Ultra fast joins with multi-join
Joining multitudes of tables seamlessly and quickly
September 25 2023


Deephaven's version 0.28 release brought some cool new features and improvements to client libraries. Perhaps the most exciting is the addition of multi_join to the Deephaven table API. With multi_join, you can accomplish what previously took several lines of code in a single line. Not only that, but it's way faster than the old way of chaining joins together.
Multi-join is a new feature that joins three or more tables together. It's faster, much more memory efficient than the only alternative, and works all the same on static and dynamic data.
In this blog, we'll compare performance of using multi_join and its multi-operation analog. The results are impressive.
What is multi_join?
Put simply: multi_join joins tables together. It's the only way to join three or more tables with a single method call. It's also lightning fast regardless of how many tables are being joined. It uses only a single hash table to perform the join, so it's memory efficient as well.
The syntax of multi_join is simple. Consider which tables to join together, as well as the key column(s) to join on. Set both as lists to use in multi_join, and use .table() to get the resultant table.
The result of a multi_join can be duplicated without using the method itself, but it's not as nice. Here, we perform the same operation as the code block above without multi_join:
The code block above replaces multi_join with list iteration, view, select_distinct, and then a series of natural_join operations performed in a loop. Syntactically, it's complicated. But syntax isn't the main driver for the new feature -- performance is. So, let's back up the claims of speed and memory efficiency with some testing.
Static example
Why use multi_join? Because it's fast and memory efficient.
This first example joins together six tables, each containing different statistics for NFL quarterbacks from the 1999 to 2022 NFL seasons (24 seasons). The data is sourced from CSV files created using nfl_data_py. The files contain per-season data for completions, pass attempts, yards, touchdowns, interceptions, and sacks for any player who attempted a pass at least once in a season.
Tip
The Python nfl_data_py package is awesome for getting NFL data into Python. I highly recommend it if you're interested in working with NFL data.
The following code reads each file into a list of tables. One of the tables is separated from the rest to show what the data looks like.
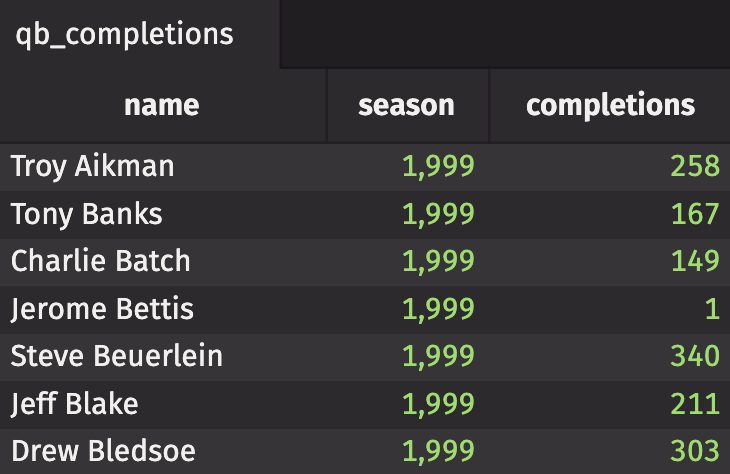
Each table contains the name and season column, but contains a different statistic as the filename suggests. As mentioned previously, the results of a multi_join can be duplicated without using it. Let's see what that looks like, how fast it is, and how much memory it uses.

