Table storage
Data categories
At the highest level, Deephaven divides persistent data according to two criteria:
- Namespace type (System or User)
- Availability type (Intraday or Historical)
Namespace type
Namespace type is used to categorize data broadly by its purpose and importance.
System namespaces
System namespaces are those that are subject to a structured administrative process for updating schemas as well as for importing, merging, and validating data. Their schemas are defined via Deephaven schema files, which are often kept in version control systems for collaboration and revision history tracking, and updated on a business-appropriate schedule by administrative users. Queries cannot directly modify tables in these namespaces via the Database APIs, and are typically run by a user without the necessary filesystem permissions to modify the underlying files.
Any data that is important for business processes or used by many individuals should be in a system namespace.
User namespaces
User namespaces are directly managed by unprivileged users via the Database APIs. They typically do not have external schema files, and are usually exempted from other administrative processes.
User namespaces are typically used for persisting intermediate query results, or for testing out research ideas. It is easy and often appropriate to migrate data from a user namespace to a system namespace if it becomes more important than originally conceived.
Availability type
Availability type is used to categorize data by its timeliness and stability. Note that it's somewhat less meaningful to talk about intraday data for user namespaces, but not entirely irrelevant.
Intraday data
Intraday data for system namespaces is internally partitioned (usually by source) before applying column partitioning, and stored within each partition in the order in which it was received. It may be published in batches, for example via offline import, or it may be appended in near real-time as data becomes available.
User namespaces do not necessarily follow the same convention for internal partition naming.
Historical data
Historical data for system namespaces is partitioned according to storage load-balancing criteria (as documented in Tables and schemas) before applying column partitioning, and is converted from intraday data using the merge process. It is often re-ordered during the merge by applying sorting or grouping rules, but relative intra-source order is preserved otherwise. Validation processes take place after the merge in order to ensure that the newly available historical data matches the intraday data it was derived from and meets other domain-specific invariants.
Table layouts and data partitioning
Deephaven currently supports two possible table layouts:
- Splayed tables are simple column-oriented data stores without any partitioning, meaning they are stored in one location directory. They are typically used for storing query result sets as tables in user namespaces.
- Partitioned tables are hierarchical stores of many splayed tables, with each splayed table representing a single partition of the data. Partitions are automatically combined into a single table for presentation purposes by the Deephaven query engine, although this step is deferred for optimization purposes by well-crafted queries.
In practice, all system namespace tables are partitioned, although user namespace tables may also use this layout.
The partitioning scheme currently used by Deephaven is referred to as nested partitioning (see the example below for reference), and is implemented by using a different directory for each partition. This permits two levels of hierarchy, which function as follows:
- The top level of the hierarchy (e.g., IntradayPartition1, IntradayPartition2, or PartitionName1, PartitionName2 in the examples) is hidden from user queries, but serves multiple purposes.
- For historical system data, this partitioning allows storage boundaries to be introduced for load balancing purposes. Also, queries may leverage grouping metadata in individual partitions to defer indexing work in some cases.
- For intraday system data, this partitioning serves to keep data from distinct sources in different locations. For example, if there are two different processes writing data into the same table, they must write into different top-level intraday partitions to keep the data separated.
- For user data, this partitioning is optionally used to allow parallel publication or to achieve other user goals.
- The bottom level of the hierarchy (e.g., Date1, Date2 in the example) is visible to user queries as a partitioning column, typically with a descriptive name like Date. This efficiently limits the amount of data that must be read by allowing the query engine to prune the tree of partitions (directories) that need not be considered. Users must place filters using only the partitioning column ahead of other filters in a where clause to take advantage of these benefits.
Filesystem data layout
Design goals
In specifying the layout for Deephaven data and metadata, two paramount goals are emphasized:
- Decentralization - Deephaven avoids the need for a centralized server process that uniquely administers access to the database files.
- Ease of administration - Deephaven databases, namespaces, and tables are laid out in such a way that:
- It is easy for administrators to introduce filesystem boundaries for provisioning purposes, e.g., between user and system tables, or for the various storage partitions of a given system namespace's tables.
- Adding, moving, or removing database objects can be done with standard file operations, whether operating on the database itself or on a single namespace, partition, table, or column.
Locations
Deephaven tables use two levels of partitioning:
- Internal partitions divide up data. For intraday tables this is usually to separate data coming from multiple sources. For historical data, this is to allow distribution of data across multiple storage devices.
- Partitioning values (typically a date string based on when the data was generated), allow natural division of large tables into more manageable "chunks". This type of partitioning works the same for both intraday and historical tables.
