Detect credit card fraud with Deephaven
Performing real-time outlier detection to identify fraudulent credit card purchases using DBSCAN and Deephaven
November 17 2021


Credit card fraud causes billions of dollars in damages each year. The most infamous cases have affected tens to hundreds of millions of consumers in single attacks through the unlawful exposure of personally identifiable information (PII) related to credit cards. Isolated cases are also common, and can be caused by a variety of methods including skimming, social engineering, and application fraud.
In order to protect their customers, credit card companies rely on fraud detection and prevention software to analyze credit card purchases. These programs look for unusual or unexpected patterns to classify them as possibly fraudulent. In this blog, we propose our own real-time credit card fraud detection solution using Python with Deephaven.
The code in this blog uses SciKit-Learn, which does not come with Deephaven's base images. To run this code, ensure you have the module installed. Here's how you can Install and use Python packages. We also have a guide for How to use SciKit-Learn in Deephaven.
The data set
We use the credit card fraud dataset that is publicly available on Kaggle and in Deephaven's Examples repository.
The data set consists of 284,807 credit card purchases over the course of 48 hours by European cardholders. Only 492 of these purchases are fraudulent, making this data set heavily imbalanced by the valid purchases. Due to the sensitive nature of the data, the purchase metrics, which consist of 28 variables (named V1 through V28), have been transformed and anonymized so that there is no identifiable information contained within them.
Let's assume the following basic points:
- Fraudulent purchases are spatial outliers among their valid counterparts.
- Not all purchase metrics will help us obtain a good solution.
- Incorrectly classifying a valid purchase as fraudulent is better than incorrectly classifying a fraudulent purchase as valid.
The first assumption is somewhat naive, but can produce adequate results with proper preparation and data exploration.
Data exploration
We first have to import the data into memory.
Before we try to rid the world of credit card fraud, let's explore the data. We've decided to approach the problem with the idea that fraudulent purchases can be considered spatial outliers in the data. We can use Deephaven's plotting capabilities to check our assumption. A histogram plot can show us how similar or different valid and fraudulent purchases are for any given purchase metric.
The code below defines a function that will create a histogram plot that shows how the distribution of points differs between valid and fraudulent purchases for any of the anonymized purchase metrics in the table.
There are 28 columns of data to explore, so we won't show all of them here. Histogram plots of columns V4, V12, and V14 show significant differences in how valid and fraudulent purchases are distributed along those spaces. Thus, we will use these three columns for our analysis.
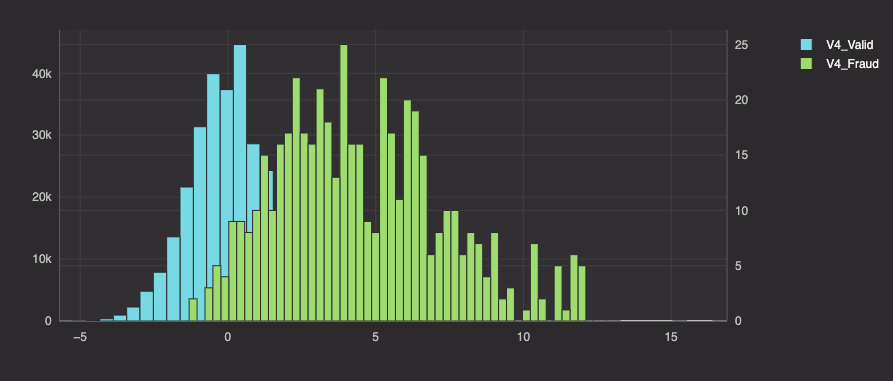
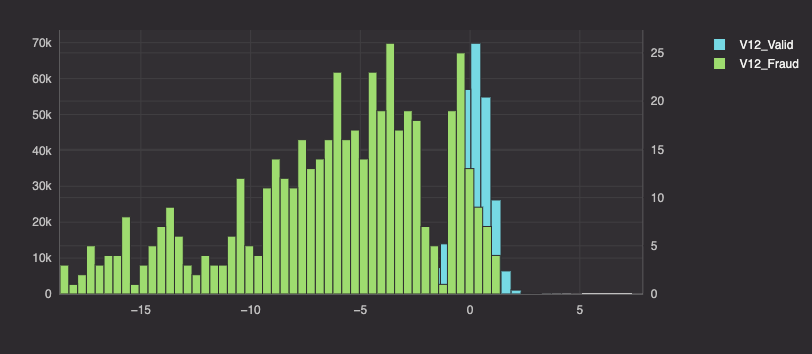
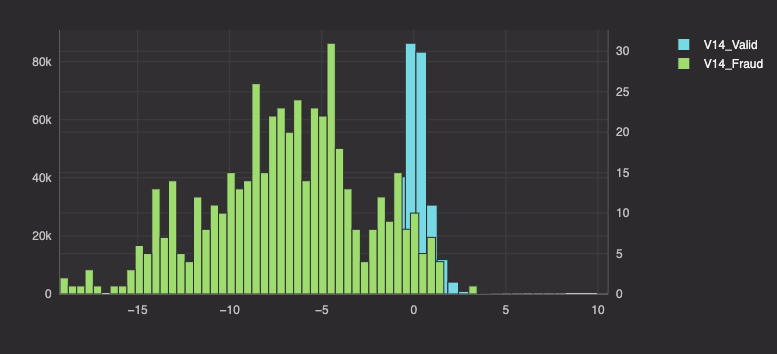
Moving forward, our queries will analyze only the following columns:
TimeV4V12V14Class
The solution
The clustering algorithm
Ok, so we want to classify spatial outliers. How can this be done with the data at hand?
