Release notes for Deephaven version 0.33.0
Visualize partitioned tables, read Parquet from AWS S3, and more
February 23 2024

Deephaven Community Core version 0.33.0 is now out. We're excited about it and hope you will be too after reading the release notes! Let's take a closer look at what it includes.
New features
Read Parquet from AWS S3
Deephaven can now read single Parquet files from AWS S3. The code block below fetches data from a public S3 bucket. This new experimental feature is under active development, so stay tuned for future developments as we expand on it.
Rollup table weighted average
Weighted average aggregations can now be calculated from a rollup table, like in the code block below:
Custom formulas in rolling operations
The update_by table operation now supports custom user-defined formulas. Like other update by operations, these formulas can be cumulative, windowed by ticks (rows), or windowed by time. Custom formulas used in update_by operations follow the same rules as custom formulas in aggregations.
The following code block uses the new rolling formula update by operations to calculate a rolling sum of squares of prices by ticker.
Support for 1D arrays in Numba decorators
Version 0.33.0 has added support for Numba's guvectorize decorator to be used in table operations. It currently supports 1-dimensional arrays, with support for multi-dimensional arrays being eyed for a future release.
The following code block uses this decorator on the function g, which is used in a table operation. g takes a 1-dimensional array and scalar value as input, and returns another 1-dimensional array.
Partitioned table viewer
Partitioned tables are tables containing a column containing other tables (constituent tables or subtables) with the same schema. They can provide a nice boost to query performance if used properly. The biggest drawback of partitioned tables has always been the inability to visualize the data they contain. That is no longer the case - we've added a partitioned table viewer to the Deephaven UI. Now, create a partitioned table, and you can see its data by default.
