Select
Deephaven offers several methods for selecting (or deselecting) columns of data in a query. These methods also enable users to eliminate or modify existing columns of data, or create new columns of data.
Deephaven provides basic methods to move or drop columns, as well as methods to calculate new columns and determine which columns from the source table to keep in the resulting table.
These are:
selectviewupdateupdateViewlazyUpdate
Before deciding on which of these methods to employ in your query, you should consider two questions.
1. Do you need to use only some of the columns or all of the columns from the source table?
For example, if your source table has 50 columns of data, but you only need a subset of those columns for your analysis, using the select or view methods will allow you to specifically name the columns you want to keep in the resulting table. The select and view methods also allow you to modify or add new columns to the resulting table.
Once you have your initial column set pared down, you may want to modify a column or add more columns to the resulting table. This is when the update, updateView, and lazyUpdate methods come into play. When using one of these three selection methods, all of the columns from the source table are automatically included in the resulting table.
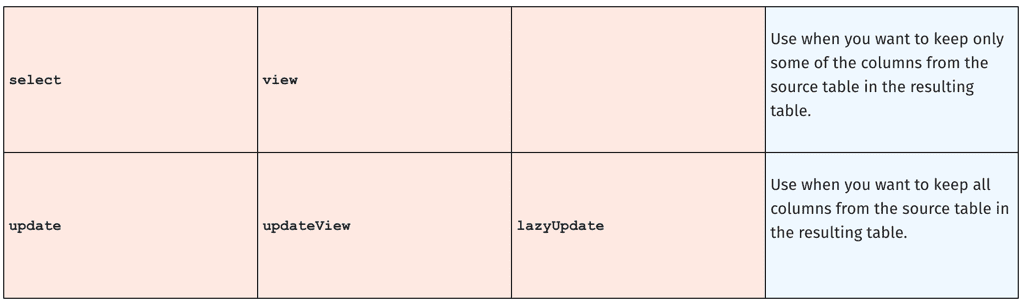
We now have two methods that enable us to keep only some of the columns in a table, and three methods that enable us to include all columns of data in a table.
Now we need to consider the second question:
2. Will the analyses run faster by storing all of the information in memory, or will it be more efficient to dynamically compute cell values as they are needed?
When using data from large datasets, the method in which you access and store that data can have a big impact on efficiency and speed.
When select and update are used in a query, Deephaven will access and evaluate the data requested and then store it in memory. Storing the data is more efficient when the content is expensive to evaluate and/or when the data is accessed multiple times. However, keep in mind that storing large datasets requires a large amount of memory.
When using select, the entire dataset requested is stored in memory. When using update, only the "updated" portion of the dataset is stored in memory.
With view and updateView, the data being requested is not stored in memory. Rather, Deephaven stores a formula that recalculates each value as it is needed. These values are calculated as needed and never saved. Therefore, when the formula is fast to compute or if you are only accessing a small portion of the data, storing the results as a formula is often the best option. Memory is not allocated to store new columns, so less memory is needed.
The lazyUpdate method computes column formulas on demand and will defer computation until it is required. Because it caches the results for the set of input values, the same value will never be computed twice. For small sets of unique values, this uses less memory than an update, and requires less computation than an updateView. However, if you have many unique values, an update will be more efficient because the lazyUpdate stores the formula inputs and result in a map, whereas the update stores the values more compactly in an array.
