Real-time windowed and cumulative calculations made easy
Performance and efficiency with expressive syntax
June 22 2023


Each Deephaven Core release brings new features to get excited about. One of this year's biggest and most exciting is the update_by table operation. Its introduction to the table API has transformed what used to be difficult and tedious doable in a single function call.
Efficiently perform windowed or cumulative calculations, compute inter-row statistics, aggregate, and group data all with one function.
What is update_by?
update_by adds new capability for computing inter-row statistics. This enables efficient and expressive cross-row calculations, such as the differences between rows, or an exponential moving average. It can perform two types of operations: cumulative and rolling.
- Cumulative operations are applied to an entire table, such as a cumulative sum.
- Rolling operations are applied to a subset of rows in a table, such as a rolling sum over the previous ten rows or the previous ten seconds.
update_by is highly efficient and will only recompute the absolute minimum amount of data required for each calculation. It retains the current table rows and simply appends the aggregating columns. It's also parallelized - concurrency can be achieved even in Python, which is typically limited by the GIL.
Why is it called update_by?
This operation's name is derived from the combination of two of Deephaven's most commonly used operations - update and agg_by.
- It's like
updatebecause it updates table data, creating new columns with specified calculations. - It's like
agg_bybecause the calculations implemented byupdate_byare done on grouped (aggregated) sets of data. As with other aggregations, they can be done on a per-group basis, or applied to an entire table.
Examples
Examples are more illustrative of capabilities than a long list. So, here are a few that show what update_by can do.
Rolling averages
The following example calculates row-based and time-based rolling averages of a column with numeric data. No grouping columns are given, so the calculations are applied to the whole table. The row-based moving average calculates an average given the previous row, current row, and next row. The same is true for the time-based average, which includes all rows within plus or minus 1.5 seconds from the current row.
EMAs grouped by a symbol
The following example calculates row and time-based EMAs of the same data as the example above. This time around, the Symbol column is given as the grouping column. It contains alternating symbols Tau and Epsilon, so the EMAs are calculated on a per-symbol basis.
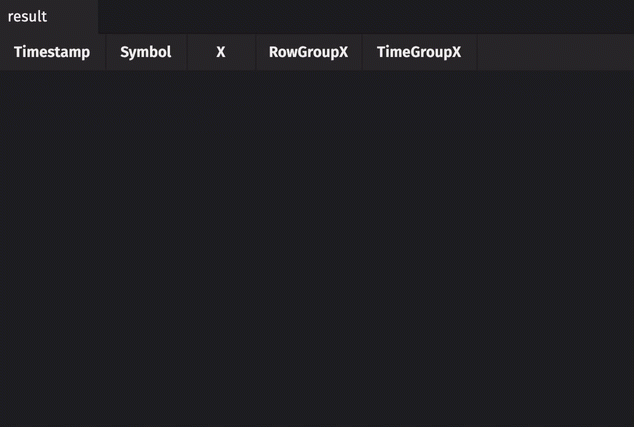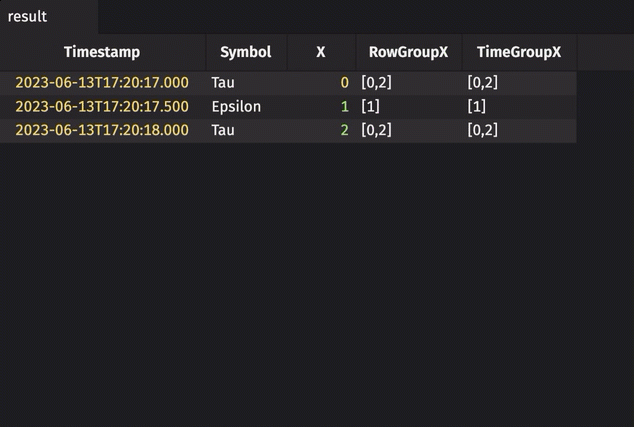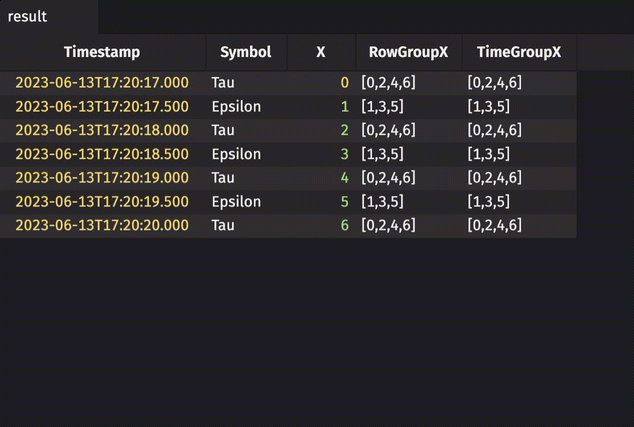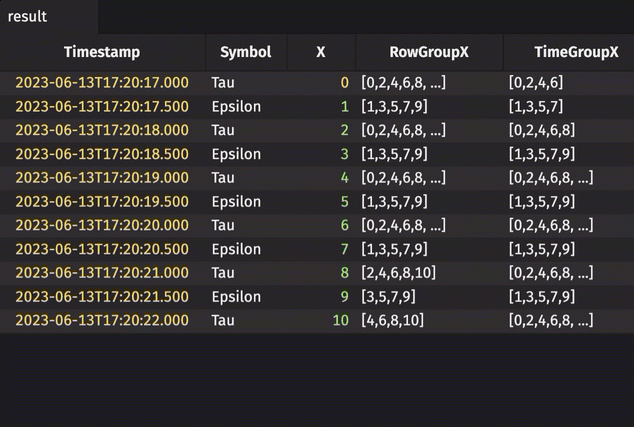
Rolling group in real-time
The following example calculates a rolling group on real-time data.
What calculations can be performed with update_by?
A lot. Here's the full list:
| Operation name | Description |
|---|---|
cum_max | Cumulative maximum |
cum_min | Cumulative minimum |
cum_prod | Cumulative product |
cum_sum | Cumulative Sum |
delta | Difference between adjacent rows |
ema_tick | Row-based EMA |
ema_time | Time-based EMA |
emmax_tick | Row-based exponential moving maximum |
emmax_time | Time-based exponential moving maximum |
emmin_tick | Row-based exponential moving minimum |
emmin_time | Time-based exponential moving mimnimum |
ems_tick | Row-based exponential moving sum |
ems_time | Time-based exponential moving sum |
forward_fill | Forward-fill null values |
rolling_avg_tick | Row-based moving average |
rolling_avg_time | Time-based moving average |
rolling_count_tick | Row-based moving count |
rolling_count_time | Time-based moving count |
rolling_group_tick | Row-based moving group |
rolling_group_time | Time-based moving group |
rolling_std_tick | Row-based moving standard deviation |
rolling_std_time | Time-based moving standard deviation |
rolling_sum_tick | Row-based moving sum |
rolling_sum_time | Time-based moving sum |
rolling_wavg_tick | Row-based moving weighted average |
rolling_wavg_time | Time-based moving weighted average |
Reach out
Have any questions for us? Reach out on Slack!