

“You don’t have to be an engineer to be a racing driver, but you do have to have Mechanical Sympathy.”
– Jackie Stewart, racing driver
This simple quote has deep meaning when it comes to many facets of life. Its value cannot be understated when it comes to software. In this article, we'll touch upon an important concept in Deephaven - partitioned tables. Like with auto racing, having a grasp of the mechanics behind a system will enable you to maximize its potential. So, let's take a closer look at partitioned tables and how they can help you get the most out of Deephaven.
Partitioned tables can help parallelize queries across multiple threads and generally improve performance when used in the right context. They can also make it easier to work with big data in the user interface.
What is a partitioned table?
A partitioned table is divided into smaller parts called constituent tables (or subtables). These parts are grouped based on the values of certain columns, called key columns. The values in these key columns decide which constituent table each row belongs to.
A partitioned table can be thought of in two ways:
- A vertically stacked list of tables. This list can be combined into a single table with
merge. - A map of tables. A constituent table can be retrieved by its key values with
get_constituent.
A partitioned table can be created in two ways:
- By partitioning a source table.
- Directly from a Kafka stream.
This article is focused on why partitioned tables are a powerful tool, so it will only discuss partitioning source tables. For more information on consuming Kafka streams directly into a partitioned table, see consume_to_partitioned_table.
Partitioned tables in action
Let's look at some basic examples of creating and using partitioned tables.
Partition a table into constituent tables
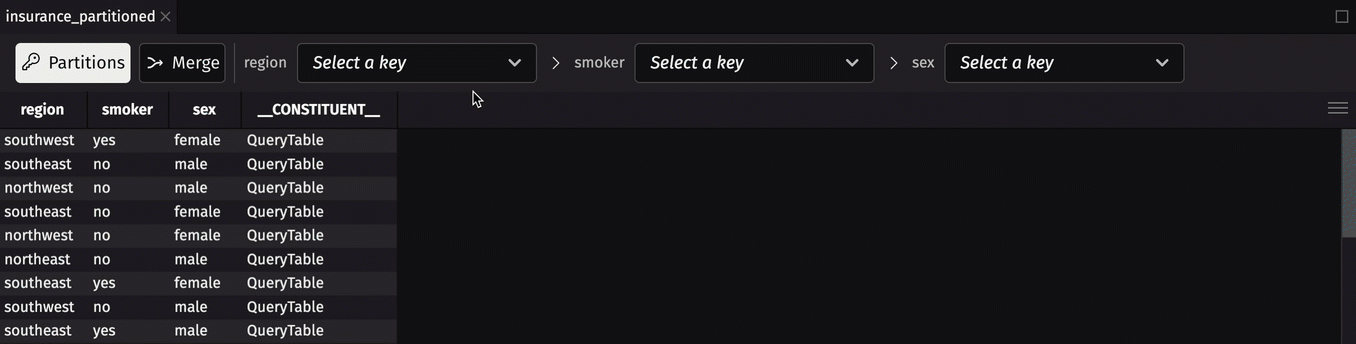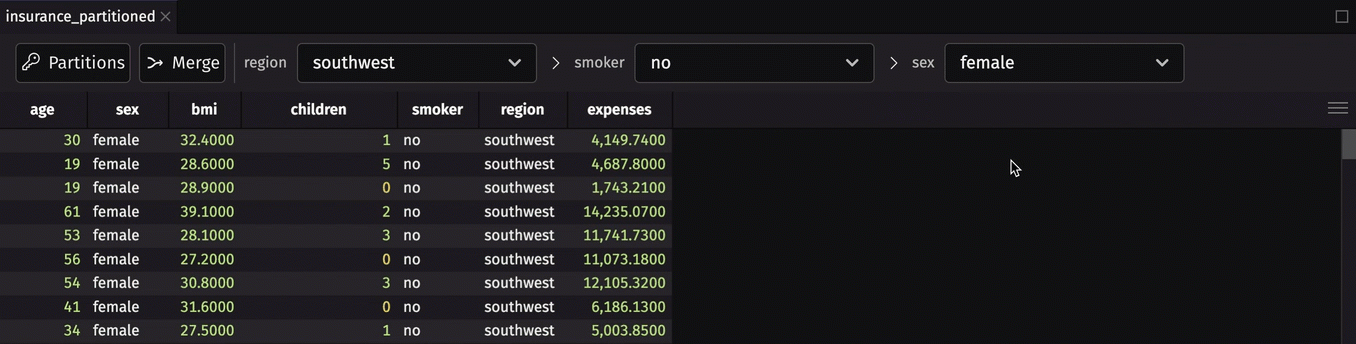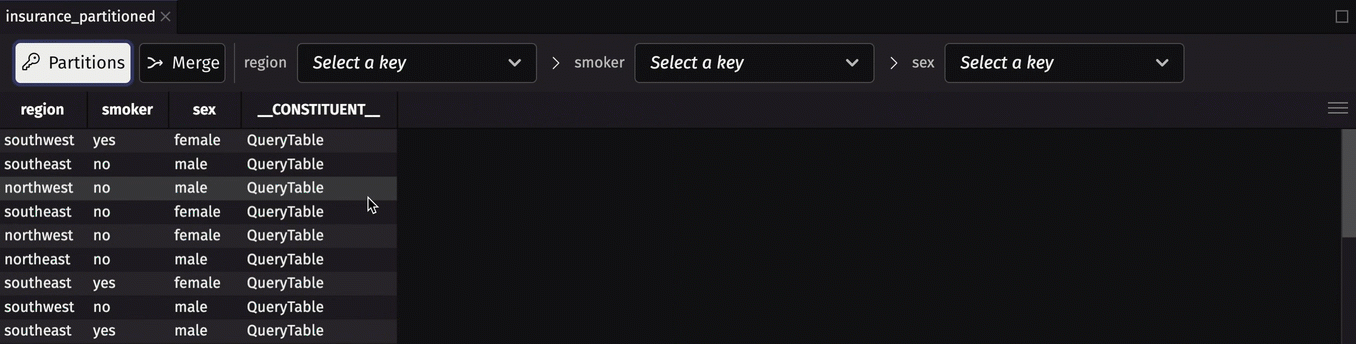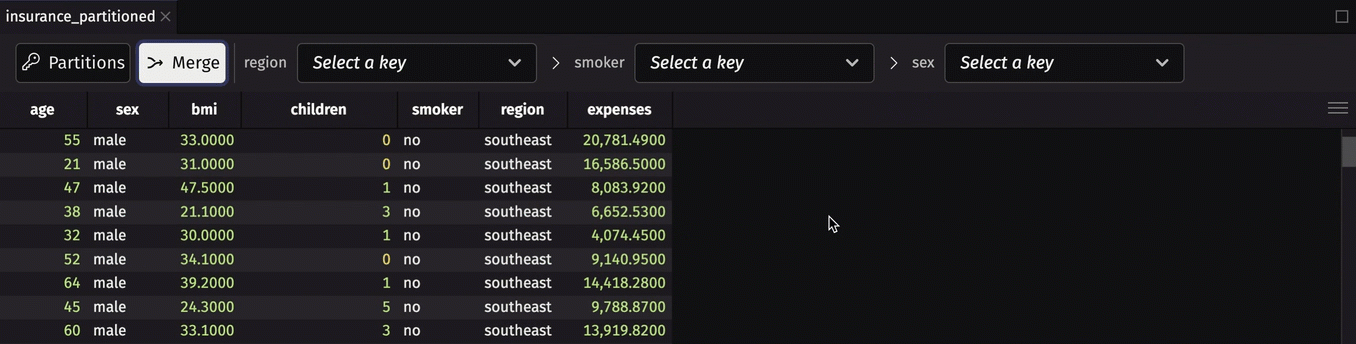
The following code reads a CSV file of insurance data into Deephaven. It then partitions the table by the region column and gets a table containing each partitioned table keys.
Tables can be partitioned by an arbitrary number of key columns. Consider the following code, which instead partitions the insurance table by 3 key columns: region, smoker, and sex.
Get constituent tables from a partitioned table
To get individual constituent tables from a partitioned table, you need to specify which constituent you want by using the unique key values. The following code gets the constituent for non-smoking women in the Northwest.
To learn more about partitioned tables, head over to our user guide.
Why use partitioned tables?
