read
The read method will read a single Parquet file, metadata file, or directory with a recognized layout into an in-memory table.
Syntax
Parameters
| Parameter | Type | Description |
|---|---|---|
| path | str | The file to load into a table. The file should exist and end with the |
| col_instructions optional | list[ColumnInstruction] | One or more optional |
| is_legacy_parquet optional | bool | Whether or not the Parquet data is legacy. |
| is_refreshing optional | bool | Whether or not the Parquet data represents a refreshing source. |
| file_layout optional | Optional[ParquetFileLayout] | The Parquet file layout. The default is |
| table_definition optional | Union[Dict[str, DType], List[Column], None] | The table definition. The default is |
| special_instructions optional | Optional[s3.S3Instructions] | Special instructions for reading Parquet files. Mostly used when reading from nonlocal filesystems, such as AWS S3 buckets. Default is |
Returns
A new in-memory table from a Parquet file, metadata file, or directory with a recognized layout.
Examples
Note
All but the final example in this document use data mounted in /data in Deephaven. For more information on the relation between this location in Deephaven and on your local file system, see Docker data volumes.
Single Parquet file
In this example, read is used to load the file /data/examples/Taxi/parquet/taxi.parquet into a Deephaven table.
Compression codec
In this example, read is used to load the file /data/output_GZIP.parquet, with GZIP compression, into a Deephaven table.
Caution
This file needs to exist for this example to work. To generate this file, see write.
Partitioned datasets
_metadata and/or _common_metadata files are occasionally present in partitioned datasets. These files can be used to load Parquet data sets more quickly. These files are specific to only certain frameworks and are not required to read the data into a Deephaven table.
_common_metadata: File containing schema information needed to load the whole dataset faster._metadata: File containing (1) complete relative pathnames to individual data files, and (2) column statistics, such as min, max, etc., for the individual data files.
Warning
For a directory of Parquet files, all sub-directories are also searched. Only files with a .parquet extension or _common_metadata and _metadata files should be located in these directories. All files ending with .parquet need the same schema.
Note
The following examples use data in Deephaven's example repository. Follow the instructions in Launch Deephaven from pre-built images to download and manage the example data.
In this example, read is used to load the directory /data/examples/Pems/parquet/pems into a Deephaven table.

Refreshing tables
The following example set demonstrates how to read refreshing Parquet files into Deephaven.
First, we create a Parquet table with write.
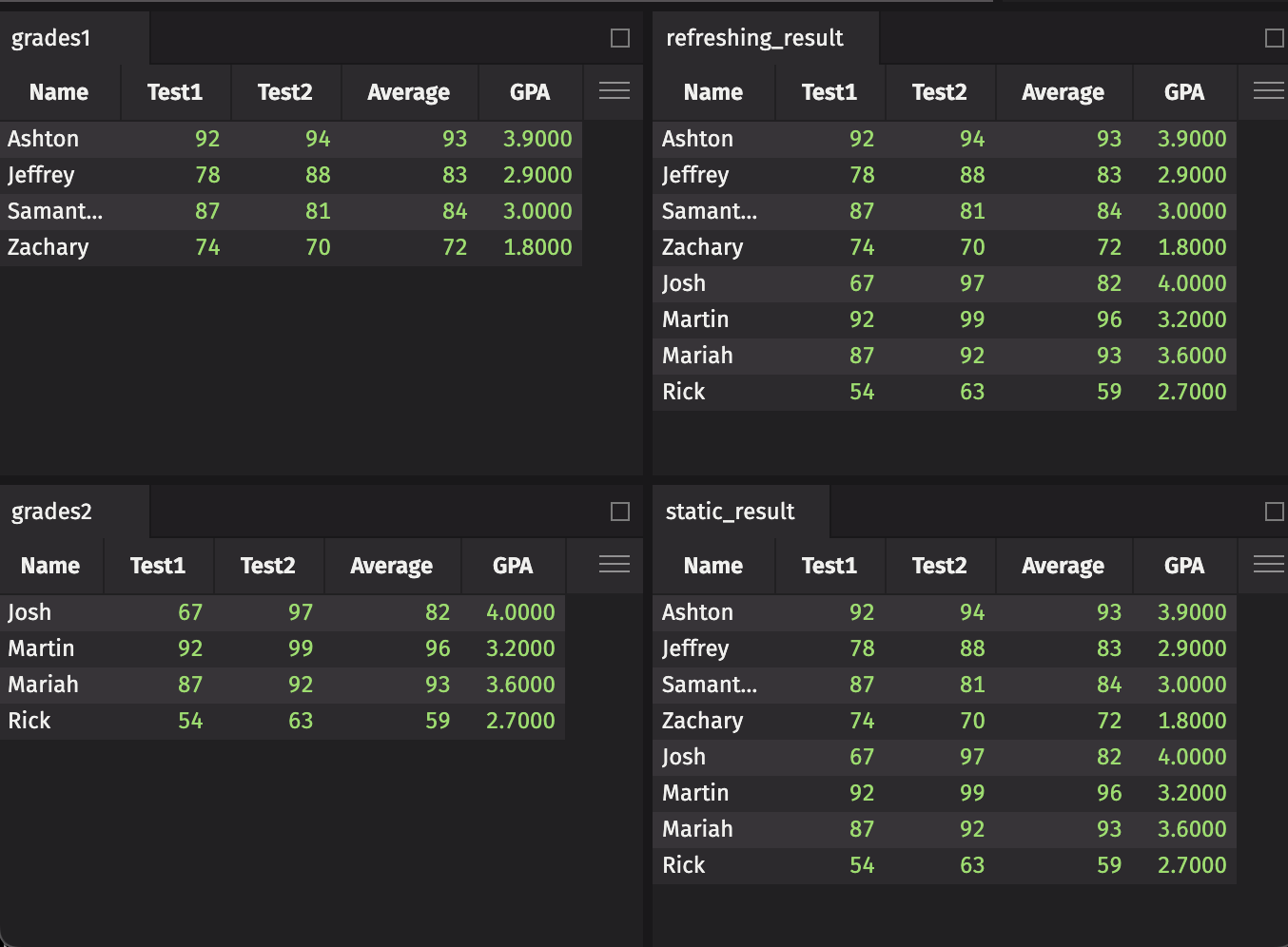
Next, we list our current partitions, and then create a new Deephaven table by using the read method.
