Real-time sentiment analysis using an LSTM network in TensorFlow
A Python machine learning model to analyze streaming Twitter data
February 8 2022


AI is fundamental to modern strategies for deriving value from unstructured language. TensorFlow enables data scientists to create sophisticated, large-scale neural networks and is a staple for text-based applications like sentiment analysis. The value of these models increase if they're usable with real-time data.
Deephaven is a natural pairing for AI libraries like TensorFlow. It couples real-time and batch data processing in a single abstraction and provides infrastructure to support your TensorFlow build, train, test, and deploy cycles.
I implement a basic sentiment analysis within the Deephaven framework and deploy it on a (simulated) real-time feed of tokenized Twitter data. It analyzes tweets from a GOP debate from 2016, per a Kaggle project. For obvious reasons, I simulate the real-time data streaming via replay (Deephaven makes that easy), but the training and deployment processes could be applied to many of today's real-time use cases. Approval ratings and public opinion assessment are examples that come to mind.

I closely follow Peter Nagy's LSTM model. It has strong instructions and an honest assessment of strengths and weaknesses of LSTM. My code extends Mr. Nagy's method to provide a real-time implementation. It's available in the Sentiment folder in Deephaven's Examples repo.
The dataset
Kaggle's dataset provides sentiment.csv containing 13,871 tweets. Each row of the file has 21 columns corresponding to who wrote the tweet, what the tweet was about, its sentiment, and other parameters. For this use case, we care about two columns only:
textsentiment
Imports and data ingestion
Let's start by removing tweets which have neutral sentiment. We want to identify tweets that are positive or negative, since those show the respective Twitter user's feelings towards a subject. After this paring, we're left with 2 columns and 10,729 rows of tweet data.
In order to perform sentiment analysis, we need to turn the tweets into numeric data. We can do this using the Keras Tokenizer. We also need to prune the text itself by casting all of it to lower case letters and removing non-alphabetic characters. Lastly, to ensure the tokenized sequences are of the same length, we'll use the Keras pad_sequences method.
Since Deephaven can run Python natively, I can perform all of these tasks within the engine process.
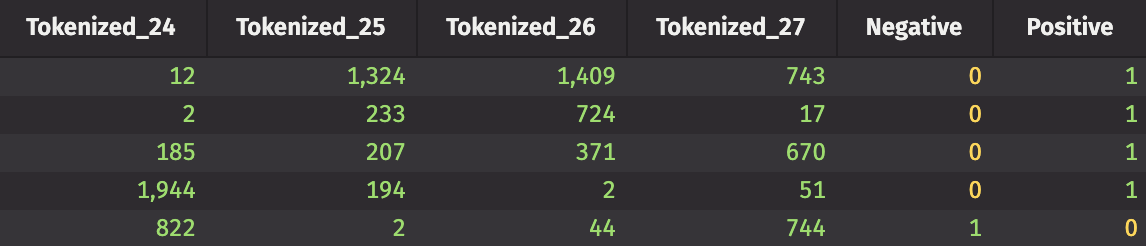
Our new table, tokenized_sentiment, has 28 columns of tokenized text data, and two columns that indicate positive or negative sentiment about each tokenized tweet. This is the data we'll use to train and test the neural network. Speaking of which, it's time to create that model. We'll be using an LSTM network. LSTMs are particularly popular in time-series forecasting and speech/image recognition, but can be useful in sentiment analysis, too.
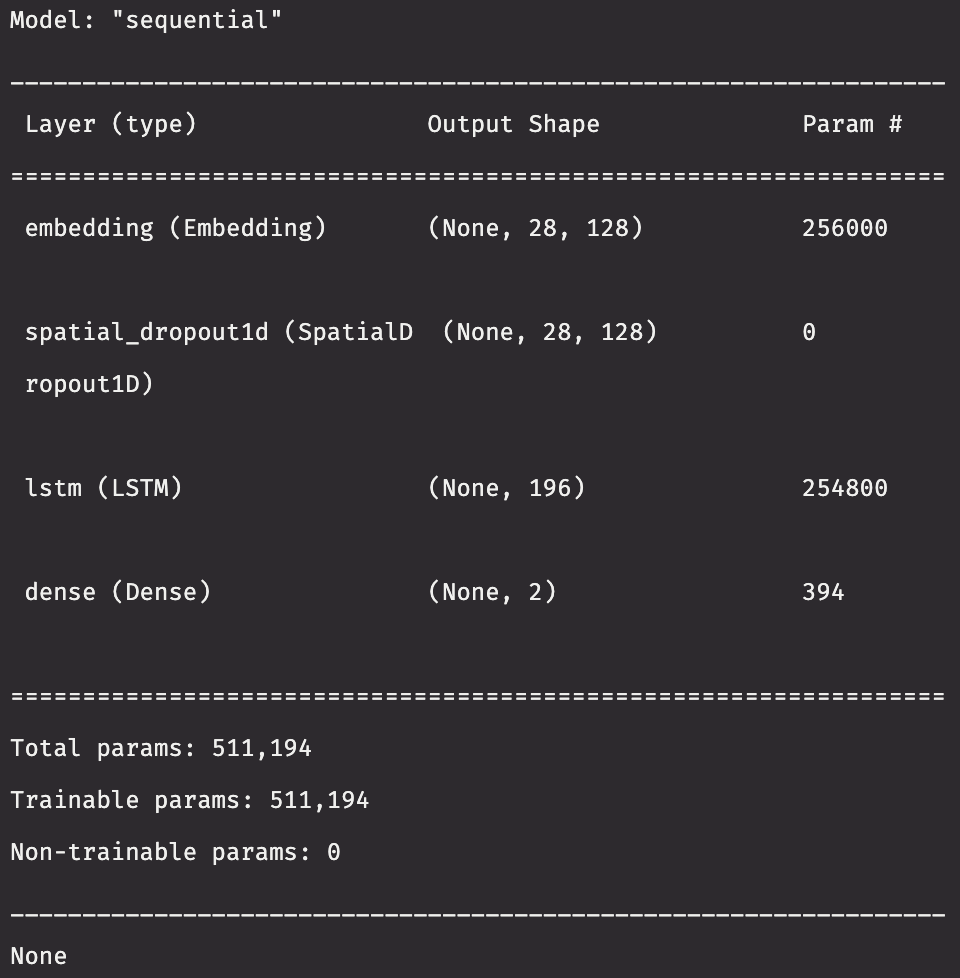
Split the data into training and testing sets
In Nagy's guide on Kaggle, he uses SciKit-Learn to split the data into training and testing sets using train_test_split. This is probably the most popular way to split data into training and testing sets for AI applications in Python. However, I'm going to avoid using any packages outside of the Deephaven + TensorFlow installation. I'll split the data randomly using only NumPy methods.

Define functions for data I/O between Python objects and Deephaven tables
When using deephaven.learn, you are required to define how data is transferred to and from Deephaven tables and Python objects. In this case, we define two functions:
table_to_numpy_int: This returns a two-dimensional NumPy ndarray of integer values taken from select rows and columns in a Deephaven table.numpy_to_table: This returns a single value (this won't get used until the very end of the example).
Every time learn is called, table_to_numpy_int will be used. This function defines how data in a Deephaven table is transferred to a NumPy array, which we'll need in order to do anything with the sentiment analysis model. The second function, numpy_to_table, won't get used until the trained model is used to make predictions.
