

Deephaven is a powerful analytics engine that makes processing large data more intuitive than ever. Iceberg is a table format that provides fast, efficient, and scalable data storage. Combining the two is like bringing Holmes and Watson together to solve a mystery. In this blog, we'll explore Deephaven's new Iceberg integration, why it matters, how to use it, and what's to come.
Deephaven already has integrations with SQL, Parquet, Kafka, and CSV, which can all be used as storage backend for a Deephaven-powered application. Now Iceberg is part of that list as well. If you're looking for a scalable, efficient, reliable, and cloud-native way to store your data and fetch it into Deephaven, look no further.
To follow along with this blog, you'll need Docker. This specifically uses Docker Compose to manage the services, so check out the links if you're unfamiliar with them.
Iceberg is now available as a storage backend for Deephaven, providing a scalable and efficient cloud-native storage mechanism for powerful applications.
A configuration for Deephaven and Iceberg
To use Deephaven in tandem with Iceberg, you'll need a configuration that allows the two to work together. Docker Compose is perfect for this. Below is an extended version of the YAML file found in Iceberg's Spark Quickstart—it adds Deephaven as a service and makes it part of the iceberg_net Docker network so the services can communicate.
docker-compose.yml
You can start these services with a single command:
Create an Iceberg catalog
Iceberg stores data in tables just like Deephaven does. Iceberg tables live inside of catalogs, similar to how directories store files in a filesystem. Creating an Iceberg catalog is pretty easy - the Docker Compose configuration above has access to an Iceberg Spark server in Jupyter at http://localhost:8888. Head there and open the Iceberg - Getting Started notebook. The first four code blocks in that notebook will create an Iceberg table called nyc.taxis. You'll read this table into Deephaven in the next section.
Interact with the Iceberg catalog
After creating the Iceberg catalog, head over to the Deephaven IDE at http://localhost:10000/ide in your preferred browser. To interact with an Iceberg catalog from Deephaven, you'll first need to create an IcebergCatalogAdapter. You can create one in two different ways:
adapter_s3_rest: Creates an IcebergCatalogAdapter from an S3-compatible provider and a REST catalog.adapter_aws_glue: Creates an IcebergCatalogAdapter from an AWS Glue catalog.
Each method will be used below.
With a REST catalog and MinIO
The following code block uses adapter_s3_rest to create an IcebergCatalogAdapter. It requires the catalog URI, warehouse location, region name, access key ID, secret access key, and an endpoint override.
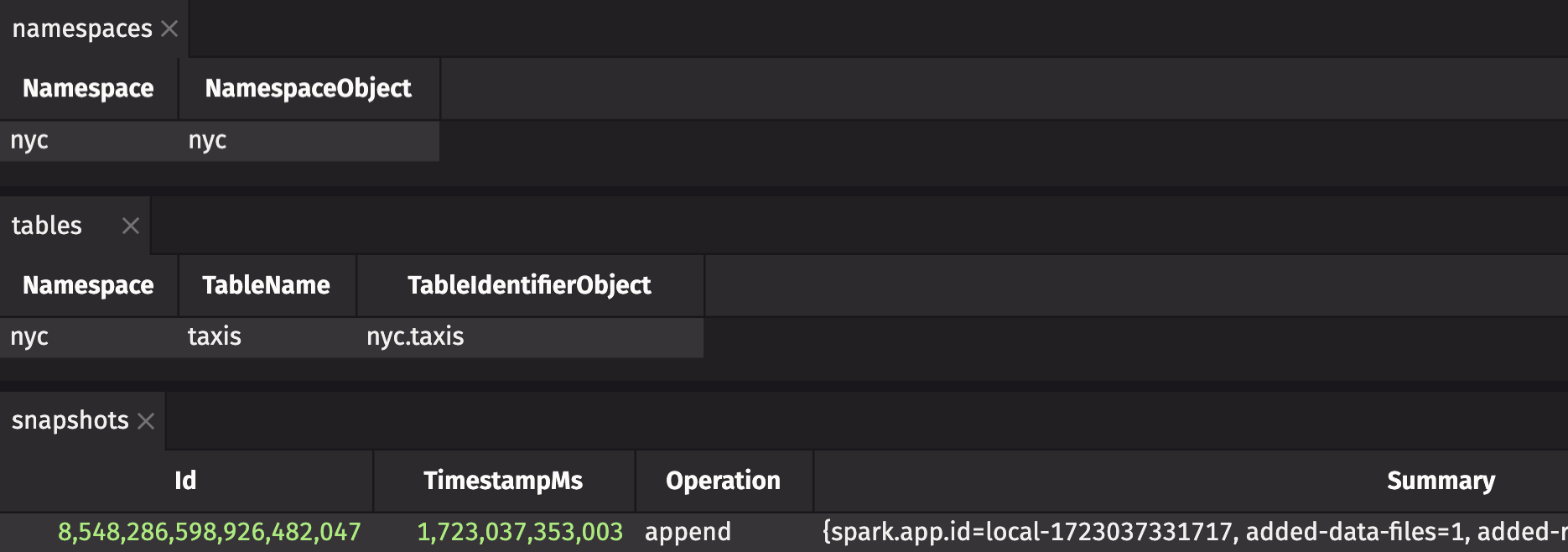
With the catalog adapter in hand, you can now query namespaces, tables, and snapshots in an Iceberg catalog:
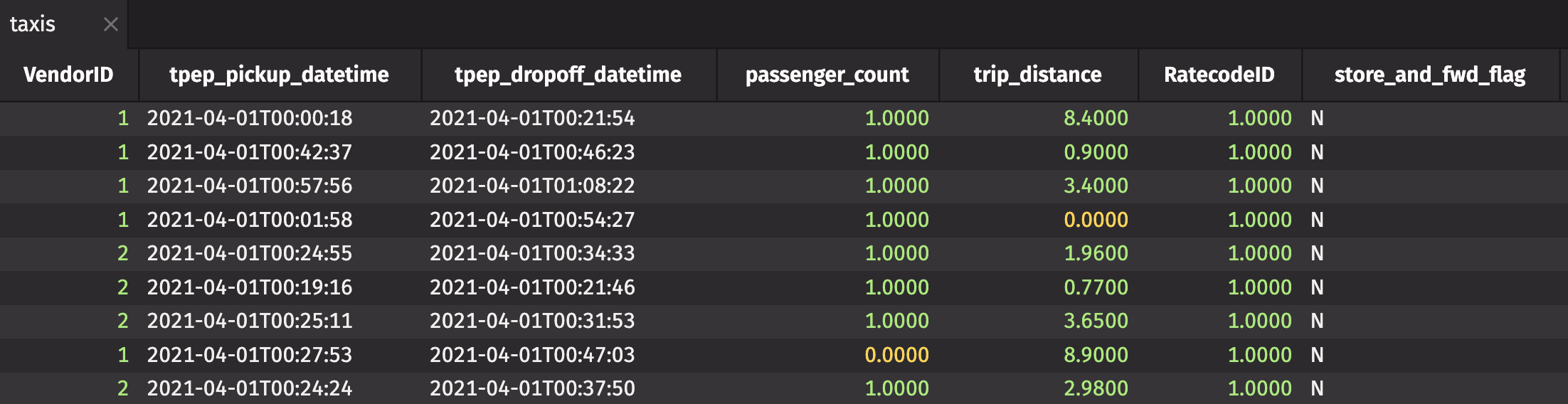
To read an Iceberg table via a REST catalog and S3-compatible driver, you also need to define custom IcebergInstructions. In this case, the instructions give the region name, access key ID, secret access key, and endpoint override for the REST catalog:
With an AWS Glue catalog
Important
To use the AWS Glue catalog adapter, you need an AWS region and credentials. If you are running Deephaven from Docker, mount your AWS credentials as a volume in the Deephaven container. For more information, see here.
adapter_aws_glue creates an IcebergCatalogAdapter from an AWS Glue catalog. It requires a name, catalog URI, and S3 warehouse location:
When using an AWS Glue catalog, custom Iceberg instructions are not required, so you can read the table directly:
Want to see Iceberg in action? Check out this developer demo from Larry:
What's to come
This blog has demonstrated how to import Iceberg tables into Deephaven using a simple example. While these examples are straightforward, they illustrate the workflow for reading Iceberg tables into Deephaven. Our Iceberg integration is currently in development, so you can anticipate additional features, improvements, and examples in the future. As a preview, you can look forward to:
- Support for refreshing (ticking) Iceberg tables
- Generic adapters to make it even easier to interact with Iceberg catalogs
- Writing to Iceberg tables
Reach out
Our Slack community continues to grow! Reach out to us with any questions, comments, or feedback. We'd love to hear from you!