moderately disruptive high availability event. At the minimum, loss of a query server would mean that users would need to move their queries to the remaining query server. If the lost query server was Query1, then system PQs, such as the WebClientData query, would also need to be moved to re-enable functionality such as Web UI logins. There is also the question of whether the remaining query server will have sufficient capacity to host at least all critical queries. A good starting point for planning high availability is an n-1 approach when selecting the number of query servers.
Workload placement for queries allows PQs to have their query servers auto-selected. This allows for transparent failover in the case of loss of a query server, as long as there are sufficient compute resources available in the environment.
Data and configuration storage and sharing
The general recommendation for production Deephaven installations is at least three nodes. In this configuration, the sharing of configuration and data across nodes is:
- Configuration (properties, routing settings, persistent queries, schemata) - stored in etcd, which provides fault tolerance automatically when it has an odd number of nodes >= 3.
- Intraday data (including intraday user tables) - stored in the
/db/Intradayand/db/IntradayUserdirectory structures for the main DIS, and under specific directories for in-worker DIS / ingester processes. - User tables - stored under
/db/User- should be shared across servers using NFS or similar so users can access their data from any server. The array providing or backing NFS should also provide data protection and fault tolerance. - Historical tables - stored under
/db/Systems- should be shared across servers using NFS or similar so users can access their data from any server. The array providing or backing NFS should also provide data protection and fault tolerance. - Web dashboards and other UI content - stored in the
DbInternal.WorkspaceDatatable. This table should have merges run for it to consolidate historical dashboard changes from intraday to historical. Loss of intraday data will also result in loss of unmerged Web UI content. - Some aspects of configuration, such as
ClientUpdateServicesettings, and custom jars - stored under the/etc/sysconfig/deephavenpath. It may be desirable to share some of these paths, such as/etc/sysconfig/deephaven/illumon.d.latest/java_lib/, so that things like custom jars are available from all servers.
Failure modes to plan for
In cases where Deephaven servers are running on virtual machines, concerns about likely failure modes are somewhat different than they are when the servers are physical machines.
Virtual machines can still lose locally attached storage through an underlying hardware failure. In such cases, restoring/replacing the machine from a recent snapshot image/backup should allow fairly quick restoration of functionality. If the server in question was a query server, there should normally be no data loss associated with the event. If it was a merge server (infrastructure node in a default deployment), there will be loss of intraday data imported and/or ingested since the snapshot was taken. Ideally, local storage used for at least data import server nodes should be fault tolerant as well - e.g. RAID 1 or RAID 5. Other than a local storage failure, though, hardware failures should not be a concern for virtual machines - loss of the motherboard, bad memory, a failed NIC, etc, would all be handled by reprovisioning the VM to a different host in the data center.
For historical data, the shared storage system should be responsible for providing fault tolerant protection of data. At the minimum, the storage underlying NFS, or similar shared storage, should provide some sort of single-device-loss tolerant RAID. At the more robust end of possibilities would be a geo-cluster that synchronizes data between storage arrays in two data centers, allowing for a DR backup Deephaven installation that has access to a replicated copy of the same data available in the primary installation.
The more common type of issues that will disrupt availability of a service or services in a Deephaven installation are software and configuration based:
- Out of disk space (probably the most common cause of failures).
- Expired certificates.
- Misconfiguration of a key service.
- Change of DNS causing inability to resolve names.
- Change of IP addresses breaking the etcd cluster (etcd requires permanent IP addresses for its nodes).
- Upgrade or patching of a dependency service or package making it incompatible with other components.
- Configuration management software (Puppet, Chef, Ansible, etc) disabling or uninstalling required components or accounts.
- Endpoint protection software blocking packets or connections.
- Stateful firewalls unnecessarily closing connections it sees as inactive.
Most of the above are not things that high availability is meant to combat, and, in most cases such issues will impact all instances of redundant services in a single environment, so high availability cannot address them. Having additional installations, locally, and/or remotely, however can provide for a backup environment to be used while the issue is analyzed and resolved. For these reasons, and others, it is strongly recommended that Deephaven customers have several installations such as:
- Production
- Test/QA/UAT - for testing upgrades of Deephaven product, patches, and new customer code and queries.
- Development - for developing new customer code and queries.
- Prod backup - a DR backup environment in the same data center as the prod installation.
- DR - a DR backup environment in different data center from the prod installation.
In general, DR and Prod backup installations should have access to all of the same historical, user, and streaming data that production has, so these environments can provide business continuity in case the production installation, or even the entire production data center, is down. Depending on the types of validations and development being done, test and development installs may be able to work with subsets of data and less compute/storage resources.
