Release Notes for Deephaven Version 0.20.0
Server and UI enhancements
January 23 2023

Deephaven continues to roll out features to enhance your productivity with dynamic data. Highlights of version 0.20.0 include hierarchical tables, new methods in the Python Table API, re-engineered table snapshotting, and a slick column grouping feature made available in the Web UI. Full 0.20.0 release notes can be found on GitHub.
Python users: Input tables, an Arrow module, and a pandas-Jupyter viewer
Input tables
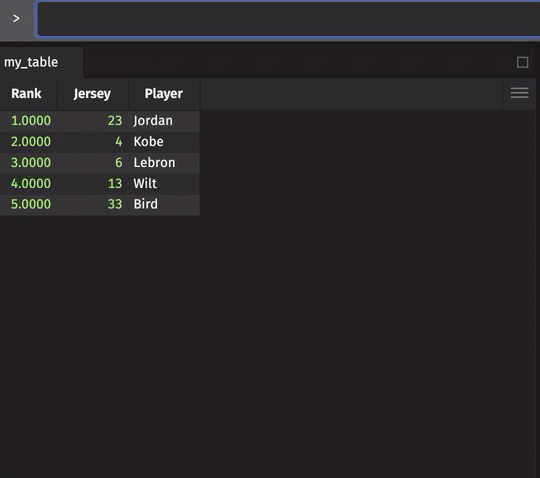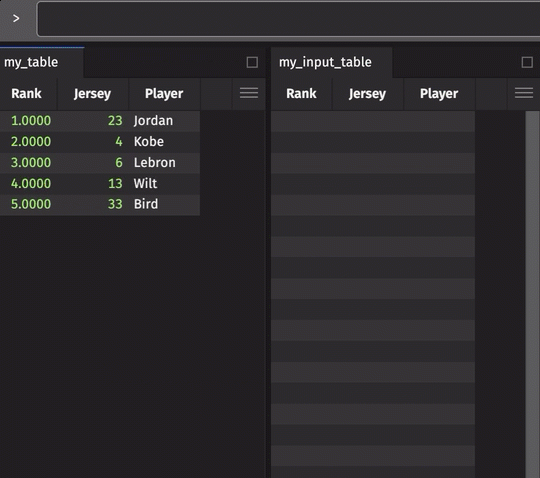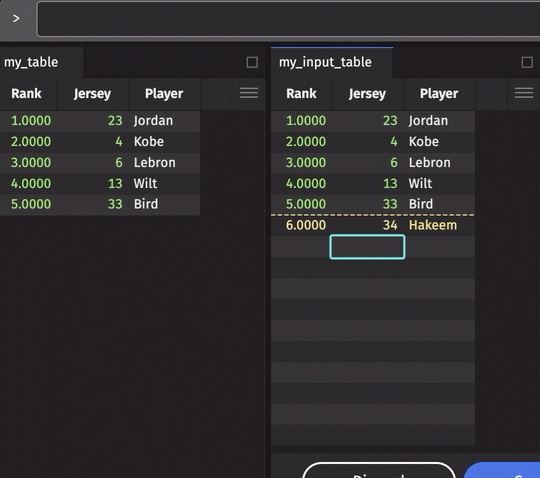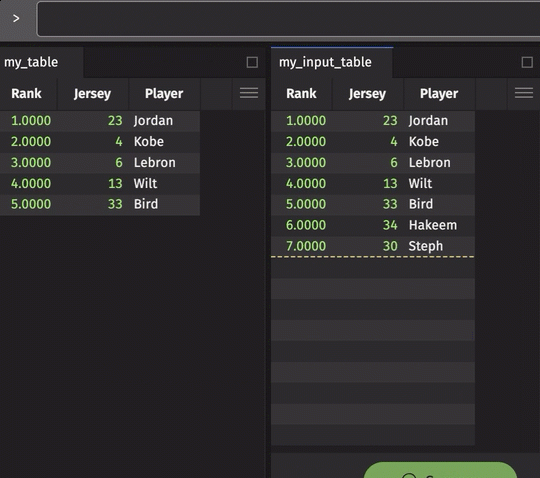
From a Python IDE or via app-mode, one can create or embed an interface for inputting table data manually via the GUI (with or without keys). Under the covers, this data is treated as first-class table data that can then be joined with other Deephaven tables to support a myriad of use cases. Here is an example:
An Arrow module
A new Arrow module allows two-way conversion between a PyArrow table and Deephaven table. This module is one of the foundational building blocks for more Arrow integration features in the future. Specifically, the next release will provide integrations with TurbODBC, a popular adapter for accessing relational databases, and ADBC, a lean database client API based on Arrow.
Pandas dataframe viewer in Jupyter
Deephaven’s table widgets allow you to interact with Deephaven tables and pandas DataFrames. They’re well-featured and easy to use, enabling you to
- scroll on multi-billion row tables
- see dynamic and ticking data in real time
- filter, sort, and project columns via the interface
- and use search and go-to features.
With this release, the interactive table widget now works with pandas DataFrames in Jupyter. This means you can inherit the identical interactive experience with Deephaven tables and pandas DataFrames in either the Deephaven web UI or Jupyter.
Hierarchical views that update in real time
The release of the partitioned_table method in v.0.19.0 opened many exciting patterns of development. Here’s one: Now, you can launch tree tables and aggregated roll-up views in the UI. These interfaces empower you to dig in, and - best of all - these views update in real time as new data flows in.
Column grouping: slick visualization
You can now package columns in the UI into groups. This provides you with a nice dimension for labeling, as well as real ease-of-use for dragging complementary columns around. In a later release, we’ll provide the ability to collapse and expand column groups. Here is a script that creates Column Groups using layout hints, then a GIF that shows editing them via the UI.
Two new table operations
outerJoin
You can now do a leftOuterJoin on two tables, inheriting the superset of the keyed rows. The static example below demonstrates the use case. Remember, however, this method – like all Deephaven table operations – can be used on dynamic tables and will update as new data hits the backend. (This will be wrapped for Python in the next release.)
snapshot_when
Since Deephaven tables update, sometimes you’ll have use cases where you want to snapshot a table – to freeze it in time, so to speak. “Snapshots” are the way to do this. Oftentimes users snapshot a table before moving it to a library or client that is unable to handle real-time updates. For example, snapshotting a table before pushing it into a pandas or R DataFrame makes sense.
In this release, we have made snapshotting more fully featured and easy to use. The reference material and how-to guide explain how to create and utilize a mechanism that triggers a snapshot (of an updating table) at your desired frequency.
Further communication
The documentation enhancements blog discusses the changes to our user guide related to this release. We look forward to working with you on Deephaven’s Slack or GitHub Discussions.