Release Notes for Deephaven versions 0.18, 0.19, and 0.19.1
Python Vectorization, new features, and enhancements
December 16 2022

The Deephaven team moves on its mission to make real-time data easy with Python and to evolve the framework’s capabilities for use cases driven by its UI, server-side Java, or multi-language APIs. Below is a quick summary of features delivered in the last six weeks, covering versions 0.18.0 through 0.19.1.
The detailed release notes can be found on GitHub:
Many Python improvements
New infrastructure to support auto-complete in Python
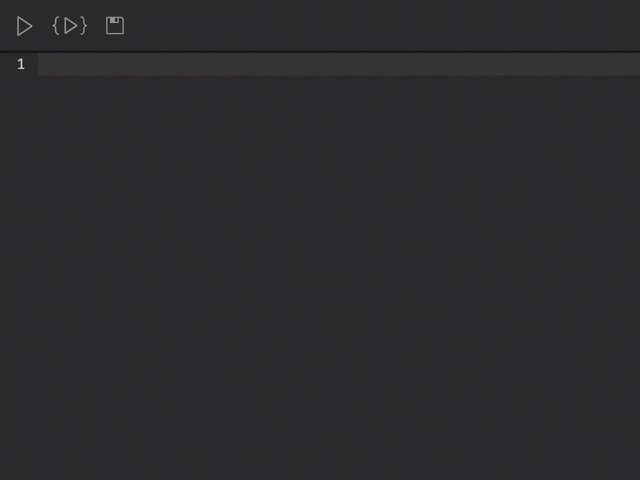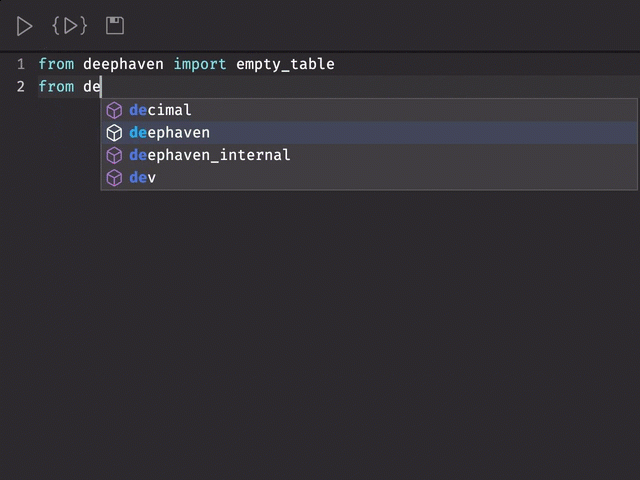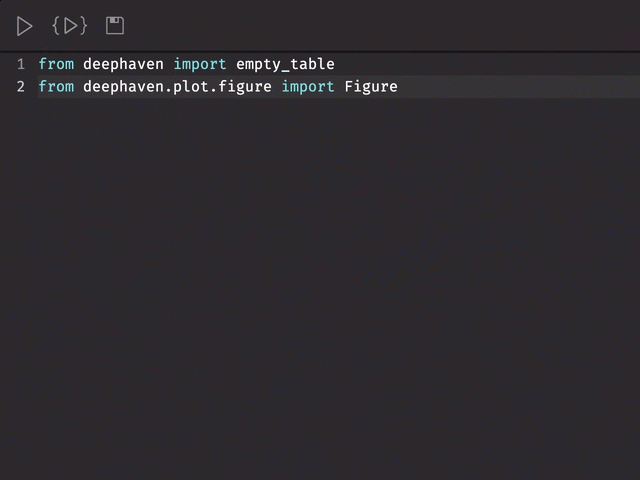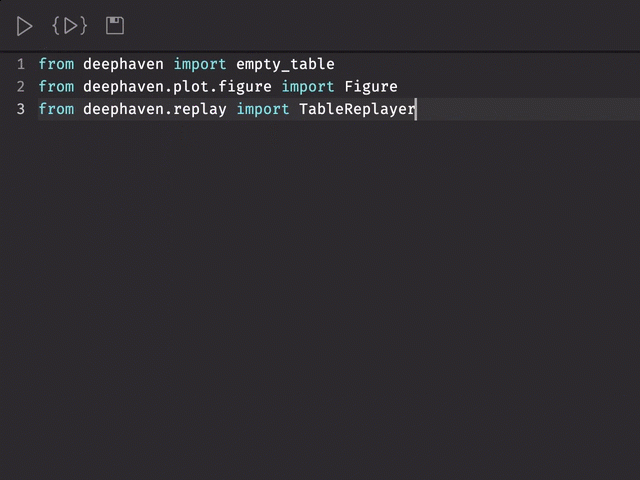
The data-IDE available in the Web-UI is now integrated with the Jedi Python autocomplete library to provide you with type-ahead support while working in Deephaven.