A DR "environment" may be as simple and lightweight as snapshots of VMs that can be deployed in a different virtual data center in case of loss of the primary data center; assuming that needed data is replicated and snapshots are taken frequently enough to meet the recovery point objectives. At the other extreme would be a complete duplicate of the primary production cluster that runs continuously in parallel with the primary installation, so that users could switch to DR immediately when needed, with no loss of data. Intermediate solutions might involve having a continuously running infrastructure server and etcd nodes, but with query servers powered off until the DR environment is needed.
Data Ingestion
Streaming data ingestion typically follows a couple of different models:
- A data stream is subscribed by a custom process.
- The custom process uses a Deephaven logger class to append events to binary log files.
- A Deephaven tailer streams blocks of binary data from the binary log files to a data import server (DIS).
- The DIS writes events to disk and publishes them to ticking table clients.
- Some processing somewhere results in a Kafka or Solace topic.
- A Kafka or Solace ingester running in a merge server query subscribes to the topic.
- The ingester receives events from the topic, writes them to disk, and publishes them to ticking table clients.
For either model, the intraday data received may be merged to historical at some point: EOD, etc.
For the first model, redundancy can be set up at several levels. Usually the logger process and tailer are local to each other and are also co-located on a system that has low-latency access to the source data stream. One option is to configure multiple data import server processes, at a minimum on multiple nodes of a single installation, but, also possibly in other installations such as prod backup or DR, and have the single tailer send data to these multiple destinations. A more resilient option would be to have a separate logger and tailer system for each DIS destination, so that the entire data stream is redundant back to its source (which probably has its own fault tolerance).
For the second model, Kafka and Solace both have their own fault tolerance capabilities which can be configured to ensure uninterrupted processing of the topic. On the Deephaven side, multiple ingester PQs can be configured on multiple merge servers in one or several installations.
For the case of multiple DIS services or ingester PQs feeding data into a single Deephaven installation, the table data services in the routing YAML can be configured as arrays, to allow automatic round robin handling and failover in case of loss of one service. This configuration will load balance between db_dis and db_dis2, but fail all activity over to db_dis2 if db_dis becomes unavailable. Each DIS instance will need its own data storage for this configuration.
For the eventual merge of data to historical, if, for example, there are DIS1 and DIS2 that both provide a particular ticking table: on a normal day, the data from DIS1 would be merged, and the data from DIS2 would be discarded. On a day when DIS1 had failed, though, the partial data from DIS1 would be discarded, and the complete data from DIS2 would be merged instead. In the extremely unlikely event that both DIS1 and DIS2 were offline for part of the day, manual work might be needed to consolidate and deduplicate the data set of their combined partial tables, and then a merge could be run from that. This would not necessarily be required, though, because tailer binary logs and Kafka and Solace topics persist data even if the DIS is unable to receive it, so, a DIS outage would normally result in the DIS catching up when it was brought back online, resulting in no missing data by the end of the day.
Multiple server deployment
In this section, we will show how to deploy the Deephaven components in a multi-server environment. We will deploy:
- One server combining a Data Import Server with an Infrastructure Server.
- Two Query Servers.
The solution will also depend on a storage volume that needs to be available to mount from each of the Deephaven servers.
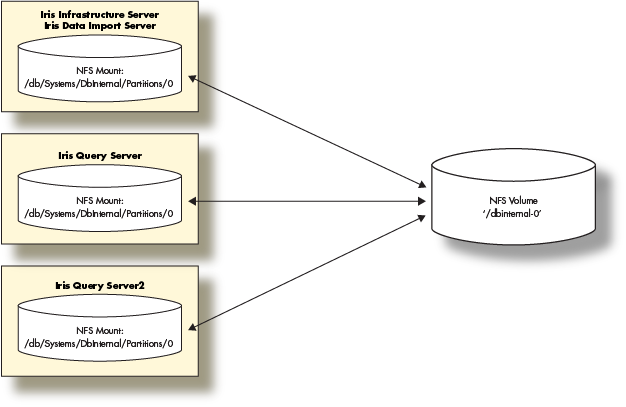
Prerequisites
- A storage layer (e.g., NFS Server) with exported volumes available to the deployed Deephaven servers.
- Deephaven ships with a schema using the namespace
DbInternalwhich contains query performance data among other data. After the Deephaven software install, there will be directories in/db/Intraday/DbInternaland /db/Systems/DbInternal. - In this deployment, we will mount a NFS volume for the
DbInternalhistorical data and use that to demonstrate the steps involved to provide historical data volumes for any namespace.
