

Previously, we introduced the Deephaven R client - a brand new, first-in-class R package that marries Deephaven's real-time power with R's vast ecosystem of data analysis tools. Since then, we've put a ton of effort into expanding the API to bring you all the power of real-time table operations.
You can now create and execute queries on live Deephaven tables with a comfortable syntax. R has many packages that provide table operations, but only the Deephaven R client works on real-time data.
In this blog, you'll learn how to create ticking tables from RStudio and manipulate them with common table operations. Then, we'll create some snapshot-based real-time plots with ggplot2, one of R's most popular plotting libraries.
Deephaven Table Operations
Simple table operations like subsetting rows and columns, computing summary statistics, and joining multiple tables are the basis of any data toolkit. These operations enable you to manipulate data into a form that is easy to visualize, summarize, model, and present. R has many packages that provide such table operations, but none are made to work on real-time tables except for the Deephaven R client. We've minimized the work required to write complex queries by composing table operations for real-time data, such that all of the resulting downstream tables are still real-time, and update in lock-step with the parent tables. So, summary statistics of columns will update when the original columns receive more data, joined tables will grow when more data rolls into the parent tables, and so on. This makes advanced analysis on ticking data intuitive, all the while ensuring that your results always stay up-to-date. Let's look at a simple example.
An example of live table operations
We'll break this example down into five steps:
- Installing the R client and starting a Deephaven server.
- Connecting to the server.
- Creating a ticking table on the server.
- Applying aggregations and formulae to live data.
- Real-time plots with popular libraries.
Installing the R client and starting a Deephaven server
To get started, you'll need to install the Deephaven R client. The source code and installation instructions can be found in the GitHub repo. The current client must be built from source. While the RStudio IDE is recommended for this tutorial, you can use any appropriate IDE. You will also need a running Deephaven server. We'll assume that your server is running on localhost:10000 for the remainder of this post.
Then, fire up an R IDE and import the Deephaven client, called rdeephaven. We'll also import ggplot2 and ggpubr for plotting.
Connecting to the server
The Deephaven client uses a Client object to establish and maintain a server connection. A Client object can be instantiated by calling new() with the arguments needed to connect to the server. Deephaven servers, by default, use pre-shared key authentication, so we need to call Client$new() with the appropriate authentication arguments. The Deephaven server can be started with any custom authentication key, replace "YOUR_PASSWORD_HERE" with an authentication key of your choosing. So, I will connect to the server as follows:
Creating a ticking table on the server
Now, we're going to use the time_table method from the R client to create ticking tables on the server. time_table takes an ISO-formatted string for the period of the ticking table, and an optional ISO-formatted string for the start time, which otherwise defaults to current system time. For this example, we will create a table that adds a new row every second.
Next, we'll use some of Deephaven's built-in Java methods to generate random samples from normal distributions. First, we randomly sample a mean from a list of three possible means, , , and . Then, we will use that mean to construct for each group with . Finally, we will draw a random sample from , and save it in a column called X. Here is the code:
normal_samples is a Deephaven TableHandle that references a ticking table on the server, so we can use it to demonstrate some of Deephaven's new ticking table operations.
Applying aggregations and formulae to live data
First, let's use Deephaven's update_by() method to perform rolling aggregations for each group. We can compute the rolling average of X grouped by the three different means with the uby_rolling_avg_tick() function. We'll use the previous 10 observations to compute the rolling average at each point, and name the resulting column XAvg10. When the rolling average has fewer than 10 observations to use, as with the first 10 rows of the table, it will use all previous observations. Then, we'll use the new rolling average to compute the relative Z-score for each observation, and save those results in a column called Z.
In addition to the rolling average, let's compute the cumulative average. Doing so is as simple as counting the total number of observations in each group and dividing the group-wise cumulative sum by that count. Having the number of observations in each group also enables us to compute the cumulative standard error of the sample mean, so we will do that here as well.
Hopefully you can see how easy it is to perform complex table operations on ticking data with Deephaven. Now that we've calculated all of these statistics, let's do some real-time data visualization!
Real-time plots with popular libraries
Deephaven TableHandles are references to ticking tables on the server that can easily be converted to R data frames. Deriving data frames from Deephaven tables in this way ensures that the data frames will have the most up-to-date data from the server when they're created. Since all of R's plotting libraries use data frames to create their plots, and data frames derived from TableHandles represent the latest snapshot of available data when they're created, we get snapshot-based real-time plotting for free, with zero additional syntax needed to handle the real-time case. Let's see this in action.
We use ggplot2 to create three plots that allow us to visualize the data and all of the summary statistics we've computed. The three code blocks are shown first, followed by all three plots.
First, we create a custom theme to use with all of our plots to reduce code repetition. This is not a necessary step, but yields the aesthetics we were looking for.
First, let's plot kernel density estimates for each group of data. We have three groups defined by three unique values of , so we group everything by MEAN and call the corresponding groups Group A, Group B, and Group C. We also include three dashed lines to visualize the three unique values of .