For Docker users, autocomplete will be on by default in the 0.19.1 Docker images, and for users who maintain their own environment, you can enable it with:
You will notice autocomplete suggestions when importing types; accessing global variables, class, field and method names; and handling file paths "within strings.” In future releases, we will work on improving results for more complex expressions, giving more feedback in autocomplete results, and integrating suggestions for Deephaven table column names.
Disabling autocomplete is documented in the configuration guide related to the console service.
Vectorization of Python functions
Vectorization is oftentimes used to speed up computations in Python. Deephaven now tries to automatically vectorize Python functions used in formulas and filters to (i) take advantage of chunking and (ii) minimize the number of Python-Java boundary crossings. Addressing arrays of data (chunks) is much more efficient than per-element computations within the engine.
The 'vectorizable' formulas/filters must be in the form below, typically found within an update or select operation.
Type inference for Python
It is powerful to marry Python functions to real-time data with Deephaven. Consistent with our constant pursuit to also make it easy, Deephaven now supports Python type hints, so you don’t have to cast explicitly. Type hints allow Python to infer the correct input and/or output data types from functions. This can often reduce syntactic bloat. Here is a simple example:
Animation is now available in both Seaborn and Matplotlib
You want real-time, updating visualizations. Deephaven’s native plots all update in real time, whether displayed in dashboards, the web IDE, or Jupyter.
However, the Animation class made available in Matplotlib and Seaborn opens up a huge range of visualizations beyond the plotly-backed graphs Deephaven natively supports. These animations marry well to Deephaven’s Streaming Tables.
Animations are designed to repaint plots on a cycle you designate; for example, every few seconds. Given Deephaven’s core capabilities, your Seaborn and Matplotlib plots will inherit and manage changes intra-cycle. The two libraries employ similar techniques. Our user guide now includes separate animation docs for Seaborn and Matplotlib.
Input tables are now available in Python
Input tables are powerful building-blocks and are now available in Python. These are server-side constructs designed primarily for tables of user input values, whether sourced locally, from a UI, or from another client app. These are easy to update – append rows, add to a table in bulk, or use keys to modify data.
With Input Tables, you have a malleable in-memory object that can be incorporated as a first-class citizen in your DAG. Proper documentation is on its way, but here are the pertinent PyDocs.
More Python improvements
- Table
sliceis now a first-class Python operation in Deephaven. As you would expect, syntax like the below will produce a table comprised of the 2nd through the 6th rows of thesource_table:
- Python 3.11 is now supported.
- The update graph processor, the “UGP”, is now defaulted to lock the Global Interpreter Lock (GIL) automatically. You can configure it otherwise if you so choose.
Other upgrades
All via a single websocket...
The websocket protocol has been re-engineered to let it behave as a transport on which multiple streams, across services, can be conveyed. Custom metadata/headers give the path to the desired remote procedure call.
Improvements to QST
The Query Syntax Tree (QST) is a directed acyclic graph that fully describes the hierarchical components of a Deephaven Table. It has the potential to describe functions composed of Tables. Every operation is expressed as an explicitly typed class. It can be seen as a high-level interface for “what you can do over gRPC” and serves as the basis for the Java client. To address its coverage of operations, the where_in and ungroup methods were added to its suite. Further investments will be made on this path in January, with an intention for all query operations to soon be covered by the QST.
And a bit more...
- The Parquet integration was improved to handle BigInteger data types better.
- The C++ client API was upgraded to use Arrow’s GetSchema. Also, the C++ client documentation was significantly improved.
- A few edge cases were addressed in the TableReplayer.
- When importing CSVs via the Web-UI, date-times are now parsed more appropriately.
Investments in features that are on the way...
Though there will be holiday family time, as appropriate, the team will remain hard at work. The list below foreshadows current priorities:
- Natural availability of a debugger in Python workflows.
- Delivery of real-time, updating roll-ups and tree-tables, engineered to take advantage of Deephaven’s slick partitioned tables feature. This will be plumbed through to the Web-UI, as you would expect.
- Rolling aggregations that piggy-back on the utilities supporting today’s cumulative-aggregation suite.
- Refinements to allow you to hook up integrations for authentication and authorization.
- The support of streaming data to Python clients.
- Bidirectional integration with Arrow tables.
- An ODBC integration.
Further communication
Changes in the docs since the last release are presented in this blog piece. We look forward to working with you on Deephaven’s Slack or GitHub Discussions.