rollup
The Deephaven rollup method creates a rollup table from a source table with zero or more aggregations and zero or more grouping columns to create a hierarchy.
Syntax
Parameters
| Parameter | Type | Description |
|---|---|---|
| aggs | list[Aggregation] | A list of aggregations. If The following aggregations are supported: |
| by | list[str] | Zero or more column names to group on and create a hierarchy from. If |
| include_constituents optional | bool | Whether or not to include constituent rows at the leaf level. Default is False. |
Methods
Instance
with_filters(filters...)- Create a new rollup table that applies a set of filters to thegroupByColumnsof the rollup table.with_update_view(columns...)- Create a new rollup table that applies a set ofupdate_viewoperations to thegroupByColumnsof the rollup table.node_operation_recorder(nodeType)- Get arecorderfor per-node operations to apply during snapshots of the requestedNodeType.with_node_operations(recorders...)- Create a new rollup table that applies therecordedoperations to nodes when gathering snapshots.
Returns
A rollup table.
Examples
The following example creates two rollup tables from a source table of insurance expense data. The first performs no aggregations, but creates a hierarchy from the region and age columns. The second performs two aggregations: the aggregated average of the bmi and expenses columns are calculated, then the same by columns are given as the first. The optional argument include_constituents is set to True so that members of the lowest-level nodes (individual cells) can be expanded.
Similar to the previous example, this example creates a rollup table from a source table of insurance expense data. However, this time we are filtering on the source table before applying the rollup using with_filters. Both group and constituent columns can be used in the filter, while aggregation columns cannot.
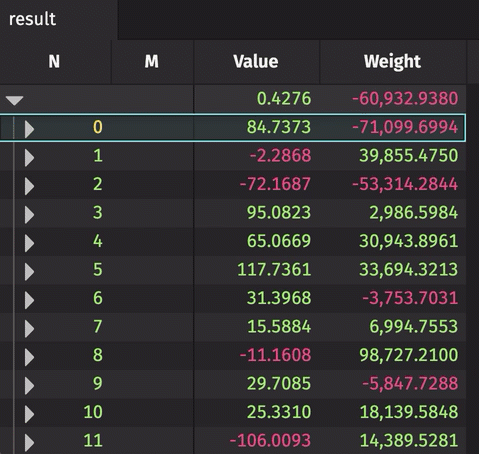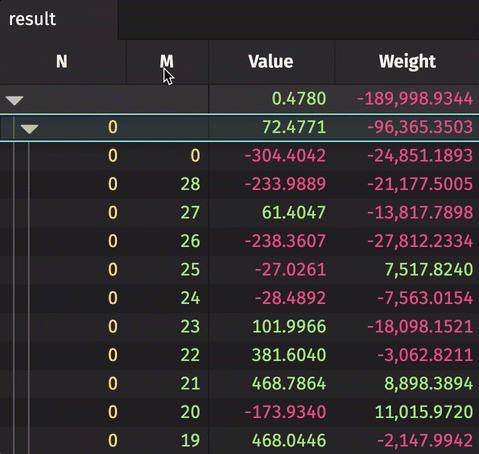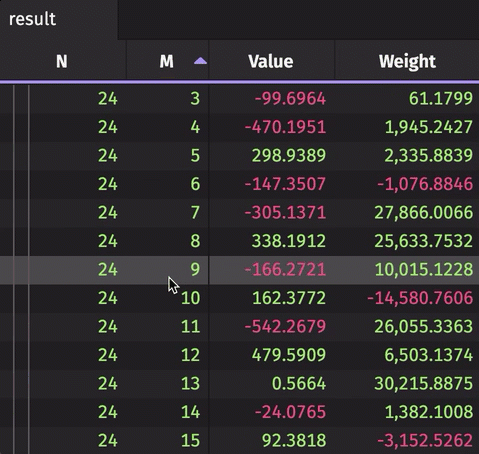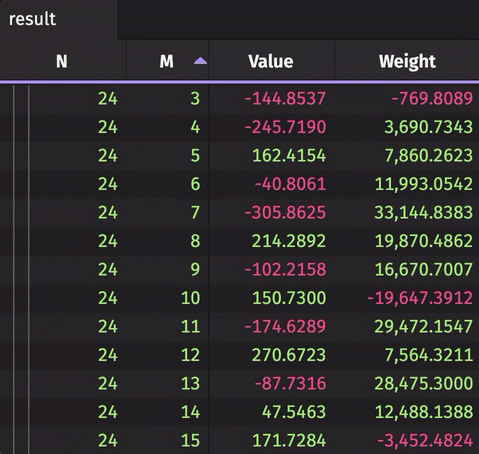
The following example creates a rollup table from real-time source data. The source data updates 10,000 times per second. The result rollup table can be expanded by the N column to show unique values of M for each N. The aggregated average and sum are calculated for the Value and Weight, respectively.