Easy TensorFlow predictions using GPUs
Classifications using local GPU power with deephaven.learn
August 11 2022


The release of pip-installed Deephaven is a game changer for data scientists. This new way of connecting to a Deephaven server allows you to build and develop your projects locally in a Docker-less environment. Besides that, deephaven.learn can now harness the power of your GPU. To show this off, I've created an example using the learn package in conjunction with TensorFlow and my GPU.
The example project uses a simple neural network to recognize three different classes in the Iris-flower data set. We'll see how this computation can be performed on your GPU.
The deephaven.learn package lets you access local GPU computation power, unlocking even more tools for your data science projects.
Prerequisites
Before following along with my sample code, go through the setup steps below.
1. GPU set up for WSL in Windows
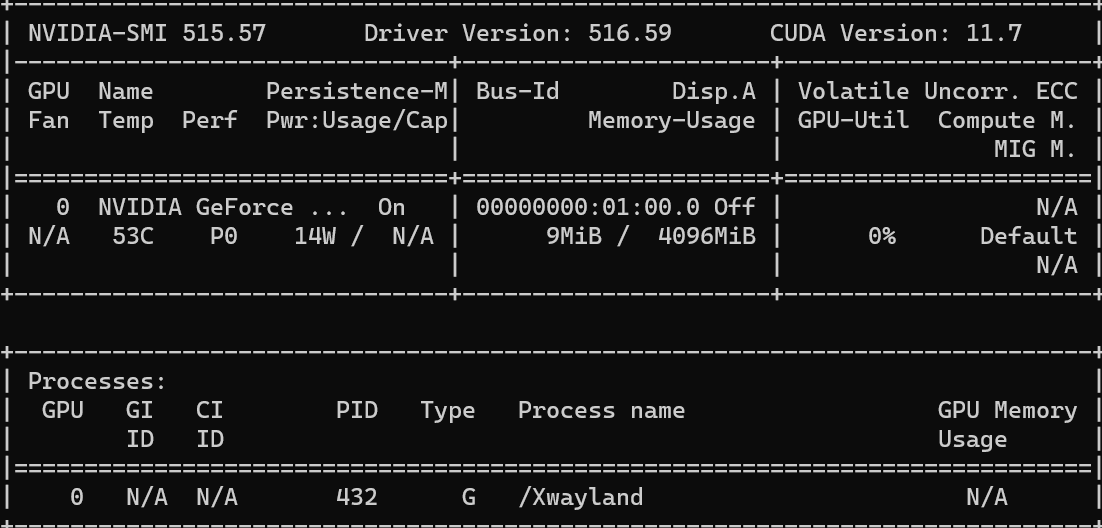
Follow the steps here to enable GPU accessibility in WSL. To check if the GPU is set up properly on your local machine, run:
For my computer, GeForce 3050 is my default GPU. We can see that the GPU usage is 0% at this point.
2. Deephaven Python package
This is all it takes to install Deephaven:
Deep learning example
With that out of the way, I'll walk you through some of my data science workflows, such as deep learning projects using the deephaven.learn package, with GPU computation power.
We first import the packages, and build the server on port 10000, which allows us to access the Deephaven IDE there later:
We can run this code to check if the GPU is accessible by TensorFlow:
If the GPU on your local machine is compatible with TensorFlow, it will print out Name: /physical_device:GPU:0 Type: GPU
Here we use the Iris data set, a very common data science data set for illustration. I did some data pre-processing to assign numeric classes to each flower category:
Here is the deep learning model I built for classification. More complex neural networks would require more GPU computational power, which you can see from the later picture. We also follow the typical modeling procedures to define optimizer, loss function and evaluation metrics in the train_model function.
These functions are to make sure that the input and output values are the correct data types:
After all functions and values get defined, we simply call learn.learn for the first time to train the model, then we call it again to output the table with predicted values.
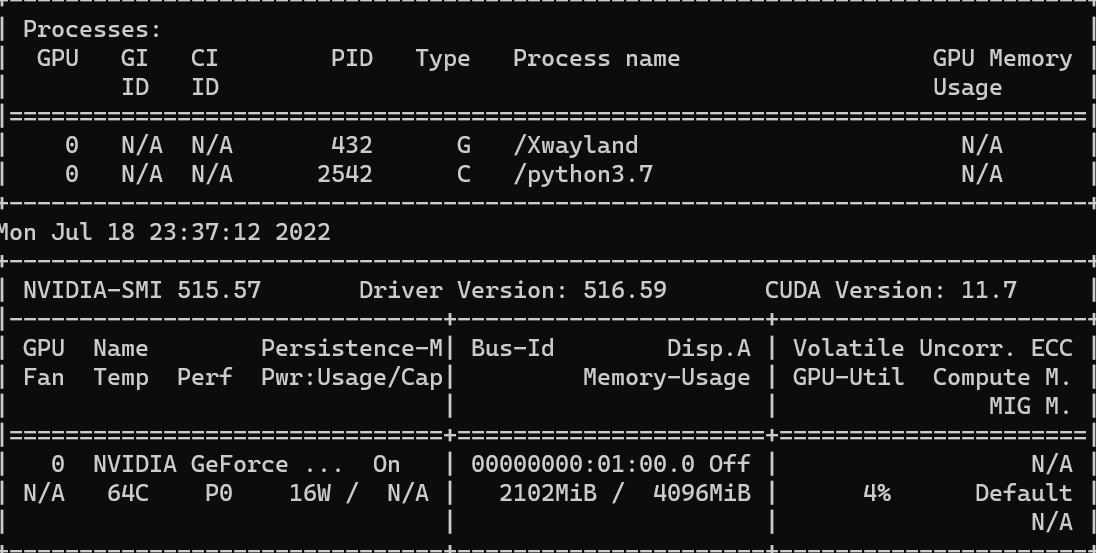
Now we see that the GPU usage goes up to 4%.
