Use deephaven.learn for AI/ML applications
This guide will show you how to perform calculations in Python with Deephaven tables through the deephaven.learn submodule.
deephaven.learn allows you to perform gather-scatter operations on Deephaven tables. During the gather operation, data from specified columns and rows of a table is gathered into input objects. Then, calculations are performed on the input objects. Finally, the results of calculations are scattered into new columns in an output table.
The deephaven.learn methods are agnostic to the Python object types or libraries used to perform calculations. Thus, functioning Python code that does not use Deephaven tables can easily be extended to work with deephaven.learn. Additionally, because deephaven.learn is agnostic to the libraries used to perform calculations, libraries using specialized hardware, such as GPUs, TPUs, or FPGAs, will work without additional modification.
For Artificial Intelligence / Machine Learning (AI/ML) applications, data is gathered into tensors. Calculations then either (1) optimize the AI/ML model using the input tensors, or (2) generate predictions from the model using the input tensors. Predicted and other output values are then scattered into columns of the output table.
The deephaven.learn gather-scatter operations work on both static and dynamic real-time tables. For static tables, the rows of the table are separated into batches. These batches are processed in sequence. For real-time tables, only the rows of the table that changed during the most recent update cycle are separated into batches and processed. Because of this, AI/ML predictions are only computed on input data that has changed, minimizing how much computational power is needed to predict streaming data.
The gather-compute-scatter paradigm
Deephaven's learn package has been built with a gather-compute-scatter paradigm in mind. These are the building blocks:
- Gather data from Deephaven tables into the appropriate Python object.
- Compute solutions using the gathered data.
- Scatter the solutions back into a Deephaven table.
The learn package coordinates how user-defined models operate on data in Deephaven tables.
Usage and syntax
Data science libraries typically interact with input and output data stored in Python objects. These objects include (but are not limited to):
- Lists
- NumPy ndarrays
- pandas DataFrames
- Torch Tensors
- TensorFlow Tensors
Data scientists and AI engineers spend a lot of their time transforming and cleaning data. Relatively little time is spent doing the fun analytical work. Deephaven queries make these data manipulation tasks easier, while Deephaven's learn function allows user-defined models to generate static or real-time predictions without needing to change code.
A learn function call looks like this:
Each of the five function inputs is described below. The ordering of sections follows the usual process for construting a solution to a data science/AI problem:
- Define the model that will calculate solutions from the input data (compute).
- Determine how input data is best represented for your chosen model (gather).
- Determine what the output of the model will look like (scatter).
Compute
An AI scientist should have a basic understanding of the problem at hand when constructing a solution. There are many factors to consider when choosing a model that will be used. Some basic questions that must be answered are:
- Do I need a supervised or unsupervised model?
- What are the pros and cons of certain models for the problem at hand?
- What kind of computing constraints do I have?
Regardless of what model is chosen for a problem, it must be implemented in a function in Deephaven.
Implement a model
In this step, we apply calculations to some input data. Those calculations can train, test, or validate a chosen model. The model will be implemented in a function.
Every detail and parameter of a chosen model does not need to be determined at this point. However, the following should be known:
- The number of input values the model needs to work.
- The overarching class of model to implement.
- The computational constraints on the model.
- How many output values the model will generate.
In a typical AI application, a model will be trained, validated, and tested in separate steps. The training will continually update the model until a goal function is maximized or minimized. It likely produces no output. The validation determines whether or not the trained model is sufficiently accurate when used on the training data. Lastly, the testing phase is where the trained model is tested against a new data set. If a trained model shows satisfactory results during testing, it will be deployed and used on real-world data.
For a toy example, we will construct a "model" that sums values together. Unlike a real AI model, this needs no training or testing. Regardless, this toy example is used to illustrate basic usage of deephaven.learn.
Values will be summed on a per-row basis. The input values are contained in a variable called features.
Gather
The gather step of learn requires the user to map data from a Deephaven table to a Python object in a way that makes sense in terms of the compute model.
Input table
Real-world applications of AI use data sets that contain information from one or more of a vast array of sources. Sensors, observations, and experimental results cover only a small portion of the data sources that AI models use. In a real application, this data will be contained in a Deephaven table. The static or real-time nature of the data will not affect how learn is used.
For our toy problem, we'll create a static table called source using empty_table and fill it with data using update. source serves as our input table.
Later on, we'll tell learn that source contains the data used as input for our model.
Batch size
Next, we should determine a batch size. The batch size defines the maximum number of samples (rows) propagated through a model during one iteration. The effect of the batch size on the performance of an AI model tends to follow these general rules:
- Smaller batch sizes use less memory.
- Models tend to train faster with smaller batch sizes.
- Larger batch sizes correspond to more accurate gradient estimates during training.
- Larger batch sizes can allow more data to be processed in parallel, resulting in faster calculations.
Be sure to carefully consider these trade-offs if the input table is sufficiently large.
The batch size doesn't mean a model will always use batch_size number of data points. For instance, source contains 100 rows. Specifying a batch size of 40 would mean that three batches get processed: points 1 - 40, points 41 - 80, and points 81-100. Thus, the batch size should be chosen based upon the largest memory footprint that can be handled for a given problem.
