Group
Data within a table can be grouped based on any similar attribute, or key.
- "I want to group a tradelog by Account.... or by Symbol... or by Account & Symbol."
- "I want to group signals by Factor... or by PM-Group & Factor."
- "I want to group slippage calculations by Sector, Vintage, and Exchange destination."
In Deephaven:
- The
by()method groups data. All fields other than the grouping column will be presented as arrays of the data from the corresponding rows in the source. - The
ungroup()method does the opposite, expanding array elements into individual rows. - The
byExternal()method divides a single table into multiple tables.
Note
See also: Aggregate and ColumnsToRowsTransform
by
The by method groups column content into arrays. If no arguments are defined in the method, the content of each column is grouped into its own array:
sourceTable.by("GroupingKey")
A new table is created containing all the distinct rows defined by the GroupingKey. For each column from the source table not listed in the by method, the new table adds a column with the same name, containing an array with one element for each row that maps to the given distinct grouping row.
Note
See also: Expand Array Data for Row
Example 1
For this example, we'll create a simple table of 4 rows for 2 symbols from data in the StockTrades table:
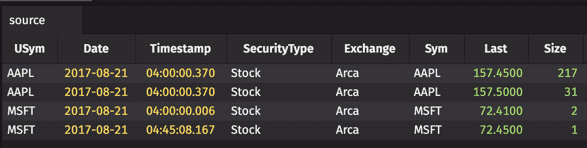
The goal for this example is to create a new table with the same number of columns as the source table, but instead of having four rows of data for each column, the content in the rows for each column will be grouped into an array using the by method with no arguments. The query follows:

Example 2
The goal for this example is to group the content based on the distinct values in the USym. The query follows:
When this query runs, the following table is generated. There are two distinct values in the USym column, so the final table has two rows.

In the source table, there are two rows for each distinct USym, so there are two values in each array.
Example 3 The goal for this example is to group the content based on whether the values in the Size column are even or odd. The query follows:
When this query runs, the following table is generated. A new column titled Parity holds the modulus (remainder) values of 1 or 0.

The values in the other columns are then evaluated for those moduli and then grouped into the corresponding arrays for each column. Therefore, the t3 table has only two rows of data - one for odd values and one for even values.
ungroup
ungroup is the inverse of the by method:
sourceTable.ungroup()
The ungroup method unwraps content from an array and builds a brand new data structure to hold the unwrapped content. There are two forms of ungroup:
- No argument: If no argument is presented, all array columns from the source table will be unwrapped into separate rows. Consequently, all array columns in each row must have the same number of values.
- Explicit array column list: Only columns specified will be unwrapped.
Example 4
The goal for this example is to unwrap all of the arrays for each column. Because we want to unwrap them all, no argument is needed. The query follows:
"t4" should look familiar - the first grouped table ("t1") has been returned to its original state:
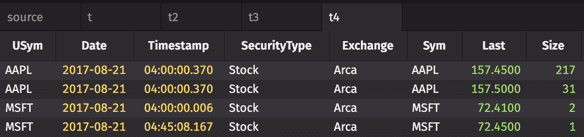
Deephaven unwraps the array elements in the single row table into a table with four rows.
Example 5
The goal for this example is to unwrap one array column while leaving the other array columns intact. The query follows:

byExternal
A TableMap is a collection of Deephaven Tables, each with a key. A TableMap allows you to divide a table into segments within a query and is one of the ways to employ multi-threading. The most common method of creating a TableMap is to use the byExternal method:
sourceTable.byExternal(columnNames)
byExternal divides a single table into multiple tables, which are defined by unique key-value pairs in a TableMap. The keys are determined by the column names used in the argument.
Note
See also: Pipeline and multi-thread your workload
For example, let's start with a table that reduces StockTrades to four columns and 40 rows:
For each distinct value in the USym column, there are 10 rows of data.
The byExternal method can be used to create five different tables based on the five unique key-value pairs defined in the TableMap. The query follows:
One table is created for each of the key-value pairs, (i.e., USym-AAPL, USym-GOOG, USym-IBM, and USym-MSFT). Each distinct USym has 10 rows of data, so each table has 10 rows.
In order to display these tables in the console, you need to use the get method as shown below:
This is essentially equivalent to performing individual where filters for each unique value in the USym column, and then saving the results of each to its own variable. However, using the byExternal method is far more efficient and faster because it eliminates the need to repeatedly pass over the data for each of the values of interest.
To see all of the keys created in the TableMap, you would use the TableMap getKeySet() method as shown below. This method returns an array of keys.
You can also create a TableMap using more than one column in the table. In this case, the number of tables created would be based on the number of all possible combinations of key-pairs in the TableMap. For example, let's include the Date and Exchange columns in our query. The StockTrades table holds data for five different dates. Each key-pair for the Date column would be paired with each key-pair for the Exchange column. Note: if we were using all the table data, that would be 50 different tables; however, we've limited the rows in "source2" using the headBy method and filtered to three Exchange values.
The following code would generate tables for each unique combination of values in both the Date and Exchange columns, e.g., ["2017-08-21", "Arca"].
To see each key-pair:
To open a specific resulting table in the multi-column TableMap, you would then use the SmartKey object to define a specific combination, and then use the get method as shown in the examples below: