Get the most up-to-date crypto data
Using Apache Airflow to transform up-to-date crypto data
September 7 2022



The biggest players in the crypto space all use AI to predict prices and manage investments. So should you. Doing so isn't as difficult as you might think.
With the right tools, AI workflows are intuitive and easy to manage.
This is the first in a six-part blog series on real-time crypto price predictions with AI. In this blog, I'll cover the use of Apache Airflow for the acquisition of up-to-date crypto data.
Throughout this series, you'll learn how to:
- Acquire up-to-date crypto data with Apache Airflow
- Implement real-time AI with TensorFlow
- Implement real-time AI with Nvidia RAPIDS
- Test the models on simulated real-time data
- Implement the models on real-time crypto data from Coinbase
- Share AI predictions with URIs
In this blog, I will walk you through the first stage of obtaining crypto data. Apache Airflow is a powerful tool for automating the acquisition of crypto data.
Automate data acquisition with Apache Airflow
To get started with Apache Airflow, follow the setup instructions. Once setup is complete, run:
This starts the Apache Airflow server.
A directed acyclic graph (DAG) is a concept in computing that is used to define the order of calculations. Apache Airflow uses DAGs to define the relationships, order, and scheduling of tasks in a workflow. Deephaven uses DAGs to organize the flow of data through queries.
The code below uses a simple Airflow DAG to fetch and transform BTC data on the Gemini exchange from cryptodatadownload. The DAG defines the order and scheduling of operations.
Click to see the code!
The workflow presented in the code is straightforward:
- Obtain BTC data from cryptodatadownload.
- Transform the data and save timestamps and prices to Parquet.
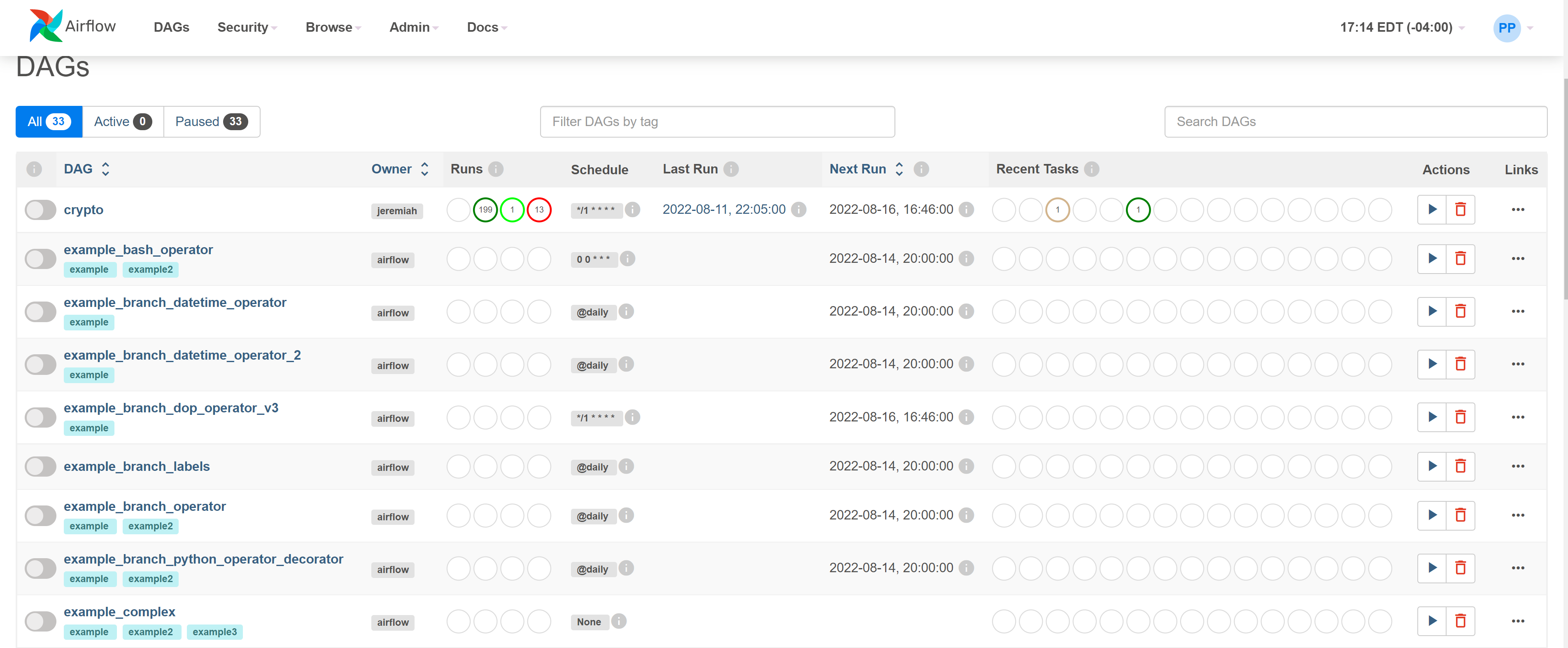
Airflow manages this workflow by calling it at scheduled intervals. This is managed by the schedule_interval input to the DAG. Check port 8080 in your web browser to see more details about the DAG, including number of runs, previous run, next run, interval, and more.
With the dynamic data pipeline set up, next comes the fun part: implementing machine learning models. Stay tuned for the next blog in the series where I'll implement TensorFlow and PyTorch LSTM models to predict prices.