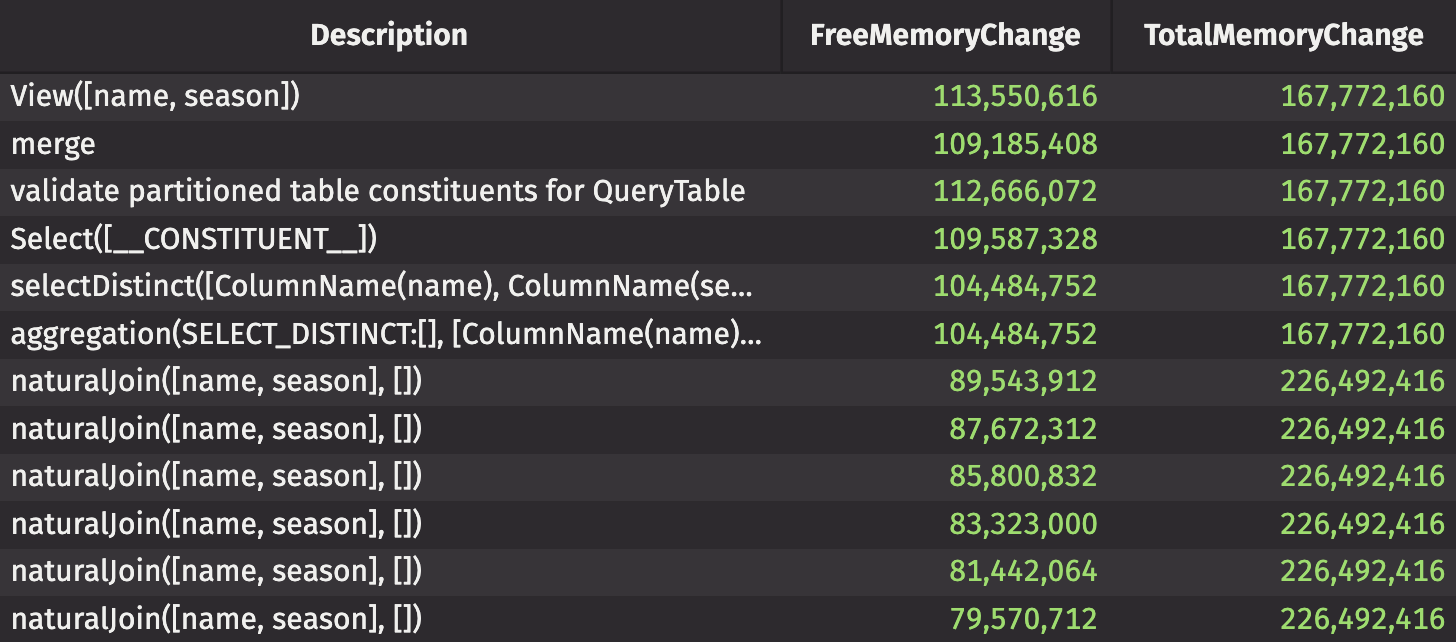
It took 1.6 seconds to join together 6 tables, totaling 2439 rows and 8 columns. Looking at the query operations performance log, we see that the
merge,selectDistinct, and sixnaturalJoinoperations resulted in approximately 15MB of free memory being used.
Let's do the same thing, but this time, with multi_join. The code is not only simpler, but as you'll see, it's faster and uses less memory.

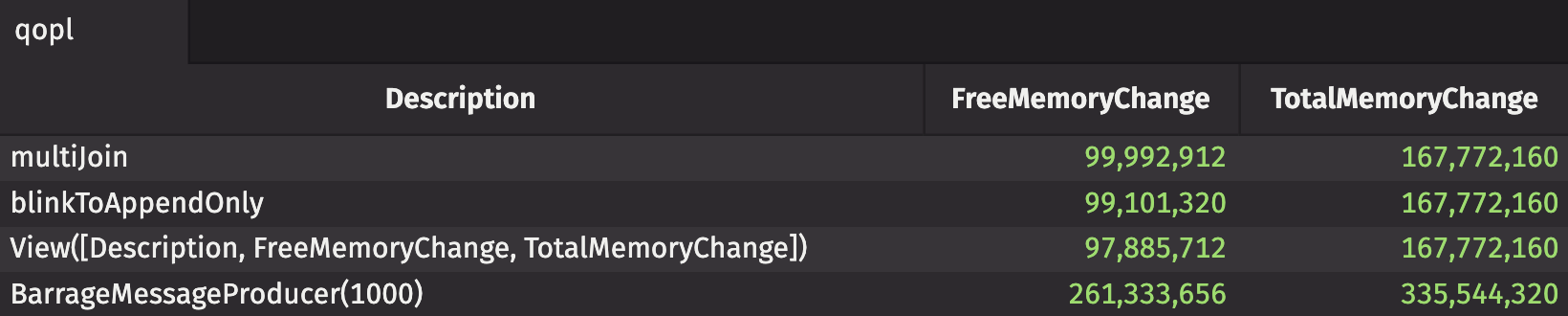
It took 1.46 seconds to join the same 6 tables, which is ~10% faster. Looking at the memory usage, the free memory change is only approximately 900KB. That's over 15x less memory intensive! The speedup isn't substantial in such a small example, but with larger datasets, the difference will be more significant. The memory usage, though, is drastically less.
