Release notes for Deephaven Core version 0.37
Python linting, an improved Iceberg integration, and new features
November 27 2024

Deephaven Community Core version 0.37.0 is now available. It brings a slew of new features, improvements, bug fixes, and breaking changes. Let's dive into the details.
New features
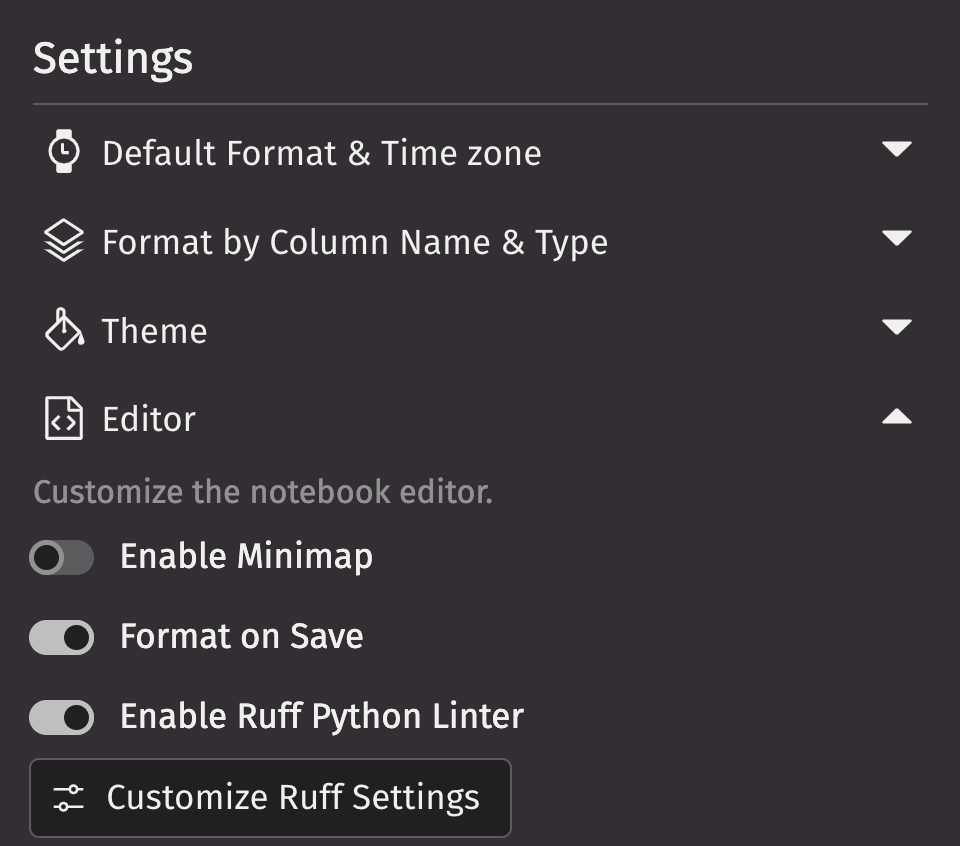