A location is the directory that corresponds to a particular combination of internal partition and partition value for a table. For instance, if a historical table has three writable partitions, and uses Date for its partitioning column, partition 1 with Date=2018-01-04 would be an example of a location for this table. The location is the lowest directory in the table directory structure, and will contain column data files and other table metadata files corresponding to that location's "slice" of the table.
Root Directories
Every Deephaven installation defines a database root directory, usually /db.
- Intraday data for system namespaces is stored under the the database root in the Intraday directory, entirely separate from historical data.
- Historical data for system namespaces is stored under the database root in the Systems directory.
- User namespace data is stored under the database root in the Users directory.
- Administrators may choose to create an intraday data directory for user namespaces when configuring support for centrally-appended user data, but this is optional.
Each of these directories contains a well-defined set of subdirectories.
Intraday
This contains all the Intraday data with subdirectories as shown below.
Note that the table name is in the directory structure twice. This is intentional.
- The first level (under the namespace) allows easy management of all the data for any table. For example, if a table is not needed any more, it can be deleted at that level.
- The second level (at the final level of the directory tree) is symmetrical with the historical directory structure layout (see below), allowing easy portability when desirable.
For a concrete example, the directory containing the intraday data files for a single date partition for the DbInternal Persistent Query State Log table might be:
/db/Intraday/DbInternal/PersistentQueryStateLog/myhost.illumon.com/2017-08-04/PersistentQueryStateLog/
Historical (Systems)
The Systems subdirectory contains all the historical data with subdirectories as shown below.
For example, an initial layout for the DbInternal namespace might be as follows, showing only the Partitions and Writable Partitions subdirectories. Data is being written to and read from the internal partition called "0".
Note
Once the initial partitions to which data is being read exceed storage capacity, new partitions and links should be created by the sysadmin as demonstrated below. At this point new data is being added to the internal partition called "1", but read from both "0" and "1".
For a concrete example, the directory containing the historical data files for a single date partition for the DbInternal persistent query state log table might be:
/db/Systems/DbInternal/Partitions/0/2017-08-03/PersistentQueryStateLog
Users
The Users subdirectory follows the same layout as the Systems subdirectory, except it also has the Tables directory for non-partitioned splayed tables, and lacks WritablePartitions.
Location indexing
If a query for a historical table is executed in a Deephaven console without partitioning column values, such as quotes=db.t("LearnDeephaven","StockQuotes"), the system must determine what partition values exist, so they can be displayed for the user to select from. This is traditionally accomplished by scanning the directory structure under /db/Systems/LearnDeephaven to find all the locations. For tables with a large number of Partitions, and a large number of partition values, this process could take a relatively long time.
In the more common case, where a query's first .where() is selecting a single partition value — quotes=db.t("LearnDeephaven","StockQuotes").where("Date=2017-08-25")`` — the system still must find all 2017-08-05 directories that exist under the partitions for /db/Systems/LearnDeephaven` before it can begin retrieving data for this date.
To improve performance, .tlmi files cache all the partition values and their locations in a single file per table. This allows the system to find table locations by reading one known file, rather than scanning the filesystem, resulting in much faster initial response time for queries against tables that have a large number of locations.
Location indexing is enabled by default. Normally, the only changes to historical data locations occur when new partition values are written during the merge process. Location indexing can be disabled by setting:
LocalMetadataIndexer.enabled=false
Manual indexing
The manual indexing process must be run when first upgrading to a version of Deephaven that supports Location Indexing, or after reconfiguring data outside of merge. Examples of reconfiguration outside of merge include deleting locations, or copying partial or complete historical tables from one installation to another.
The manual indexing command is:
This command takes the following optional arguments (in the order specified):
- Namespace set - If not specified, all tables in the System namespace set will be indexed. (The only input currently supported is System.)
- Namespace - This specifies a particular namespace with System to index.
- Table Name - If specified, only the specific table within the specified namespace will be indexed. If not specified, all tables in the specified namespace set and namespace will be indexed.
Examples of using the indexer command
Index all System tables:
Index all the tables within the System namespace ExampleNamespace:
Index the System table ExampleTable in ExampleNamespace:
Rerunning the indexer command on a system that has already been indexed will replace the .tlmi files with refreshed versions, even if nothing has changed.
Grouping
Data within a given historical table may be grouped according to one or more columns. For example, a table named Quotes might be grouped by UnderlyingTicker and Ticker. This means that rows within a single partitioned table location or splayed table are laid out such that all rows with the same value for UnderlyingTicker are adjacent, as are all rows with the same value for Ticker.
