Release notes for Deephaven version 0.35
A much-anticipated release with big features
June 28 2024

Deephaven Community Core version 0.35.0 was recently released. This release was the culmination of many big plans coming together. It includes a number of new features, improvements, breaking changes, and bug fixes. Without further ado, let's dive in.
New features
Apache Iceberg integration
We've been working on our Iceberg integration for a while now, and it's finally here! Iceberg is a high-performance format for huge analytic tables, similar to Deephaven. The new interface allows you to get Iceberg namespaces, read Iceberg tables into Deephaven tables, get information on snapshots of Iceberg tables, and obtain all available tables in an Iceberg namespace.
Below is an example of this integration in action.
For a demonstration of this feature from both Groovy and Python, check out the developer demo.
JSON schema specification
This release includes a new way for users to specify the schema of JSON messages. Through a declarative JSON configuration object, you can tell the engine about the nature of your JSON data before you ingest it, thus improving performance. You can specify things like:
- Allowing null values in fields.
- What to do if a field is missing.
- Ensuring numeric values are parsable from a string.
This work is part of a larger effort to make data ingestion in Deephaven faster and easier than ever. Look out for more data I/O features and updates in future releases.
New Period and Duration arithmetic
Deephaven's date-time interface now allows adding Periods and Durations together, as well as multiplying them by integer values. This is a nice ease-of-use feature when you want to create, offset, or bucket date-time data. For instance, this is now possible:
See Time in Deephaven to learn more about working with date-time data in Deephaven.
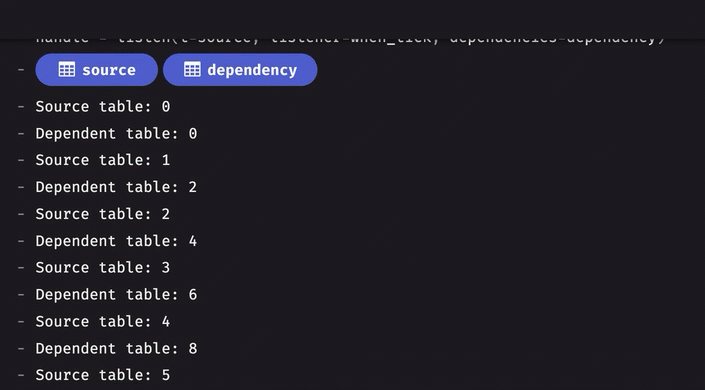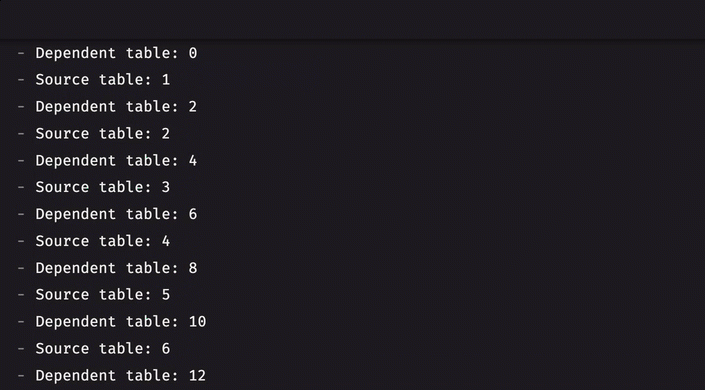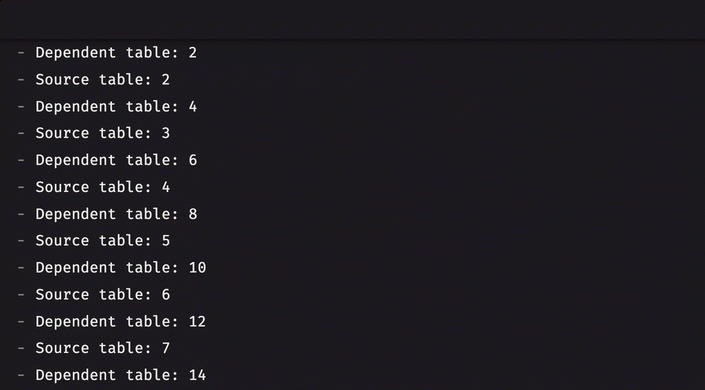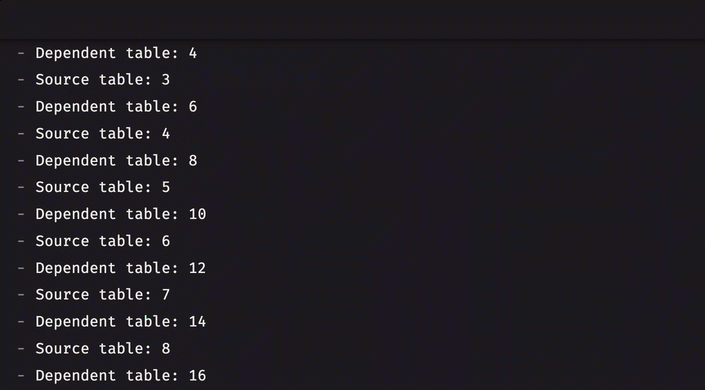
Table listeners with dependencies
The table listener interface now supports dependent tables. When one or more dependent tables are given, the engine will ensure that all processing for those table(s) is finished before the listener is called.
For example, consider two tables, A and B, that tick simultaneously. By specifying B as a dependent table when listening to A, you ensure the engine has finished updating B before the listener listens to A. Previously, this was not guaranteed, meaning the listener could have been called before B had updated. This is now guaranteed, paving the way for a true multi-table listener (planned for version 0.36.0).
Improvements
Parquet
- Performance improvements when fetching large partitioned Parquet datasets from S3. The API now internally fetches Parquet footer metadata in parallel, greatly improving bootstrapping performance for Parquet-backed partitioned datasets.