Train the model
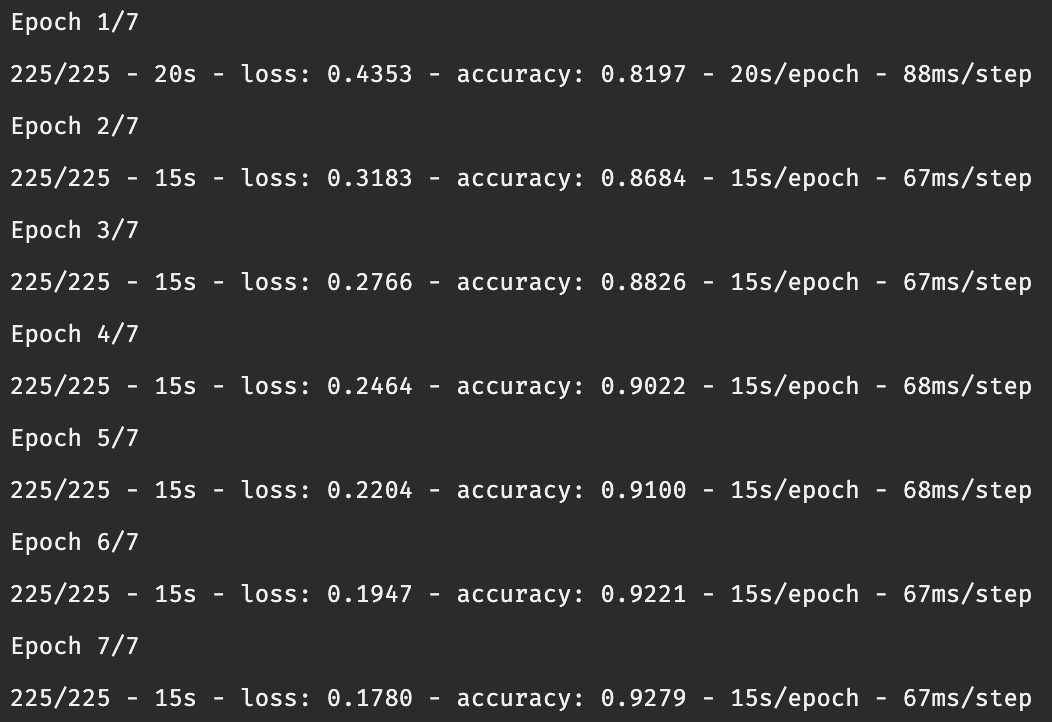
It's time to train our model using the data in the testing table. Nagy chooses to train the network for 7 epochs for the sake of time. If you have the patience to wait a while, increase the number of training epochs to a larger value. Remember, in Deephaven, training a model will be done inside of a function.
Validate the model
Nagy does this in two steps. The first measures the score and accuracy of the model, and the second reports the percent of correct sentiment predictions. I'll combine this into one function.
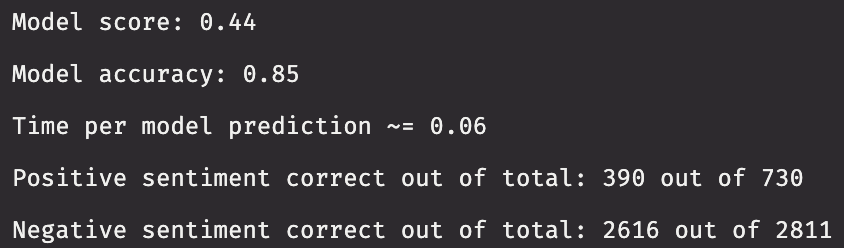
This particular model does a great job of identifying negative sentiment, but a rather poor job on positive sentiment. This is likely due to the class imbalance, as around 80% of the tweets in the data (excluding neutral sentiment) have negative sentiment. Neural networks models such as this one tend to have difficulty in dealing with class imbalances.
Real-time sentiment analysis
Deephaven's strengths lie in its ability to handle numerous external data feeds as well as perform analysis on both real-time and static tables. So, let's use the trained model on some real-time data. The tweets in the dataset don't have timestamps attached to them, so we'll simulate the real-time feed by writing anywhere from 1 to 10 tweets to a table every second. Additionally, the simulated feed will write the tokenized text data rather than the tweets themselves.
Conclusion
This article demonstrates the creation, training, and deployment of a sentiment analysis model on both historical and real-time data. It uses Deephaven to extend standard Python AI to streaming tables. These are fundamental capabilities of the engine and speak to its interoperability.
Further reading
My friend, Jake Mulford, recently wrote a piece about Reddit Sentiment Analysis. It complements the efforts described above.
I used Deephaven with TensorFlow and examples as a base for the application in this article. Deephaven with TensorFlow provides a quickly-deployable Docker image to get started with TensorFlow in Deephaven. Alternatively, you can install TensorFlow and other packages manually.
I've previously covered AI/ML in Deephaven using SciKit-Learn doing Credit Card Fraud Detection and Diabetes Classification. I look forward to exploring (and sharing solutions for) more use cases at the intersection of real-time data and AI.