We're going to use DBSCAN - Density Based Spectral Clustering of Applications with Noise. Why use DBSCAN?
- DBSCAN can find arbitrarily shaped clusters - we know little about what our cluster(s) will look like.
- DBSCAN can find an arbitrary number of clusters - we want one single cluster.
- DBSCAN is robust to outliers - which is exactly what we're looking for.
- SciKit-Learn offers an intuitive and highly customizable DBSCAN method.
SciKit-Learn's implementation, sklearn.cluster.DBSCAN, has two required inputs:
- A neighborhood distance.
- The number of neighbors to be considered part of a cluster.
There are a number of additional optional input parameters that can be specified, although we won't cover them here since we won't use them.
We're going to use four hours worth of purchase data to fit our DBSCAN model, and then four hours of live data on which we will make predictions. These two sets will be separated by 24 hours. Once we split the data, we need to set our model's input parameters.
Our training set will consist of purchases that occur between hours 12 and 16. Then, our testing set will consist of the four hour window that occurs 24 hours later - purchases that occur between hours 36 and 40. We are separating our training and testing sets by 24 hours because we expect purchases to have similarities on a per-day basis.
Choosing the neighborhood distance
The first input parameter we must choose is the neighborhood distance. In DBSCAN, the neighborhood distance corresponds to a radius around a given point. Thus, a "neighborhood" around a point is a sphere with the point at its center. Making an informed decision about the neighborhood distance will improve the accuracy of a DBSCAN model.
A DBSCAN neighborhood distance is typically chosen based upon every point's distance to its nearest neighbor. If these nearest neighbor distances are placed in ascending order, a curve is created. The most common choice of neighborhood distance is at the "knee" or "elbow" of the curve. Let's create this curve, plot it, and pick our neighborhood distance.
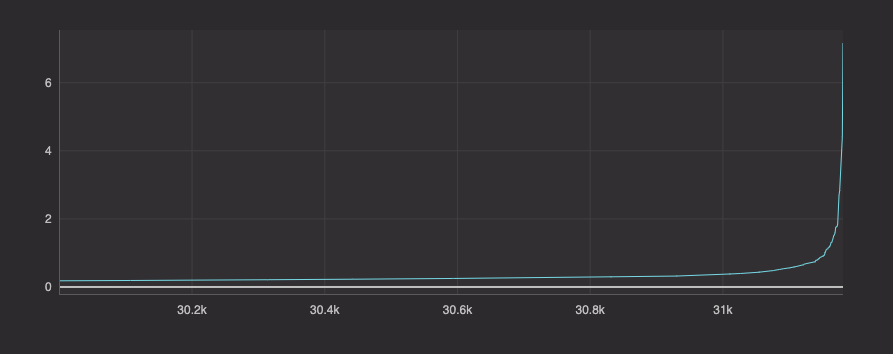
There are 31,181 purchases in our training window. The elbow of the curve occurs right near the end of our plot, so we cut out the first 30,000 points from our plot. The elbow of this curve occurs where the neighborhood distance is almost exactly one. Thus, we'll use 1 as our first input to DBSCAN.