Navigate to http://localhost:10000/ide to access Deephaven IDE and you will see the iris_predicted_static table is already there.
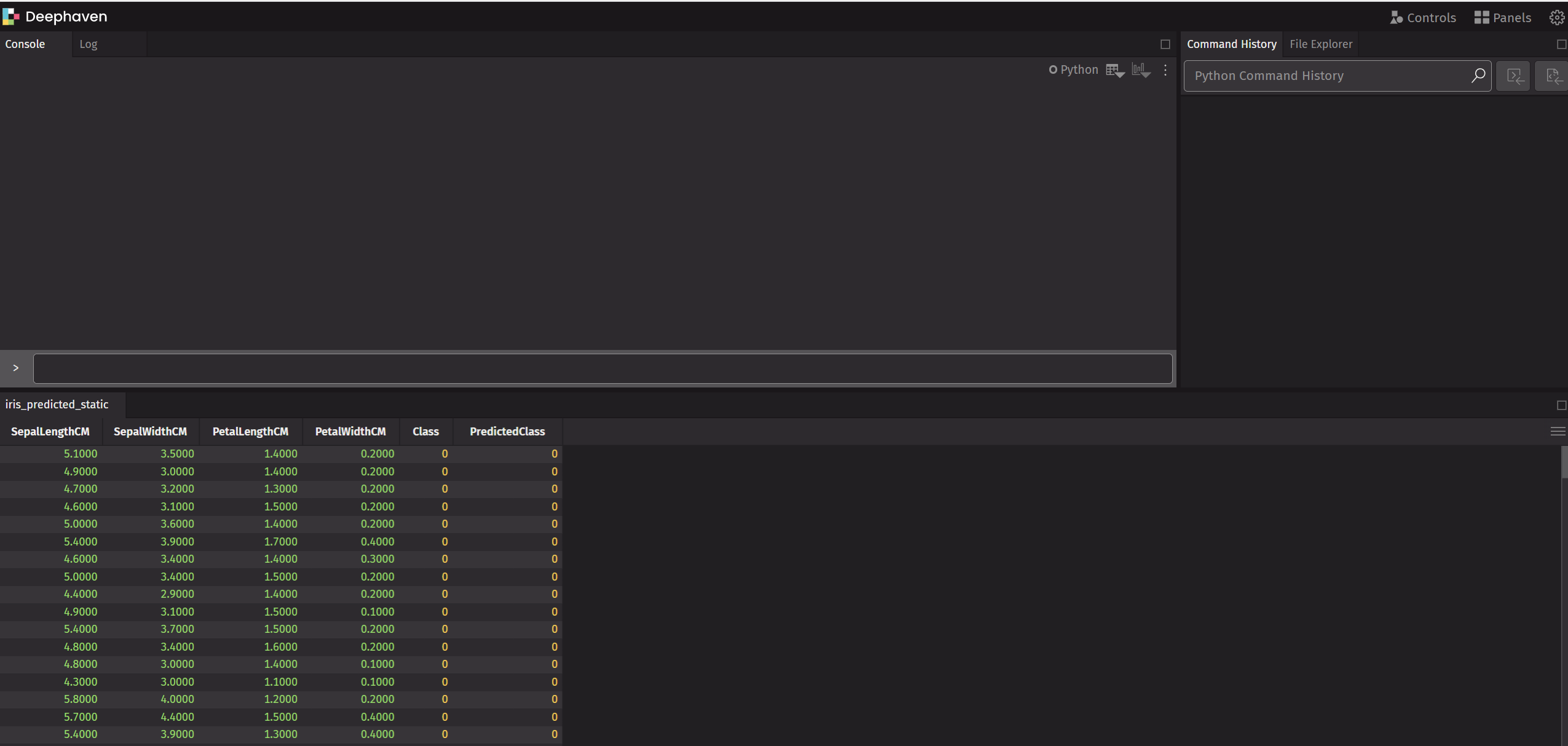
Isn't this cool? Think about how we can do it interactively. I prefer to do code editing on VS code, then after the script is executed, analyze and plot the results in the Deephaven IDE since it provides a better UI. What about you?
Try it out
Feel free to start your own project by using Deephaven as a Python library, and contact us on Slack if you have any questions or feedback.