A built-in Python linter
Deephaven now has the ruff Python linter built into the IDE. The integration makes writing Python queries in Deephaven more convenient. You'll be able to write better and more readable queries faster with things like:
- Auto-formatting:
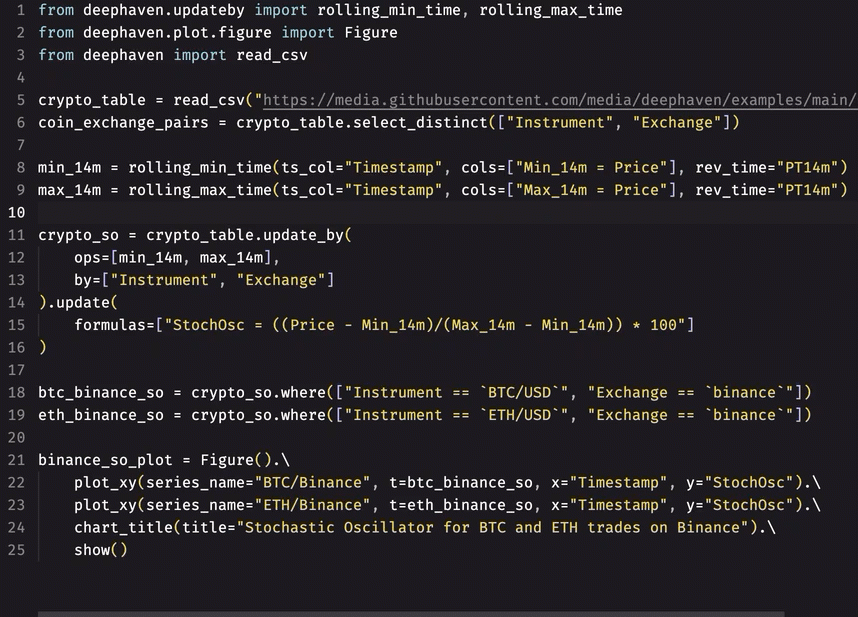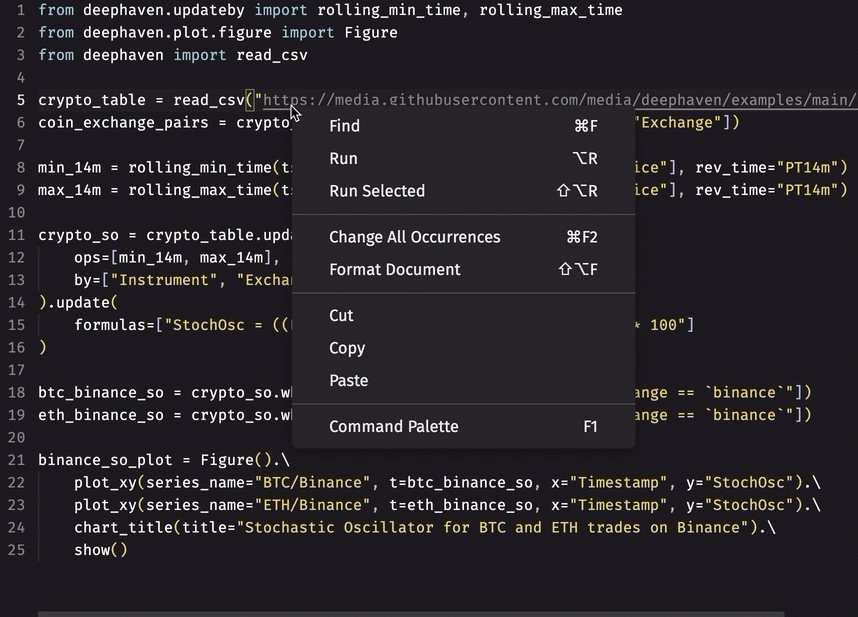