The number of neighbors
The second input parameter we must choose is the number of neighbors. This input corresponds to the number of other points that live within the neighborhood distance of a given point for it to be considered part of a cluster. Thus, DBSCAN checks every point in the set to see how many other points reside within its neighborhood. If a point has greater than or equal to the specified number of neighbors, it's part of a cluster. If less, the point is considered noise. There is some special handling done to discern clusters from one another, but that doesn't apply to this problem. What we want is one single cluster of valid purchases. Any point not belonging to that single cluster is then considered a fraudulent purchase.
There is more flexibility when choosing this parameter. The general rule of thumb is that this value should be higher than the number of dimensions in the data. We have 3 dimensions. We'll use 10 for the number of neighbors based on some trial and error.
To see the effect of each input on the training data, consider modifying them by running the fitting the model code down below, and seeing how they affect the model's accuracy.
Fitting the model and using the fitted model
We'll fit the model on four hours of data, then use the fitted model to predict fraud on a four hour window that occurs 24 hours later. We do this because we expect a degree of similarity between the number of purchases and the rate of fraud during the same time periods on different days.
If DBSCAN were to be used in a real fraud system, it could be wise to train models for various phases of the day, and then deploy these various models at the time of day for which they are most effective.
The code
Ok, lots of talk but little code so far. Let's get into the actual solution as it works in Deephaven.
Fitting the model
We first need to fit the model to our data. Our training features consist of columns V4, V12, and V14. Our training targets are in the Class column. For training, we want hours 12, 13, 14, and 15.
Let's fit the model using this training data and the inputs we specified earlier.
There's quite a bit going on in the code below. Let's break it down into steps:
- Import everything we need for static and real-time analysis.
- Read the CSV data into memory and create training and testing tables from it.
- Add timestamps to the testing table for later use.
- Create a function to fit a DBSCAN model with our chosen inputs to the training set.
- Construct functions to scatter and gather data to and from Deephaven tables.
- Apply DBSCAN to the training data via the
learnfunction. - Check how the model performs.
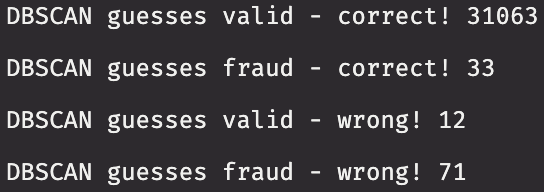
Sweet! Let's break down the model's performance:
- 31063 out of 31075 valid purchases are correctly identified (>99%).
- 33 out of 45 fraudulent purchases are correctly identified (73%).
- 12 fraudulent purchases are misidentified as being valid - these are false negatives (27%).
- 71 valid purchases are misidentified as being fraudulent - these are false positives (<1%).
These results are pretty good. Let's move forward!
Real-time fraud detection
We already have the test_data table in memory. We want to replay it in real time based off the timestamps we created in its DateTime column. We can do this using Replayer.
DBSCAN isn't a model built for real-time processing. We must leverage what we know about the DBSCAN model we've created on our training data in order to create a real-time method that utilizes our model:
- The fitted model has one cluster.
- A point is part of this single cluster if it has 10 neighbors within a radius of 1.
- A point is not part of the cluster if any of its nearest 10 neighbors are further than a distance of 1 away from it.
With this knowledge, we can compare test data coming in real time to our training data and see if it is part of the single cluster.
The code below can be broken into steps:
- Replay the test_data table in real time.
- Construct a function to predict the validity of incoming purchases using the training data and our model.
- Create function to scatter and gather data to and from a Deephaven table.
- Use
learnto apply our model to the real-time updating table. - Create derived tables that show how our models perform in real time.
Conclusion
Now we have our fitted DBSCAN model classifying fraud in real time! We can see that as new rows are added, our model is accurately identifying fraud as it comes in! However, our model doesn't catch every fraudulent purchase. Perhaps a DBSCAN model with different parameters would work better? There may be different models that are better suited to this problem altogether.
Nevertheless, we are able to construct a relatively simple model and that works pretty well on a difficult problem. Extending the model to use Deephaven tables is intuitive and easy, and extending a static solution to work on real-time live data is equally so.
What kind of data science problems can you solve on live data using Deephaven? There's an innumerable wealth of data out there that needs processing, and Deephaven is an excellent tool for doing just that.