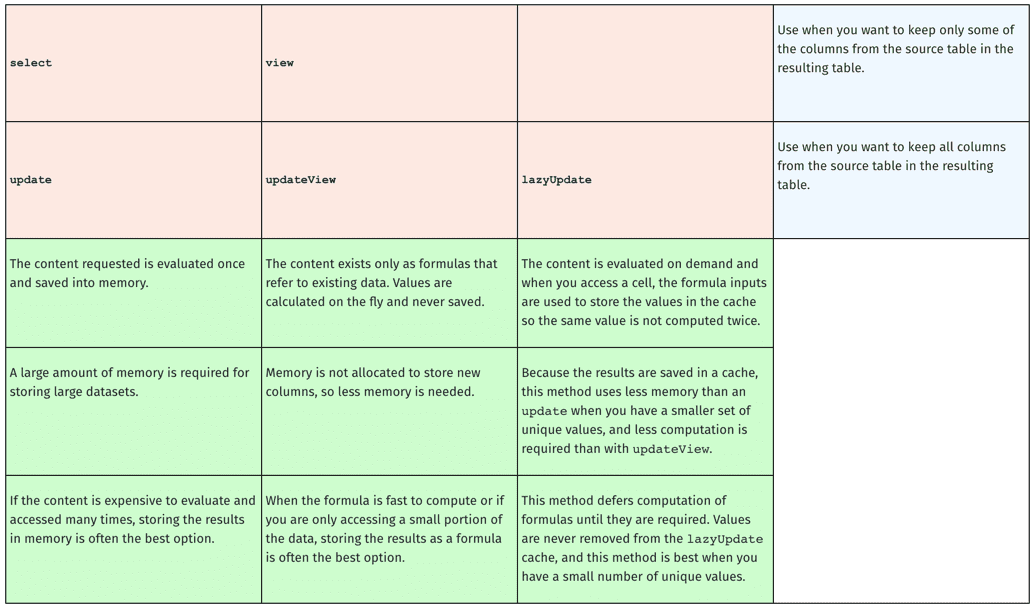
Choosing one pair of methods over the other is not a trivial decision. Depending on the nature of the analysis and the amount of memory you have at your disposal, one method is usually more efficient than the other.
As a general rule of thumb, you should start with view and updateView, and then switch to select, update, and lazyUpdate to see if it is more efficient.
The sections below detail how to use each of these methods in a query, using the following source tables:
select and view
The select and view methods create a new table that includes one column for each argument used in the query. Each argument can be the name of an existing column, or a formula to define an existing column or create a new column. If you do not specify a column from the source table in the argument, it will not be copied to the resulting table.
Note: The select method is being used in the following example, but the syntax is identical to that when using the view method. There is only one difference between the select and view methods. Data obtained by using the select method is saved into memory; data obtained by using the view method is referenced via a formula and is not saved in memory.
Example
The first three arguments indicate that table "t1" should include the Timestamp, Exchange and USym columns from the source table, with no change. The third argument, "Cost=Last*Size", indicates that a new column should be created in "t1" that includes the result from the specified calculation.
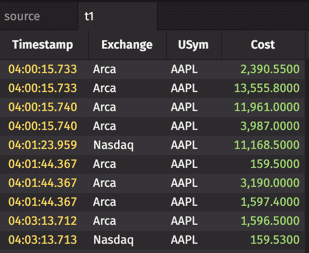
As is demonstrated in the resulting table above, the select and the view methods enable you to:
- Choose the specific columns you want to show in the new table.
- Manipulate the data you are showing in the new table, or
- Omit columns that you do not need for your analysis.
- Create new virtual columns in the resulting table.
update, updateView, and lazyUpdate
The update, updateView, and lazyUpdate methods create one table with the same number of rows as the source table. All of the columns in the source table are included in the new table. However, the contents of those columns in the resulting table can be manipulated through arguments in the query and additional columns can be added.
The primary difference among these methods is how data is stored:
- Data obtained by using the
updatemethod is saved into memory; - Data obtained by using the
updateViewmethod is referenced via a formula and is not saved in memory; - When you access a cell, data computed by using the
lazyUpdatemethod is stored in a cache.
Note: The update method is being used in the following example, but the syntax and the resulting data is identical to that when using the updateView or lazyUpdate method.
Example
Starting with the StockQuotes table, we will write a query to create another table that will "update" certain data in the source table for further analysis.

The update and updateView methods enable you to:
- Include all of the columns from the source table in the resulting table without having to include arguments for each.
- Manipulate column values in the resulting table.
- Create new virtual columns in the resulting table.
selectDistinct
The selectDistinct method creates a new table with only the columns from the source table that are listed in the argument. The number of rows in the new table's column is determined by the number of distinct values contained in these columns.
Example
There are 10 distinct USyms in the source table, so the new table only has 10 rows:

This example showed the distinct values in only one column. However, the selectDistinct method can also be used to determine distinct value sets across multiple columns.