Why? is the most important question when considering whether partitioned tables are right for your queries. Let's examine the convenience and performance benefits they provide.
Convenience
A partitioned table can be used like a map to retrieve constituent tables via their keys. Deephaven's user interface has a built-in partitioned table viewer that allows you to:
- View the keys of a partitioned table.
- View constituent tables.
- Merge the partitioned table.
Speaking of user interface, deephaven.ui is a powerful tool for creating custom user interfaces. Combining it with partitioned tables enables you to do things like switch between constituents with a single click. Consider the following code, which uses a dropdown menu to choose which partition to plot.
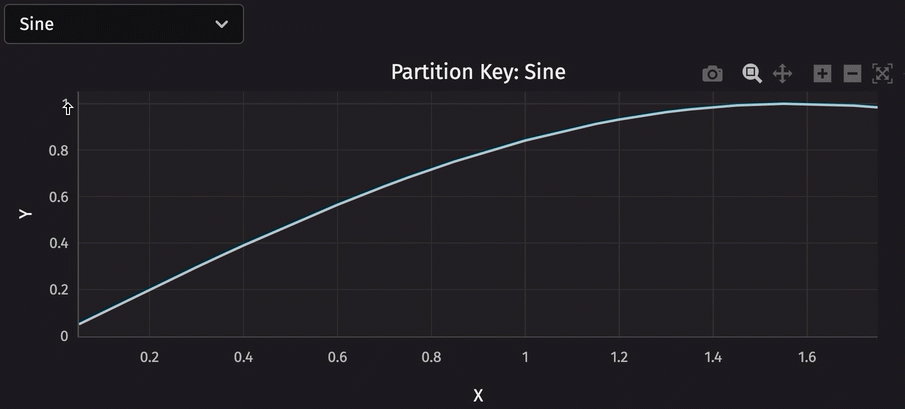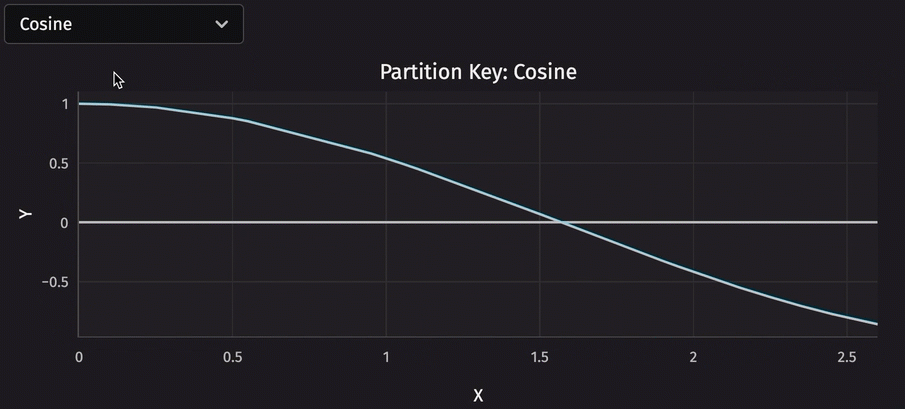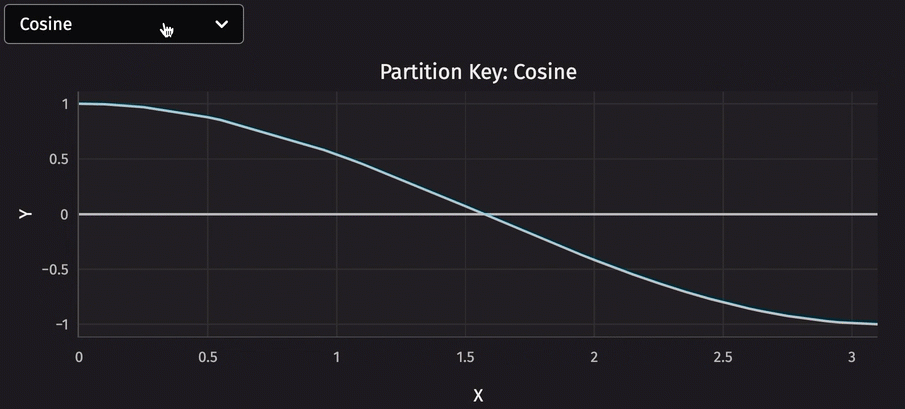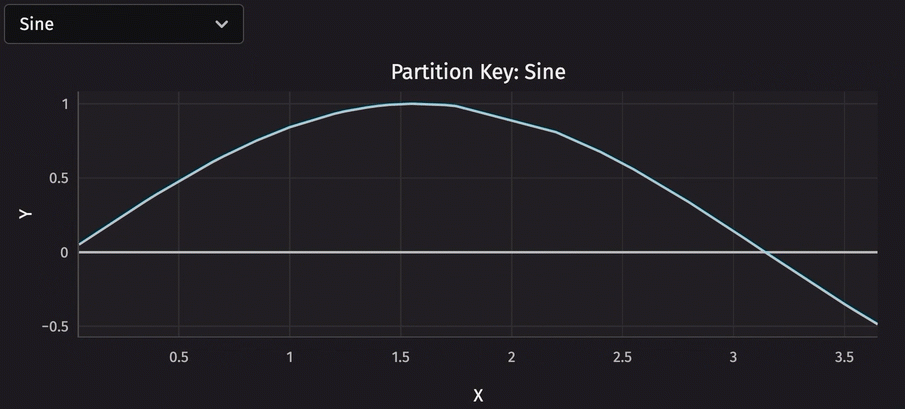
Performance
Important
Partitioned tables are not a one-size-fits-all solution. They will not always make queries faster. It's important to understand when and how to use them to get the most out of Deephaven.
Partitioned tables can make queries faster in a couple of different ways.
Parallelization
Partitioned tables can improve query performance by parallelizing operations that standard tables cannot. Take, for example, an as-of join between two tables. If the tables are partitioned by the exact match columns of the join, the join operation is done in parallel.
Partitioned tables are powerful but aren't a magic wand that improves performance in all cases. Parallelization is best employed when:
- Shared resources between concurrent tasks are minimal.
- Partitioned data is dense.
- Data is sufficiently large.
It's also worth noting that Python's Global Interpreter Lock (GIL) prevents threads from running concurrently. Maximizing partitioned table query parallelization requires minimizing the amount of unnecessary Python code invoked.
Let's look at this parallelization in action. I just made the claim that the join operation in an as-of join is done in parallel if two tables are partitioned by the exact match columns. The following code creates two fake tables of 5 million rows each that contain quote and trade data for seven different "symbols" on four different "exchanges". It then partitions them on the exact match columns and compares the performance between the standard tables and the partitioned tables:
Performance improvements will generally scale with:
- Size and density of data
- Hardware resources (number of CPU cores especially)
- Number of partitions
Tick amplification
Tick amplification happens when cell values are grouped and ungrouped. If any cell contributing to a grouped array changes, the entire grouped array is marked as changed. As a result, a single small change in an input table can result in large sections of an ungrouped output table changing. This can spiral out of control in real-time queries when data is sufficiently large.
The following query demonstrates tick amplification using a table listener. It:
- Creates a time table that ticks once every 5 seconds (
t1). - Groups, updates, then ungroups the table (
t2). - Partitions, updates, then merges the table (
t3).
The number of added and modified rows is recorded on each tick. This value is printed for each of the above three operations to show how many rows are modified or added each time t1 ticks.
The first time t1 ticks, this gets printed:
So far, no issues. But, that's because t1 has only ticked once. After a little while, here's the output:
As t1 grows, the grouping and ungrouping operation continues to make more and more changes, whereas the partition/merge only makes one.
When the data is grouped, the engine cannot know that only one cell in a grouped array has changed, and it must recalculate the entire group. However, when the data is partitioned, only a single row in a single partition changes.
In summary
Partitioned tables are a powerful tool to help you get the most out of Deephaven. If used correctly, they can boost performance and convenience in queries, particularly ones on big data. Consider partitioned tables for your applications if:
- Your data is dense.
- You need to parallelize queries across multiple threads.
- You have user interfaces that frequently request subtables by one or more key columns.
Reach out
Our Slack community continues to grow! It's a great place to learn if partitioned tables are right for your Deephaven applications. Reach out to us with any questions, comments, or feedback. We'd love to hear from you!