- Three servers or VMs with at least the minimum physical or virtual hardware resources.
Prepare the storage layer (NFS Server)
- Assure the Deephaven users and groups are able to read and write to any NFS exports.
- Create a data volume on the storage server to hold the Historical data.
- This will be the first historical volume for the 'DbInternal' namespace so we will call it 'dbinternal-0'.
DbInternalhistorical does not use very much space. 10g should be sufficient.
- Export the
dbinternal-0data volume.
Deploy the Deephaven Servers
- Provision three servers using the procedures outlined in the Deephaven Installation guide. Note: You will need to substitute the hardware sizing in this guide for those provided in the Installation Guide.
- Install the Deephaven Software on each Server. When installing Deephaven, there are two packages to install: the Deephaven Database package and Deephaven Configuration package. Your Deephaven account representative will provide you with the latest versions of these two packages. To install the software, you will first need to copy the packages onto your provisioned Deephaven Linux host. Once the packages have been copied to the host, you should SSH onto the server and run the following commands to install the Deephaven Database and the Deephaven Configuration packages:
The installation includes a default set of configuration files and sample data for a basic Deephaven installation. 3. Install MySql Java Connector Software:
Deephaven uses MySql (mariadb) to store authentication and database ACL information. This requires the mysql-connector-java JAR to be installed into /etc/sysconfig/illumon.d/java_lib:
Configure Deephaven software on each server
Setup the Historical Partition on each server
- Verify the
DbInternalhistorical mounts:ls -l /db/Systems/DbInternal/ - Two directories should exist:
WritablePartitionsandPartitionsand be owned by the userdbmerge. If not, you can create them and set the proper permissions. - Mount the
DbInternal-0NFS volume on the providedPartitions/0sub-directory:
- Verify the link from
WritablePartitions/0to theParititions/0mount exists: If the symbolic link does not exist, create it as follows:
Update the iris-common.prop on each server
The default configuration file comes configured with localhost for all the services. Update the properties by replacing all localhost values with the ip or FQDN of the data import/infrastructure server.
Update the following properties in /etc/sysconfig/illumon.d/resources/iris-common.prop:
Modify the smtp properties to send critical error emails to a defined location. Note these properties must be able to connect to a valid smtp server. If you don't have one, localhost should work for most installations:
For each query server IP addresses or FQDNs modify the following property and add any additional properties beyond the first one. There should be one for each query server:
Adjust the total count property for the total number of query servers:
Update the query_servers.txt
All query servers that are made available to end-users to run queries need to be listed in the /etc/sysconfig/illumon.d/resources/query_servers.txt file.
The default setting is localhost. Replace the contents of this file with a list of the IP addresses or FQDNs of the servers you designated as the query servers one per line.
For example:
Custom configuration for Data Import/Infrastructure Server
Configure the Client Update Service on Data Import/Infrastructure Server
If you haven't already, configure the Client Update Service to make the remote client available.
- On the Deephaven Server, edit the
/var/www/lighttpd/iris/iris/getdown.txt.prefile:
Set the appbase value, replacing WEBHOST with the host address of your Deephaven infrastructure server. The following example demonstrates using 10.20.30.40 as the host address:
- In the Monit config folder, remove the
.disabledextension from the Client Update Service config file name.
Configure Monit on Data Import/Infrastructure Server
The Deephaven Monit configurations are located in /etc/sysconfig/illumon.d/monit/.
Each Deephaven process has its own Monit configuration file. Any configuration with a .conf file extension will be loaded by Monit and started. To disable an individual process, change the file extension to anything else.
We use .disabled to easily recognize which services are not under Monit control.
- Disable the
db_query_server. Run the following commands:
- Restart Monit:
- To check the state of the Deephaven processes run:
The output should look something like this:
Configure query servers
Configure Monit on query servers
- To disable all processes, except the
db_query_serverprocess, run the following commands:
- Restart Monit:
- To check the state of the Deephaven processes run:
The output should look similar to the following:
Final steps
Congratulations. Deephaven is now running on three servers with two servers serving queries for end users.
The next steps are to set up nightly merges of Intraday data to the Historical data volume mounted and for users to connect to Deephaven using the Deephaven Console.
Nightly merge jobs
To merge the query performance Intraday data to the Historical data volume mounted, run the merge command on the infrastructure server:
This command should be added as a nightly cron job on the infrastructure server:
Deephaven Console installation
End users can now use the Deephaven Console client application to access Deephaven and begin executing queries.