- Multiple optimizations for Parquet reads, leading to faster performance and significantly lower memory utilization.
Server-side APIs
DataIndexis more parallelizable.- Improved logging for recursively deleting files through
FileUtils.deleteRecursively. TimeUnitconversion onInstantandDateTimecolumns are now supported.- The built-in query language Numeric class properly supports null values as both input and output, as many of the other built-in libraries do.
- Improved logging in table replayers.
Client APIs
- The Java client now supports column headers of all primitive array types, not just
byte[].
Breaking changes
These breaking changes are improvements to APIs that may break existing code for our users. As such, they are listed separately.
Consistent and widened return values
Aggregation operations in query library functions were previously inconsistent in their return types. They are now consistent:
percentilereturns the primitive type.sumreturns a widened type ofdoublefor floating point inputs orlongfor integer inputs.productreturns a widened type ofdoublefor floating point inputs orlongfor integer inputs.cumsumreturns a widened type ofdouble[]for floating point inputs orlong[]for integer inputs.cumprodreturns a widened type ofdouble[]for floating point inputs orlong[]for integer inputs.wsumreturns a widened type oflongfor all integer inputs anddoublefor inputs containing floating points.
Additionally, the following update_by operations now return double values when used on float columns:
Out with DataColumns, in with ColumnVectors
This release retires DataColumns and replaces them with ColumnVectors, which are more efficient than their predecessors. It also paves the way for native iteration over table data directly from Python without the need for conversion to any other data structure.
Parquet
Our Parquet read and write APIs have been refactored to improve ease of use and performance. This may break queries that use Parquet as a data source. Breaking Parquet changes include:
- Methods no longer accept File objects, but instead accept String objects. They also no longer accept TableDefinition objects but instructions for the definition. A new instruction for the Parquet file layout has been added. It replaces APIs with layout names in the method name with a single call with inputs specifying layout parameters.
- New instructions are available that provide index columns for writing. This is now the default approach when writing to Parquet.
- The Python API no longer uses the
col_definitionargument. It has been replaced with an optionaltable_definitionargument for reading and writing. If not specified, the definition is derived from the table being written. - The
regionparameter is no longer required when reading Parquet data from S3. If not provided, the AWS SDK will pick it up. An error will be thrown if the region cannot be found in system properties, environment variables, config files, or the EC2 metadata service.
NumPy version 2.0
Deephaven now uses NumPy version 2.0 as its default version. This may break some queries that leverage NumPy. See the linked NumPy release notes for a full list of what's new and different about the latest version of NumPy.
pip-installed Deephaven
If you use pip-installed Deephaven, be sure to have Python version 3.8 or later. With this release, we've bumped the required Python version from 3.7 to 3.8.
Python dtypes
The deephaven.dtypes module had several data types removed to prevent confusion for users. The following data types no longer exist:
int_float_int_arrayfloat_array
Equivalent data types already existed in the module for the ones removed. They align with NumPy data types. They are:
int64float64int64_arrayfloat64_aray
Built-in date-time methods
Some deprecated methods were removed from the DateTimeUtils class. These methods did not properly account for daylight savings events, whereas the new methods do. The new methods now include a third boolean parameter to properly account for local time:
nanosOfDay(Instant, ZoneId, boolean)millisOfDay(Instant, ZoneId, boolean)secondOfDay(Instant, ZoneId, boolean)minuteOfDay(Instant, ZoneId, boolean)hourOfDay(Instant, ZoneId, boolean)
A value of True means the local date-time is returned, and False ignores daylight savings time. As mentioned above, many of the built-in date-time operations now also support the LocalDateTime class, so you can use that as well.
Bug fixes
Server-side APIs: general
- Fixed an issue where a
DataIndexcould cause a null pointer exception. DataIndexobjects will no longer be created without the appropriate column sources.- Fixed an issue where a downsampling operation could cause an error while processing an update.
- Fixed an issue that could cause a
ClassCastExceptionon empty primitive arrays. - Fixed an issue when filtering by Date on an uncoalesced table.
- Fixed an issue where Deephaven could cause a web browser to consume large amounts of memory. This primarily benefits users of Safari.
- The Deephaven JS API is now fully and properly self-contained.
- Objects that are soft-referenced in heap memory are now properly reclaimed.
- Fixed an issue that could cause unwanted integer value truncation.
- Table replayers should no longer cause UpdateGraph errors.
- Fixed a deadlock issue caused by input tables.
- Equality filters now work on arbitrary Java objects such as LocalDate and Color.
- Leaked memory from released objects has been greatly reduced.
Server-side APIs: Python
- Deephaven's Arrow integration now properly handles
LocalDateandLocalTimedata. - Fixed an issue in pip-installed Deephaven where an
updatecould cause a JavaNoSuchFileException. - Fixed an issue when specifying JVM arguments in pip-installed Deephaven. This will no longer change default parameters.
- Fixed an operating system incompatibility between pip-installed Deephaven and Windows.
User interface
- Fixed an issue where a null value retrieved from a table did not match what is seen in the console.
- The File Explorer in the Deephaven UI should no longer show invalid filename errors on Windows.
- The UI will no longer incorrectly pad zeros onto subsecond timestamps.
Parquet
- Fixed an issue that occasionally caused a race condition and null pointer exception when reading Parquet from S3.
- Fixed an issue where excessive memory was used when reading a column from a Parquet file with a single page.
- Large custom fragment sizes when reading Parquet from S3 will no longer cause out-of-memory errors.
Client APIs
- Worker-to-worker subscriptions to uncoalesced tables now automatically coalesce them.
Reach out
Our Slack community continues to grow! Join us there for updates and help with your queries.