Using the same table as before, we will adjust the query to include two columns in the argument:
This query produces a table with 90 rows: 9 distinct exchange values for each of the 10 USym values.
dropColumns
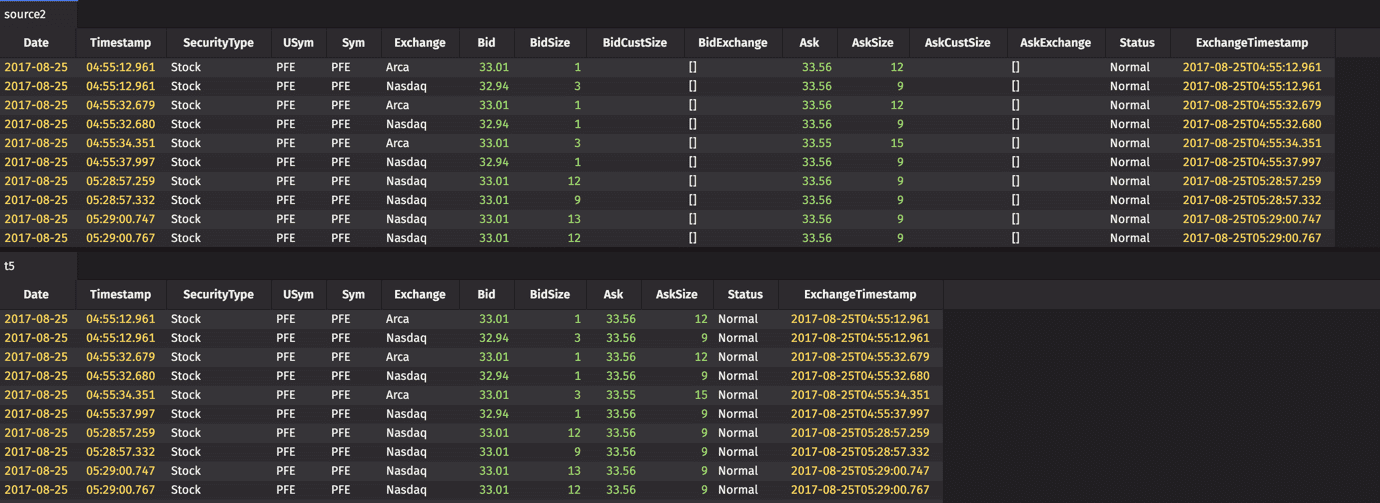
The dropColumns method creates a table with the same number of rows as the source table, but omits any columns included in the dropColumns argument. This method is useful when you only want to eliminate a small number of columns from the source table, or, in cases where you need to add a column for some operation, but then no longer need it after the operation is complete.
Example
The arguments in the query above are the column names that will be dropped from the table, as shown below:
moveColumns
The moveColumns method creates a new table with a specified column (or a set of columns) from the source table moved to a different location. This is accomplished by assigning the column or column set to a specific column index value in the moveColumns argument.
Example
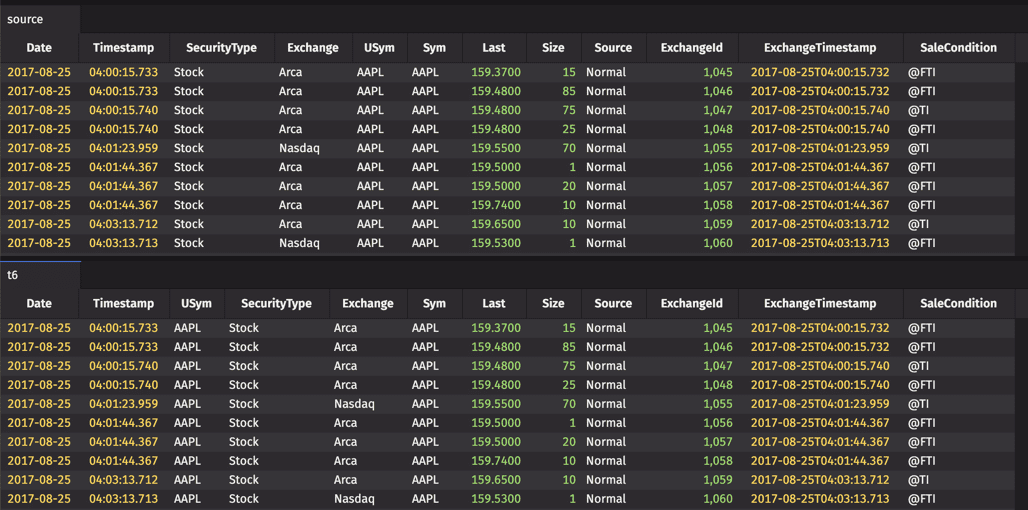
The argument (2,"USym") indicates that the USym column should be moved to column index number 2 in the resulting table.