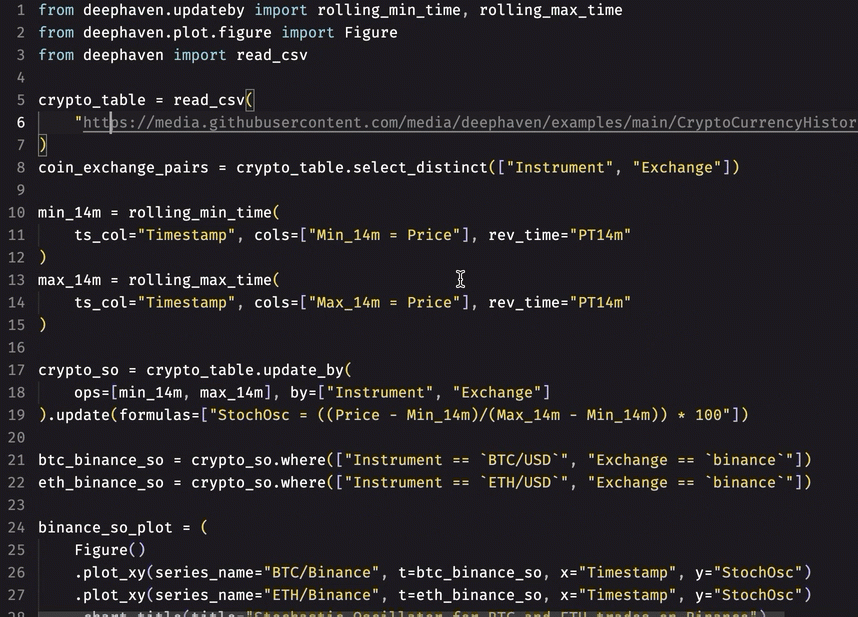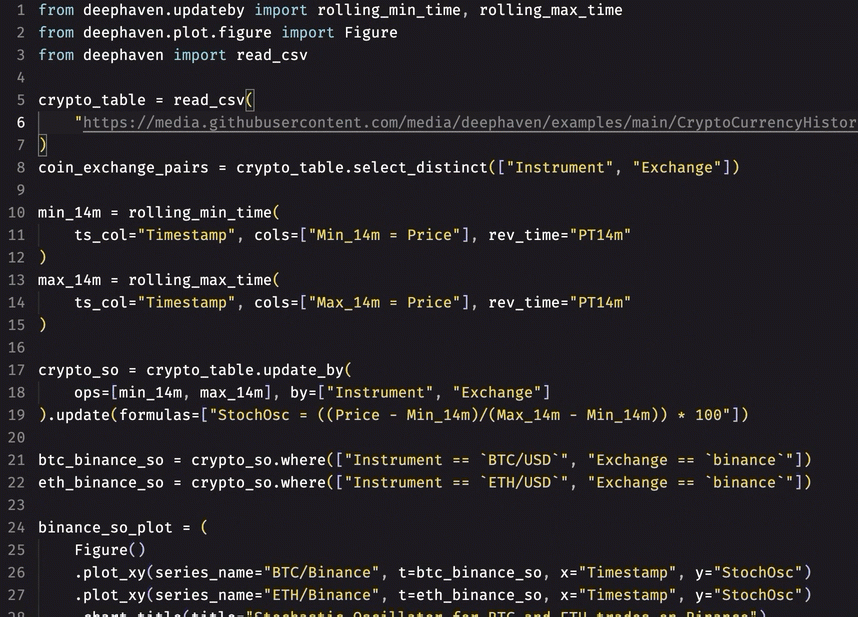
- Instant recognition of unused imports:

- Instant recognition of errors:
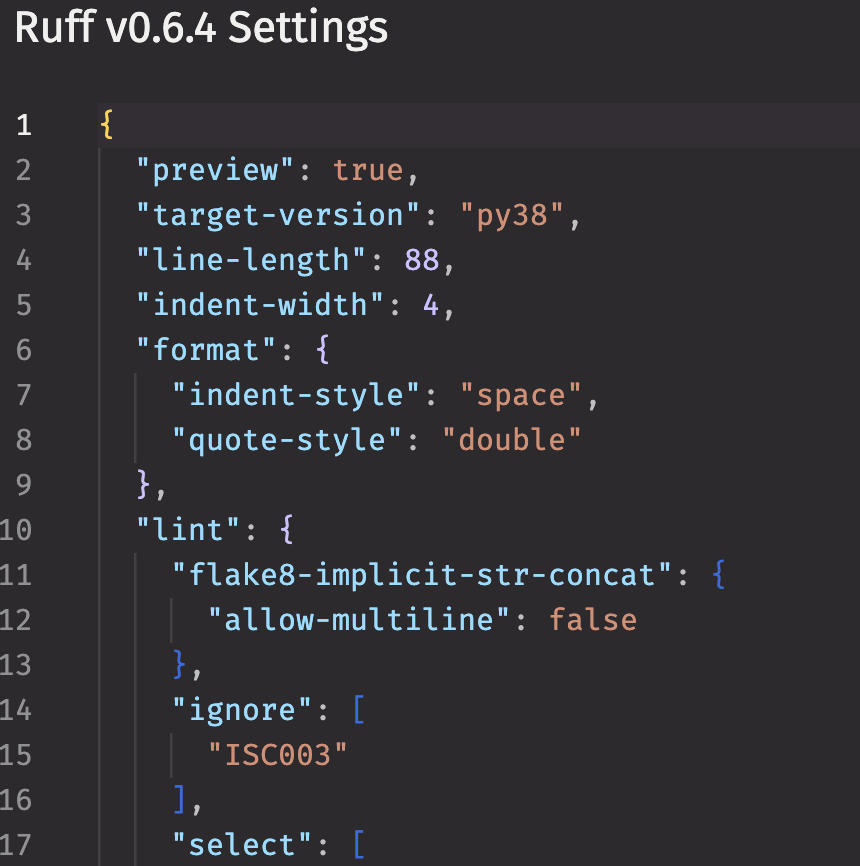
- Customizable settings, including an option to format a file every time it's saved:
Check out the video below, which shows a demo of the new Python linter at 13:55.
