Release notes for Deephaven Core version 0.36
Multi-table listeners, native table iteration in Python, and more
August 20 2024

Deephaven Community Core version 0.36.0 is available now, with several new features, improvements, bug fixes, and more. We've rounded up the highlights below.
New features
Native table iteration in Python
Four new table operations are now available that allow you to iterate over table data in Python efficiently. They are:
The first two iterate over the table one row at a time, while the latter iterate over chunks of rows. All four methods use efficient chunked operations on the backend and return generators to minimize data copies and memory usage, making them ideal for large tables. Take a look at how they're used below:
Multi-table merged listeners
Prior to 0.36.0, you could only listen to a single at a time with a table listener. If you wanted to listen to multiple tables, you had two options: use multiple listeners or combine the tables. Merged listeners now allow you to listen to an arbitrary number of tables, giving you added, modified, and removed rows from each one of them on every update cycle. Here's how you can listen to multiple tables at once:
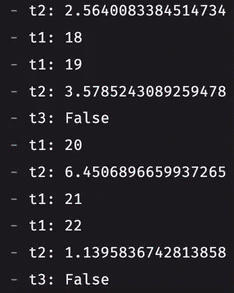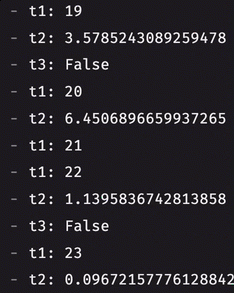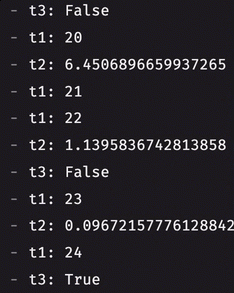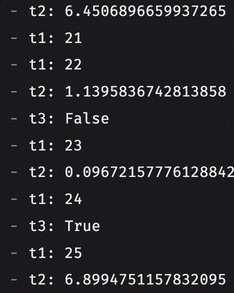
Table definitions in Python
Want to export a table definition from Python? Now, tables have a definition attribute that returns a JSON table definition:
Compare tables more easily
There's a new method that makes comparing tables easier. Use it to find differences in tables, such as columns, size, and more. Here's how it's used:
Parquet and S3
Two new features have been added to Deephaven's Parquet integration:
- It now supports reading Parquet files from S3 that include metadata files.
- It now supports writing Parquet files to S3.
pip-installed Deephaven CLI
In release 0.34, a command line interface was added for pip-installed Deephaven. This would always automatically open a browser window. Now, the boolean config flags --no-browser and --browser have been added to control this behavior. The default behavior is still the same.
Improvements
Iceberg
- Deephaven can now get a table definition for an Iceberg table without having to read the table first.
- Iceberg tables with invalid Deephaven column names will automatically be renamed to follow Deephaven conventions when consumed into tables.
- Iceberg snapshot tables produce
Timestampcolumns of Instant data type.
Performance
- Improved performance and memory use of
naturalJoinin incremental cases where there are no responsive rows in either table. - Increased parallelism in partition-aware source tables, as well as an option to assume partitions are non-empty.
- Parallel table snapshots, which can improve performance particularly in cases when reading tables with many columns from S3.
Dependencies
- Upgraded to jedi autocomplete 0.19.1. See the jedi changelog here.
Client APIs
- The Java client now has a gRPC user agent, which includes relevant version information by default.
Bug fixes
Server-side APIs: Python
- Liveness scopes can now manage table listeners in Python.
- Errors raised by table listeners in Python now properly notify any applications used by the server.
Server-side APIs: General
- Sorting dictionary-encoded string columns with null values will now work as expected.
- URI path conversions now work correctly on Windows.
- Floating point comparisons are now consistent with floating point hash code standards.
- Java and Python wheel artifacts now have the same dependencies.
- Reading from Parquet with a millis- or micros-since-epoch timestamp column no longer fails with a null pointer exception.
Client APIs
- A bug in the Go and JS client authentication that could erroneously require entering login information twice has been fixed.
Parquet
- Parquet files with missing dictionary page offsets are now read correctly.
- Deephaven's Parquet reader now correctly handles dictionary-encoded strings in Parquet files.
Kafka
- Deephaven's Kafka JSON specification now correctly propagates null values for integer fields.
Breaking changes
- Deephaven codec classes were moved into a subfolder of
io.deephaven.util. They are now found inio.deephaven.util.codec. - Empty arrays have been moved from
CollectionUtiltoArrayTypeUtils. - Several methods were moved between
TypeUtils,ArrayTypeUtils, andNumericTypeUtilsincludingisBoxedNumeric,isNumeric, andisBigNumeric. holdsLock,notHoldsLock,instanceOf, andnotInstanceOfwere moved fromAssertandRequire.- Several methods were removed from Barrage utilities.
snapshot_whennow requires the trigger table to be append-only if history is requested.
Reach out
Our Slack community continues to grow! Join us there for updates and help with your queries.