In our toy problem, we'll use all rows in source as the batch size.
Inputs and the gather function
Gathering input values into a Python object requires specifying the columns and number of rows in the input table from which the data will be gathered. This data will be mapped from a Deephaven table to a Python object via a gather function.
For our toy problem, we want all of the data from input columns A and B in the source table. Thus, our input takes data from two columns, and maps it to a NumPy ndarray. The resulting ndarray will have the same number of rows and columns as the input table.
Deephaven has a submodule for gathering data called learn.gather. This submodule has a built-in function for gathering table data into a two-dimensional ndarray called table_to_numpy_2d.
The function table_to_numpy_2d can take up to four inputs:
rows: A set of rows that will be copied in to thendarray.columns: A set of columns that will be copied into thendarray.order: How the array is stored in memory. Can be either column-major or row-major.- The default value is row-major.
- Specifying the memory layout is done with an enumeration called
gather.MemoryLayout. There are four accepted values:gather.MemoryLayout.ROW_MAJOR: row-major order.gather.MemoryLayout.COLUMN_MAJOR: column-major order.gather.MemoryLayout.C: C memory layout (row-major).gather.MemoryLayout.FORTRAN: Fortran memory layout (column-major).
np_type: The data type of all values in the outputndarray. Any non-NumPy data types will be cast to the corresponding NumPydtype.
In this example, we'll use row-major order. If we were to use column-major order, the resulting NumPy ndarray would still look the same.
These are put together in the learn function call like this:
Note
If you only want to gather one column, gather.table_to_numpy_2d will create a 2-D array with a single column. You can convert this to a 1-D array with np.squeeze.
Scatter
The scatter step of learn occurs after the model has been applied to the input data. The output of the model will be scattered back into a Deephaven table.
Outputs and the scatter function
Scattering computed values back into Deephaven tables requires specifying output columns and defining the way in which the output data is mapped to output table cells via a scatter function.
In our toy example, we have two input columns, and a function that sums the values on a per-row basis. Thus, our output is one single column (called C) containing the result of each summation.
Our scatter function simply takes the summation result at a particular index and returns it so that it can be written to the output table.
We put these together in the learn function call like this:
Specifying double at the end tells learn to cast the output values as doubles in the result table. All of the Java primitive types are supported, and the type is specified as a string input.
Putting it all together
We can combine everything we just covered to make a program that uses learn to sum two columns in one table and return the result in another.
This is overkill for simply adding two columns. This can easily be done with some simple table operations. However, these steps generalize to AI code, where the amount of added complexity is small relative to the problem itself.
Examples
In this section, we integrate the following popular AI packages:
These modules are not a part of the base Deephaven Docker image. Refer to our guide How to install Python packages for an explanation of how to install these modules.
Examples exist in our documentation that cover specific Python modules. Those, on top of what's presented below, serve as a good reference for how to use the Python modules themselves, as well as deephaven.learn. Here is a list of how-to guides for specific packages that cover their use both with and without deephaven.learn:
- How to use PyTorch in Deephaven
- How to use SciKit-Learn in Deephaven
- How to use TensorFlow in Deephaven
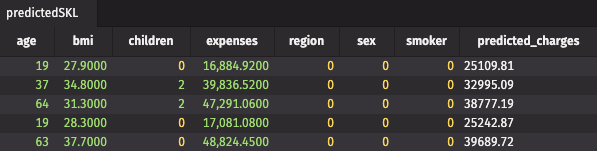
Predict insurance charges using SciKit-Learn and Deephaven
This first example uses a linear regression model from SciKit-Learn. This model will predict insurance charges for customers depending on a few different health factors.
The code uses this insurance dataset, which can be found in Deephaven's Examples repository. If you are using a Deephaven deployment with example data, it is mounted at /data/examples/Insurance/csv within the Deephaven Docker container. For more information on this location, see our guide Access your file system with Docker data volumes.
The example below:
- Reads and quantizes the insurance dataset from a CSV file.
- Constructs a linear regression model.
- Fits the model to the data.
- Defines the scatter and gather functions.
- Uses
learnto apply the fitted model to the data.
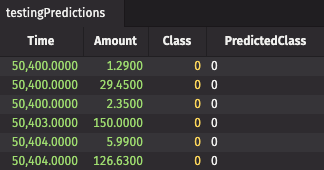
Predict fraudulent credit card charges using a neural network
Our second example uses TensorFlow to predict whether or not credit card purchases are fraudulent based on 28 anonymized purchase metrics.
The code uses this credit card fraud CSV file. It contains 48 hours' worth of credit card purchases by insurance cardholders. Out of 284,807 purchases, 492 are fraudulent. The numerical data describing each purchase is broken into 28 different columns, which are anonymized and PCA transformed. The low rate of fraudulent purchases (0.173%) makes this an outlier detection problem.
The code below:
- Reads the CSV file into memory.
- Splits the tables into training and testing sets.
- Constructs the model.
- Trains the model on the training data.
- Tests the trained model on the testing data.