The following code block creates a partitioned table from the same table used in the previous section using a single partitioning column.
In Deephaven Community Core 0.32.1 and earlier, visualizing prices_by_ticker can only be done with one or more table operations that return a normal table. Now, in 0.33.0, the viewer allows you to view any of its constituents simply from the UI.
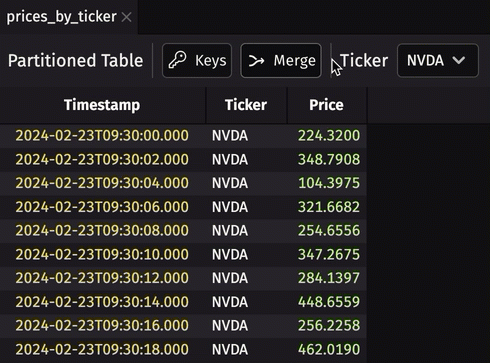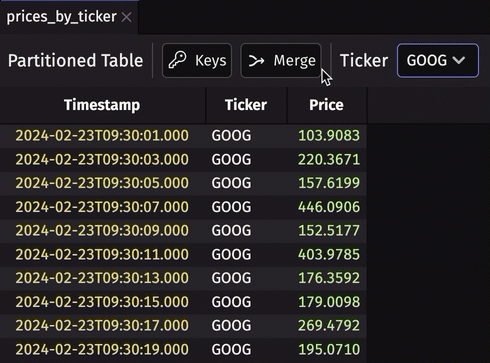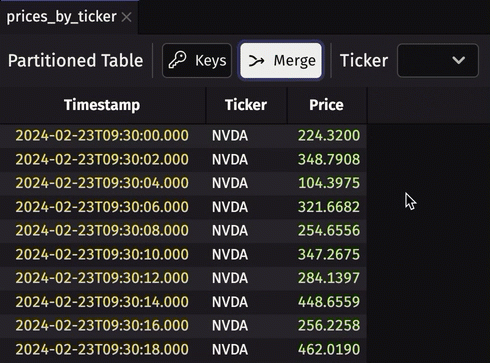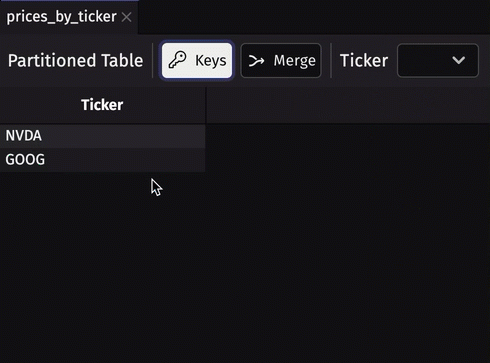
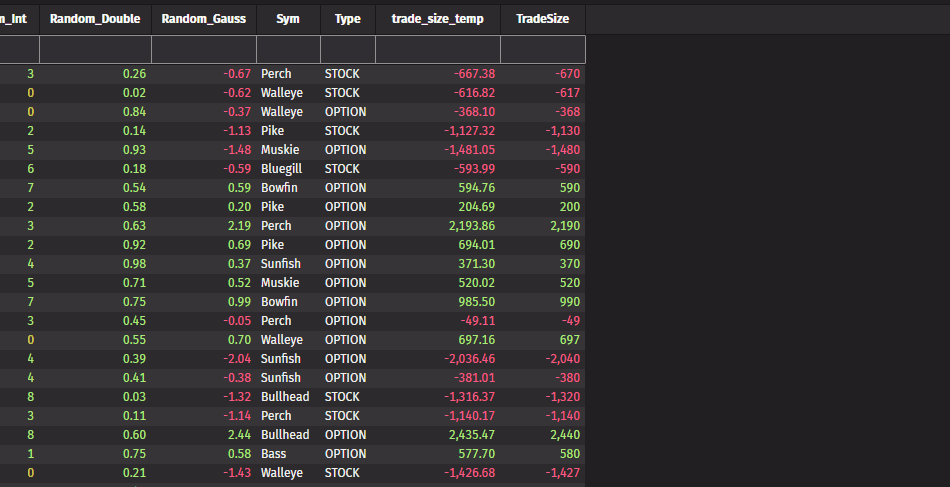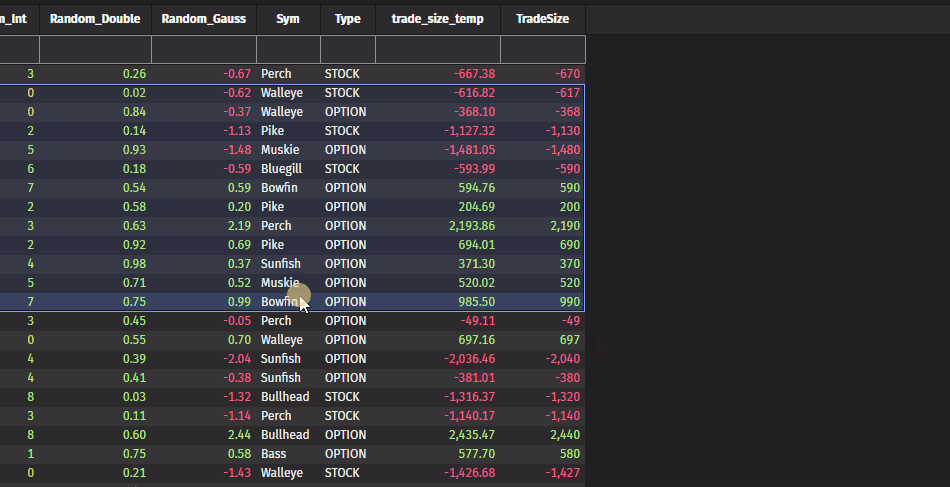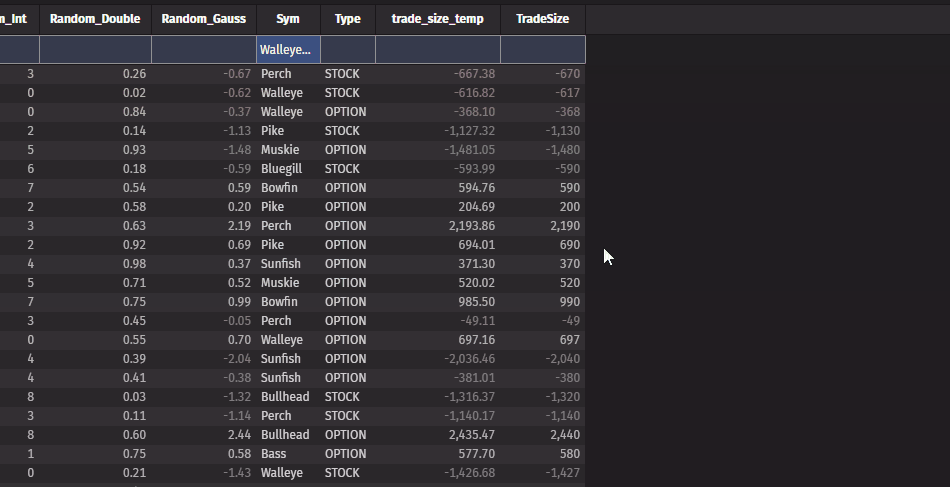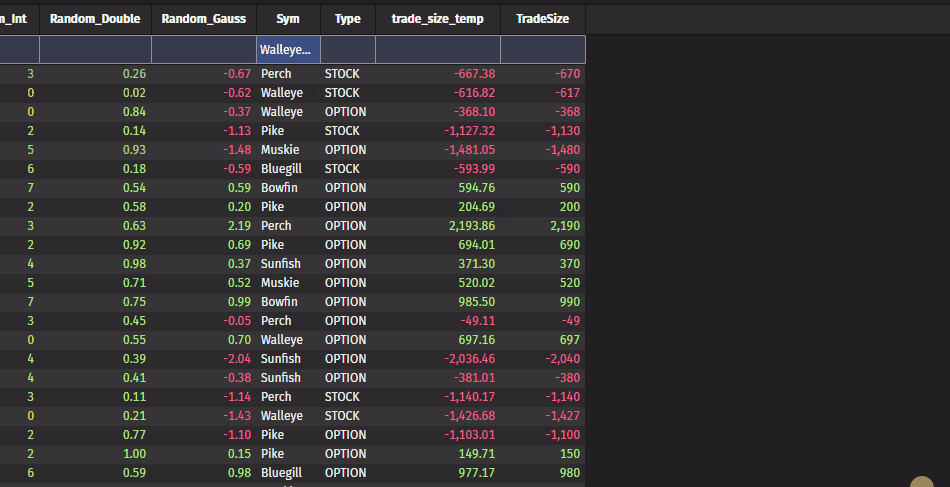
Filter by multiple selections in the UI
You can now filter by multiple rows easily via the UI. Right-clicking inside a selection of multiple rows allows filtering by all distinct values in that selection.
Bug fixes
Blink tables, select, and update
Prior to version 0.33.0, calling select or update on a blink table did not propagate an attribute that would cause aggregations to remember data history. This has been fixed, so aggregations on blink tables now work as you'd expect. Blink tables still provide all of the same memory and performance benefits as they always have.
Improvements
Python performance
The developer team found some areas of our Python API whose performance could be improved. One of those improvements is included in the 0.33 release, so your Python queries could benefit from bumping to this latest version. More improvements to Python performance are coming in future releases, so stay tuned for future announcements.
Reach out
Our Slack community continues to grow! Join us there for updates and help with your queries.