Support for Arrow Flight SQL
Deephaven now supports Arrow Flight SQL, a protocol for interacting with SQL databases using the Arrow in-memory format and the Flight RPC framework. You can use it to query SQL databases and other data sources that support Arrow Flight SQL.
Python TableDataService API
The new Python TableDataService API simplifies how the engine consumes data served by a remote service or database. It enables users to provide external data to Deephaven in the form of PyArrow tables, which can back Deephaven tables in both static and refreshing contexts.
See the expandable code blocks below for an example implementation.
A Table Data Service backend implementation
Usage of the example Table Data Service backend
Adding data to the table
Read and write Parquet to and from GCS
You can now read and write Parquet files to and from Google Cloud Storage (GCS) with Deephaven. Try it for yourself:
Additional new features
- A new function,
add_only_to_blink, converts an add-only table to a blink table. - The
slicetable operation is now available in the Python client API. - Deephaven now permits recomputing a formula whenever a row is modified without considering input columns.
- Multi-column support for both
rolling_formulaandagg.formula. - The ability to specify AWS / S3 credentials in a way that allows Deephaven to own the client-building logic when building Iceberg catalog adapters.
- Support for all
java.lang.Mathoperations in the query language. - The ability to specify an AWS profile through S3 instructions.
- Multi-join support in the Python client.
- The ability to infer the correct column types when converting a Pandas DataFrame to a Deephaven table.
- A static getter method to see the resultant table definition of a read operation in the server-side Groovy API.
Improvements
Major updates to our Iceberg integration
The 0.35 release introduced Deephaven's Iceberg integration. These improvements include fixes, breaking changes, and new features. We cover all the related changes in this section. The 0.37 release greatly improves on our Iceberg API by adding support for:
- Refreshing Iceberg tables
- More types of Iceberg catalogs
- Writing to Iceberg
For starters, let's cover some of the breaking changes in the new API:
IcebergInstructionsis nowIcebergReadInstructions.- The
snapshotsmethod is no longer a part of theIcebergCatalogAdapterclass. Instead, it's part of the newIcebergTableAdapterclass.
The revamped API also includes some new features:
- Classes
IcebergTableAdapter: An interface for interacting with Iceberg tables. Enables fetching snapshots, table definitions, and Iceberg tables.IcebergUpdateMode: Supports three different update modes: static, manually refreshing, and auto-refreshing Iceberg tables.IcebergTable: An extension of Deephaven table with anupdatemethod for manually refreshing Iceberg tables.
- Methods
adapter: A generic Iceberg catalog adapter that supports various Iceberg catalog types through a dict of properties.
Here's a list of catalog types supported by Deephaven. Previously, only the first two were supported:
- Rest
- AWS Glue
- JDBC
- Nessie
- Hive
- Hadoop
In addition, our S3 API has been revamped and improved. Read more about the revamped Iceberg API in our Iceberg user guide.