Deephaven requires that tables with multiple grouping columns allow for a total ordering of the grouping columns such that each unique value group in later columns is fully enclosed by exactly one unique value group in each earlier column. That is, groups in more selective grouping columns must have a many to one relationship with groups in less selective grouping columns.
This type of relationship is natural in many cases. For example, UnderlyingTicker and Ticker can be used together because they form a hierarchy - no Ticker will belong to more than one UnderlyingTicker. In this way, grouped data is similar to how entries are sorted in a dictionary, or how a clustered index is modelled in a relational database.
Here's an example of a valid multiply-grouped table, with grouping columns UnderlyingTicker and Ticker:

Here's an example of an invalid multiply-grouped table, with grouping columns LastName and FirstName:
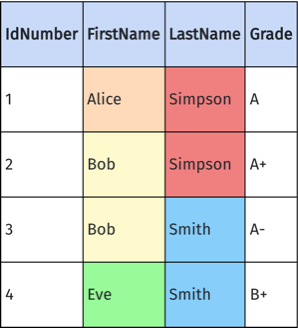
Note that the FirstName group Bob can't be enclosed within a single LastName group - it overlaps with both Simpson and Smith. Deephaven will generate an error when attempting to merge this data with these groups - one grouping or the other must be chosen.
Grouping allows for three categories of optimization:
- Indexing - Grouping columns are automatically indexed (grouped) by the database, allowing for much faster filtering operations for match operations. Example:
quoteTable.where("UnderlyingTicker=`AAPL`") - Locality - When filtered by grouping columns, data often has much better locality on disk, allowing for more efficient retrieval (
selectorupdate) operations. Example:quoteTable.where("UnderlyingTicker=`AAPL`").select() - Implied Filtering - Filtering on a grouping column implies filtering on all earlier grouping columns. Example:
quoteTable.where("UnderlyingTicker=`AAPL`", "Ticker in `AAPL100918C00150000`, `AAPL100918C00155000`"contains a redundant filter,"UnderlyingTicker=`AAPL`"
Deephaven groups data (and enforces rules on multi-column groupings) when merging intraday data for system namespaces to historical data, according to the column types specified in the schema files.
File extensions
Splayed table directories contain a number of files, including the following types:
.tblfiles store table metadata, including the storage layout (e.g., splayed, partitioned) and the order, name, data type, and special functions (if any) of each column..datfiles store column data sequentially, prefixed by a serialized Java object representing metadata..ovrfiles store overflow metadata for .dat files of the same name..bytesfiles store BLOBs (Binary Large OBjects) referenced by offset and length from their associated.datfiles..symfiles provide a table of strings referenced by index from their associated.datfiles..sym.bytesfiles store strings referenced by offset and length from their associated.symfiles
Column files
Deephaven column files are capable of storing persistent data for all supported types.
- Java primitive types and/or their boxed representations are stored directly in the data region of .dat files, one fixed-width value per row.
With the exception of Booleans, column access methods work directly with the unboxed type, the storage used per row is the same as for the Java representation of the type, and distinguished values (see the
QueryConstantsclass) are used to represent null, negative infinity, and positive infinity when appropriate. Generified access methods are included for working with boxed types as a convenience feature.- Boolean - All column methods work directly with the boxed (Boolean) type, for ease of representing nulls. Persistent storage uses 1 byte per row, with values in {-1 (null), 0 (false), 1 (true)}.
- byte (1 byte per row)
- char (2 bytes per row)
- double (8 bytes per row)
- float (4 bytes per row)
- int (4 bytes per row)
- long (8 bytes per row)
- short (2 bytes per row)
DBDateTime- This type encapsulates a nanosecond-resolution UTC timestamp stored in exactly the same manner as a column of longs, using 8 bytes per row in the associated.datfile. See Working with Time for more information on working with this type.DBDateTimesupports dates in the range of 09/25/1677 to 04/11/2262.Symbol- Symbol columns store String data, with an associated lookup table capable of representing 231-1 (approximately 2 billion) unique values. These columns optimize for a small number of unique values. Each row consumes 4 bytes of storage in the .dat file, and each unique non-null value consumes 8 bytes of storage in the.symfile and a variable length record in the.sym.bytesfile.SymbolSet-SymbolSetcolumns allow efficient storage ofStringSetsfrom a universe of up to 64 symbol values. They use the same symbol lookup table format as Symbol columns, and 8 bytes per row in the.datfile.- In addition to the fixed-width types, Deephaven can store columns of any Serializable or Externalizable Java class, including Strings or arrays (of primitives or objects). The BLOBs consume 8 bytes of storage per row in the
.datfile, and a variable length record in the associated.bytesfile.