Deephaven ships with a schema using the namespace DbInternal which contains query performance data among other data. This data can be queried from the Deephaven Console as follows:
Appendix: Server hardware examples
The example servers come from a cross-section of other large data installations running Deephaven.
Infrastructure Server
The Infrastructure Server handles the authentication, acl and other tasks of running Deephaven. This server requires very few compute, disk or memory resources.
Hardware and Operating Systems
- 6 cores @ 3.0 Ghz Intel
- 10GB RAM
- Linux - RedHat 7 or derivative
- Network: 1g
- Storage:
- Root - sufficient local disk space
Intraday Import Server
The Data Import Server is mainly a write-centric server with access to fast storage. Typically, this will be an SSD or volumes of SSDs, depending on the data speed and storage size required.
Hardware and Operating Systems
- 40 cores @ 3.0 Ghz Intel
- 256GB RAM
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Intraday data - Sufficient space consisting of SSD either local or iScsi
- Historical data - 16 NFS mounts @ 35TB each
Query Servers
Query servers provide compute, memory and query access to storage. They host the memory-intensive applications.
Hardware and Operating Systems
- 40 cores @ 3.0 Ghz Intel
- 512GB RAM
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Historical data - 16 NFS mounts @ 35TB each
Batch Import Servers
Import servers are similar to Intraday Import Servers, but are less write-intensive. They are used to perform large-batch imports of data, typically overnight.
Hardware and Operating Systems
- 24 cores @ 3.0 Ghz Intel
- 192GB RAM
- Linux - RedHat 7 or derivative
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Intraday data - Sufficient space for the import via local, iScsi, nfs or other
- Historical data - 16 NFS mounts @ 35TB each
Appendix: Methodologies for mounting historical NFS partitions
- Historical data is stored in
/db/Systems/<DATABASE_NAMESPACE>. - File read operations for a particular namespace are performed through the file systems mounted under
/db/Systems/<DATABASE_NAMESPACE>/Partitions/0..N. - File write operations for a particular namespace are performed through the filesystems mounted under
/db/Systems/<DATABASE_NAMESPACE>/WritablePartitions/0..N. - The two sets of directories can be on local disk, on a shared filesystem, an NFS volume or be a set of soft links to other directories
- It should be noted that the
WritablePartitionscan be a subset of thePartitionsdirectories if you only require a small amount of IO bandwidth
There are three methodologies for mounting NFS partitions. By default, Deephaven uses the Partial Indirect Mounting option that links the WritablePartitions as a subset of the NFS volumes mounted under each Partitions directory.
In large deployments, customers often use the Indirect Mounting option to allow for maximum flexibility. By soft linking both the Partitions and the WritablePartitions to the mount point of the NFS volume. This allows changing the NFS mounts to which Deephaven is writing data by simply removing a soft link or changing the soft link to point to another NFS mount.
Historical data methodologies
There are three options for creating historical data directories and mounts.
Direct Mounting
Direct Mounting should only be used in small data installations where only a handful of mounts are required.
Adding additional storage would require creating similarly numbered directories and mounting more NFS volumes.
As an example, the namespace-0 NFS volume is mounted directly to the Partitions and WritablePartitions sub-directories:
If additional storage beyond this is required, a second partition namespace-1 would be created.
Two more mount points would be created and the new NFS volume mounted under each:
Additional partitions would be added in this manner as the system expands.
Partial Indirect Mounting
With Partial Indirect Mounting, each NFS volume is only mounted once under /db/Systems/<NAMESPACE>/Partitions/0..N. The /db/Systems/<NAMESPACE>/WritablePartitions/0..N are then soft linked to their counterparts under /db/Systems/<NAMESPACE>/Partitions/.
Additional file systems would be added under /db/Systems/<NAMESPACE>/Partitions/ and then soft links would be created under the WritablePartitions directory.
Full Indirect Mounting
The most flexible methodology, Full Indirect Mounting, allows each individual mount to be customized, or moved with minimal impact to Deephaven. By soft linking, both /db/Systems/<DATABASE_NAMESPACE>/Partitions/0..N and /db/Systems/<DATABASE_NAMESPACE>/WritablePartitions/0..N the underlying NFS file systems can be switched out by changing a link, or removed from service by deleting the link altogether.
The namespace-0 NFS volume is mounted elsewhere on the server and soft links are created to both the Partitions and WritablePartitions directory.
Adding additional storage or IO bandwidth is mounted under /srv/<NAMESPACE> directories, and new soft links are created for Partitions or WritablePartitions.
Advanced installation guide