Real-time example
Note
The example below is only forward-compatible with Deephaven versions 0.30.1 and earlier.
multi_join works all the same on real-time data. The example below joins 10 tables together, each updating with between 10 and 500 new rows per second. That's an average of around 2500 new rows per second being aggregated and multi-joined.
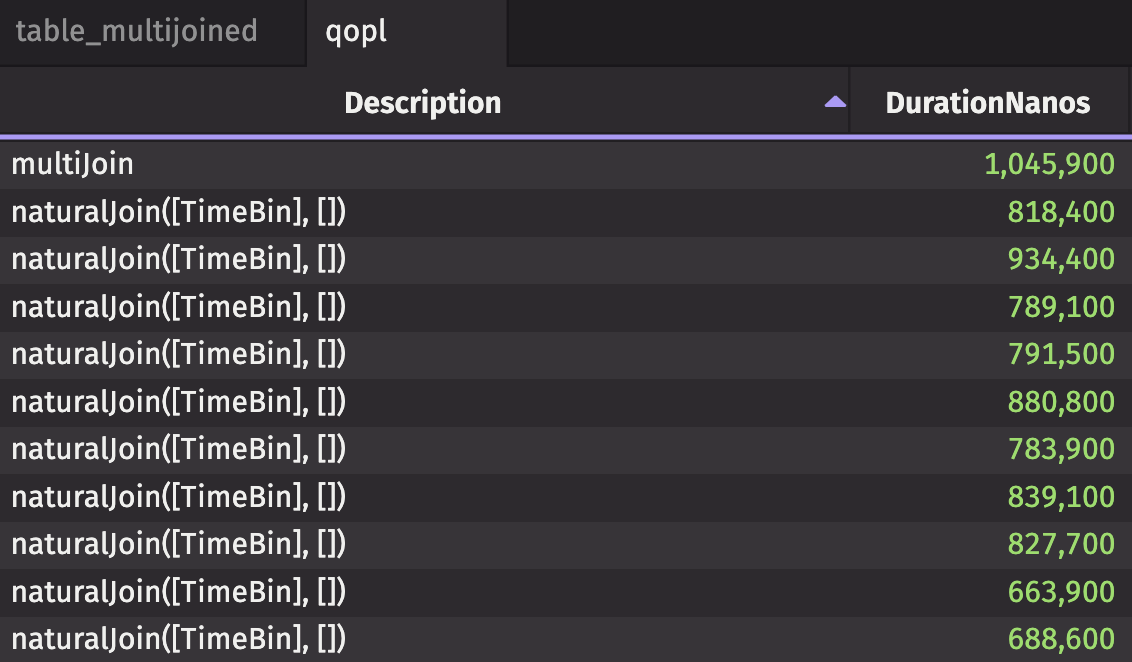
The image above shows the description, CPU duration in nanoseconds, free memory change, and total memory change for multi_join and the ten natural_joins performed to achieve the same result. The multi_join takes only ~1 millisecond of CPU time, while each natural_join takes ~0.8 milliseconds. All in all, multi_join takes about 8x less CPU time. That doesn't even count the CPU time required for merge and select_distinct.
Don't wait around to join all of your data together. Use multi_join to do it fast, and with less memory than you thought you'd need.
Reach out
We hope Deephaven's Community documentation provides guidance and answers your Deephaven questions. We're also active on Slack, where we can answer anything our docs don't. Don't hesitate to reach out!