Next, we make a scatter plot of the data for each group, and overlay a line to indicate the 10-sample rolling average.
Finally, we plot the cumulative average for each group, and use the calculated standard error to create cumulative 95% confidence bands. By the law of large numbers, the cumulative average lines will converge to the true mean value for that group.
We can use the ggarrange() function from the ggpubr library to collect these plots into one plot.
Here are the results:
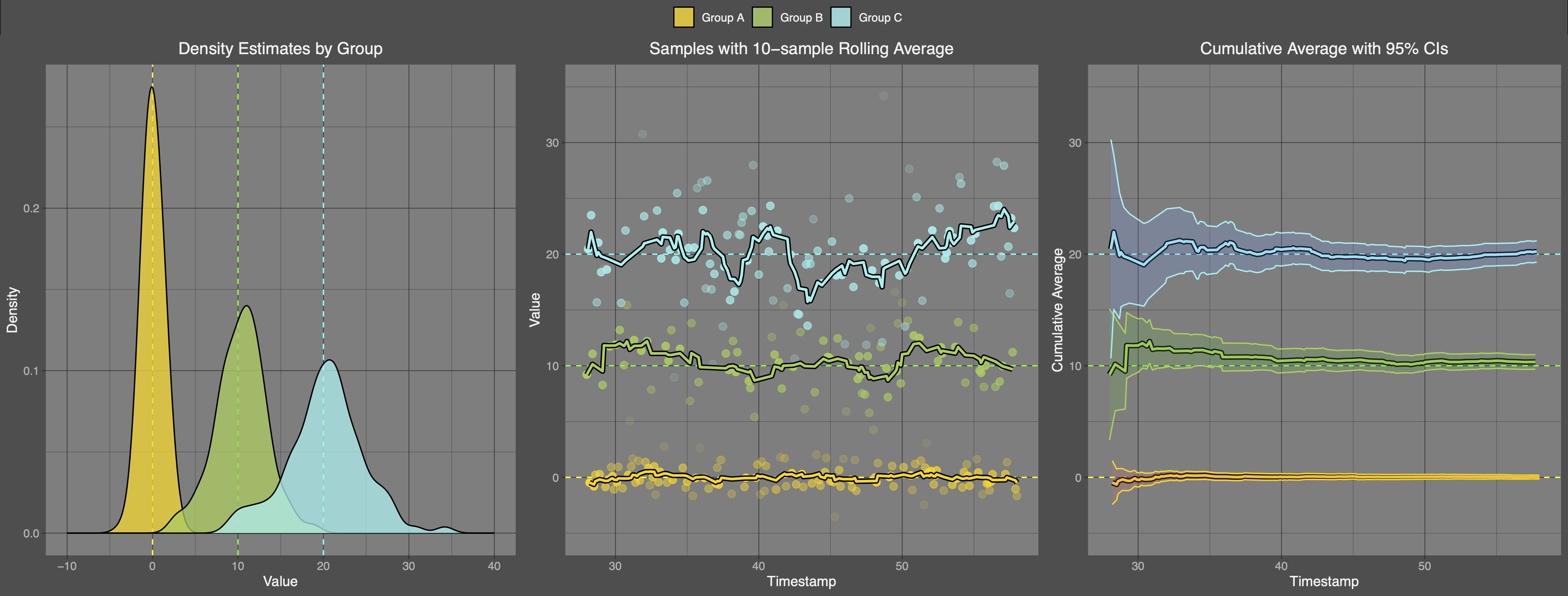
Beautiful!
The coolest part about this is that all of the plotting code is completely Deephaven-free, and the plots know nothing about the fact that the tables they're created from are ticking. So, you don't need to learn a special new syntax to make them work; you can use whatever library you're comfortable with.
If you collect the plot creation into a function and call it several times, you will see that each time these plots are created, they provide a snapshot of the most up-to-date data from the server. Of course, the table operations can also be collected into a single call, so here is a script that ties everything together, and makes three calls to our plots at the end to demonstrate their keeping up with server data.
Expand for the full code block
Running this script produces the following plot (sped up 3x for effect):
This gives us a great way to watch our data evolve in real time, without the need for additional infrastructure around creating the plots. Note that this is not an automatically updating plot, but the data that the plot is derived from does automatically update. So, simply calling the plotting code in a loop is sufficient to give the impression of ticking data, even though the R client can only ever retrieve snapshots of the latest server updates and convert them to static R objects.
Takeaways
The Deephaven R client provides a unique and robust solution for seamlessly integrating real-time data into your R workflows. By offering a straightforward way to interface with static and ticking tables and perform complex table operations, it empowers data scientists and analysts to harness the power of real-time data without leaving their familiar R environment. Whether you need to analyze financial data, monitor IoT devices, or visualize live metrics, the Deephaven R client has you covered.
Note
Try the Deephaven R Client To get started using the Deephaven R client, visit the R Client README, and feel free to reach out to us on our community Slack if you have any questions. Start leveraging the full potential of real-time data in R today!