JavaScript API
The JavaScript (JS) API was majorly overhauled in this release. Some of the improvements include:
- The client can now connect over a WebSocket instead of deriving the connection info by inspecting the window location.
- Various improvements for third-party consumers, including:
- Zero browser dependencies
- Multiple module types, namely ES and CommonJS
Client APIs
- The Python client API now supports PyArrow date64 and time64 data types.
- A new general way to bind objects to Python client sessions has been added.
Additional improvements
- You can now provide a custom table definition when reading Parquet data with metadata files.
- Asynchronous add and delete methods for input tables.
- Hovering over a column in the UI now shows the count of each unique value in the column.
- Deephaven now has API-level Protobuf documentation.
- Two new configuration options when starting a server have been added:
http2.maxConcurrentStreams: The number of streams to allow for a maximum given http2 connection.http2.maxHeaderRequestSize: The maximum number of bytes to allow in HTTP request headers.
- The Barrage viewport protocol has been simplified, making table updates smoother.
- The Python and Groovy versions used by a Deephaven server are now exposed to client APIs.
Breaking changes
General
- Deephaven Community Core's protocol buffer definitions have moved to a new folder.
Server-side APIs
- A
MultiJoinTable(the output of amulti_join) changedtablefrom a method to an attribute to get the underlying table. - Business calendar time ranges are now exclusive at the close point. They were previously inclusive.
SeekableChannelsProviderLoader.fromServiceLoaderhas been removed and replaced withSeekableChannelsProviderLoader.load.DataInstructionsProviderLoader.fromServiceLoaderhas been removed and replaced withDataInstructionsProviderLoader.load.IcebertTableParquetLocationKeyhas a new parameter:SeekableChannelsProvider.
Client-side APIs
Python client
- NumPy is now a required dependency for the Python client API.
Bug fixes
Server-side APIs
General
- Fixed an issue where rolling up a blink table could cause some rows to improperly update their values.
- Expanding rows in hierarchical tables now works as expected when applied to rows past the first page of data.
- Static aggregations remap names correctly when a data index uses a different name for key column(s).
- Plotting a partitioned table transform done with
one_clicknow works as expected. - A bug that broke rollup table snapshots with viewports of more than 512 rows has been fixed.
- Deephaven's Parquet integration now properly handles both empty Parquet files and Parquet files with empty row groups.
- Number formatting in tables now works as expected.
- Fixed an issue that incorrectly reported null values in quick filters from the UI.
- A bug has been fixed that could cause a natural join operation to be slow when the right table is static.
- Fixed a time range off-by-one error in the time API.
Python
time_windownow works when running Deephaven from Python and Jupyter.- Partial user-defined functions (UDFs) now work as expected when called in table operations.
- Type inferencing now works on UDFs in table operations that call C++ wrapped with pybind11.
- deephaven.ui now supports columns of type
java.time.LocalTime. - The embedded Python server (pip-installed Deephaven) now shuts down JVM threads when it's able to, thus reducing the chances of errors and crashes.
Groovy
- Fixed an issue where
wouldMatchcould be memoized incorrectly, leading to incorrect results.
User interface
Client APIs
JS client API
- The JS API was found to reference two undefined tickets, which could cause errors. This has been fixed.
- Rollup tables created through the JS API (or directly) no longer error when there is a null sentinel.
- Fixed a JS TypeError that occurs when the server shuts down, which prevented shutdown events from being sent to listeners.
- The JS API now correctly handles redirected modifies.
- Fixed an issue that could cause ticking charts to not update when the data changes.
- Fixed an issue where an error could be incorrectly thrown when adding groups to a rollup table.
C++ client API
- Fixed an issue that caused the build to fail on Windows systems.
- Fixed an issue in some error messages that didn't separate line numbers and error codes.
- The API now correctly processes NULL conventions for types with an underlying
int64representation.
Reach out
Our Slack community continues to grow! Join us there for updates and help with your queries.