Note
Deephaven uses a zero-based index model, so column index number 2 would be the third column.
Column sets can also be moved using the moveColumns method:
moveUpColumns
The moveUpColumns method moves a column (or a set of columns) to the first column index position in the resulting table. Unlike the moveColumns method, the argument for the moveUpColumns method does not require the column index number.
Example
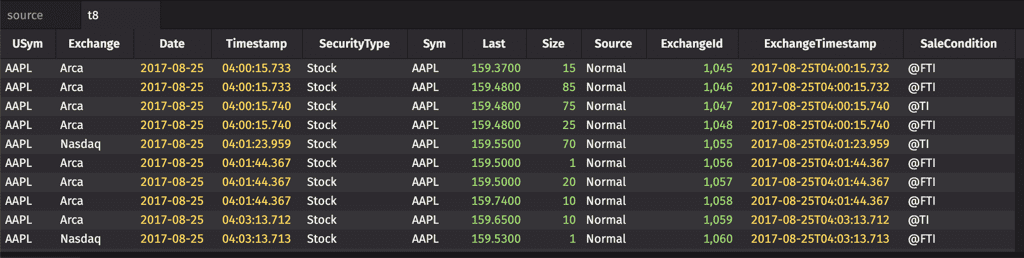
moveDownColumns
The moveDownColumns method moves a column (or a set of columns) to the right side in the resulting table.
Example
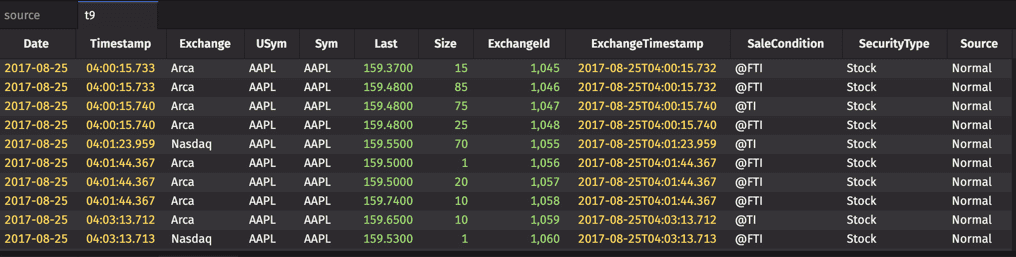
renameColumns
The renameColumns method renames a specified column or columns.
Example
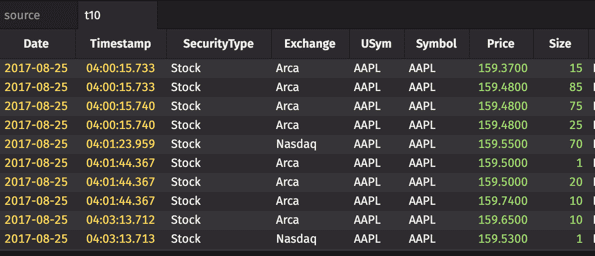
Keyed Row Selection
Keyed Row Selection instructs the Deephaven UI to stay on a selected row or set or rows. When new data is received in ticking tables, the selection is maintained as rows are moved around. For example, this feature is particularly important for custom widgets that need to act on a selected row (e.g., submit an order or cancel an order based on the selection at the time the selection was made, rather than responding to whatever is selected by the time the action fires).
To use Keyed Row Selection, a query must indicate key column values to uniquely identify rows in the table. This is done with the withKeys method:
withKeys(colName)- sets the table's key columnswithUniqueKeys(colName)- sets the table's key columns and indicates that each key set will be unique
Examples The following query maintains your selection on a particular Exchange value:
The next example sets the Timestamp column as the key column in the ProcessEventLog, a ticking table:
The user's selection is maintained, and will stay selected even when the block of rows moves out of view.