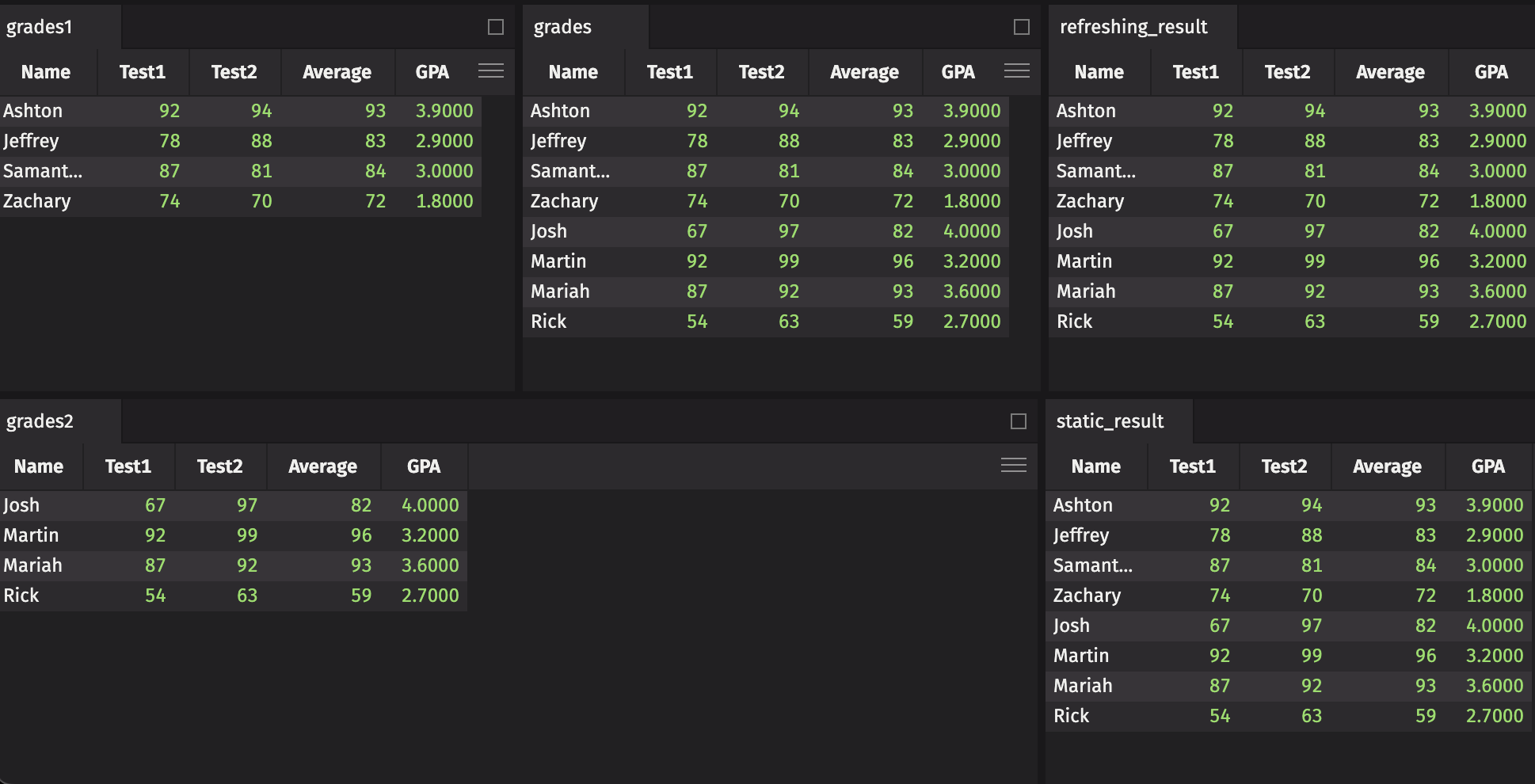
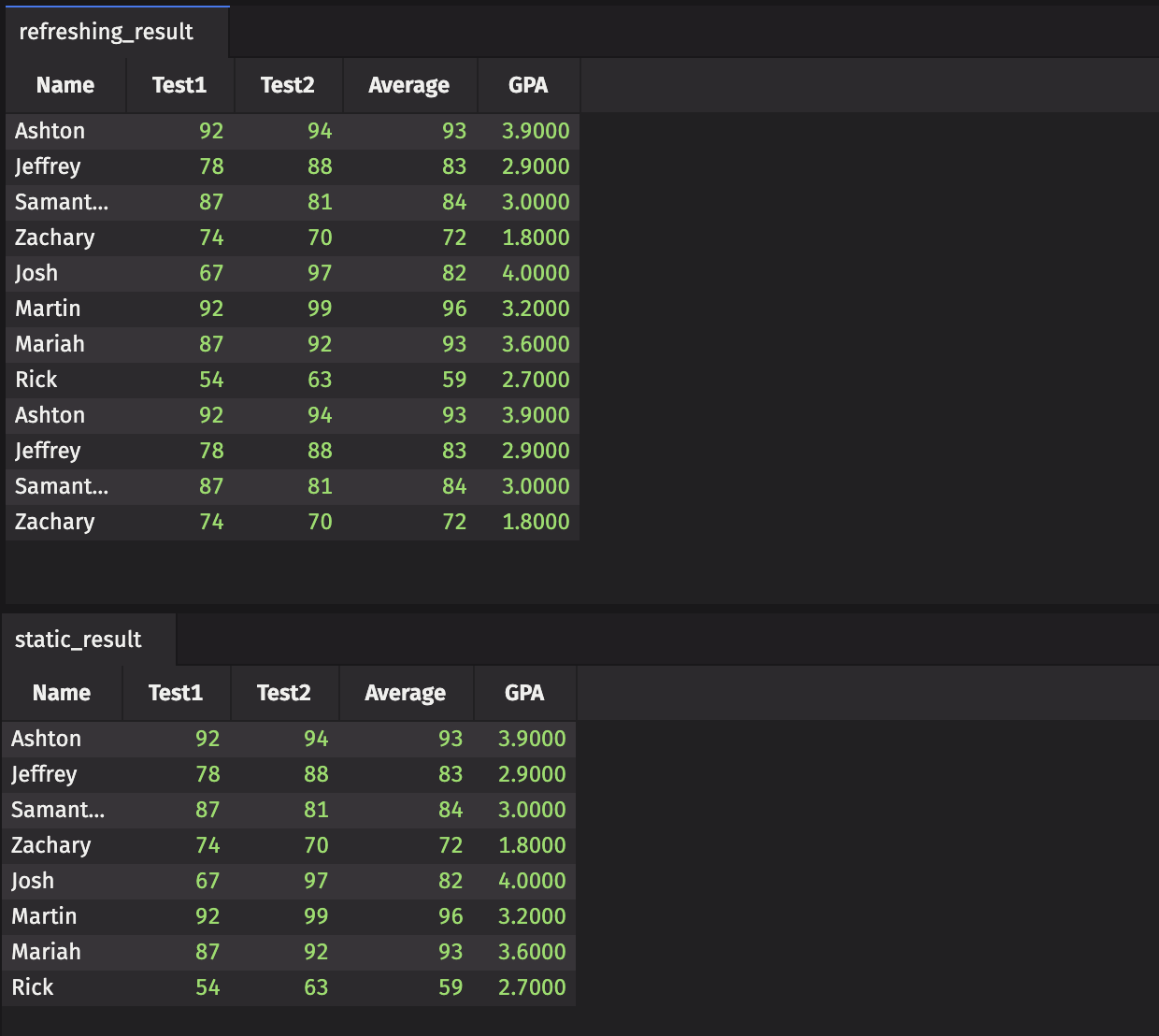
Finally, we create a third partition that is a copy of the first.
Read from a nonlocal filesystem
Deephaven currently supports reading Parquet files from your local filesystem and S3 storage. The following code block uses special instructions to read a public Parquet dataset from an S3 bucket.
When reading from AWS S3, you must always specify instructions for doing so via S3Instructions. The following input parameters can be used to construct these special instructions:
region_name: This parameter defines the region name of the AWS S3 bucket where the Parquet data exists. Ifregion_nameis not set, it is picked by the AWS SDK from 'aws.region' system property, "AWS_REGION" environment variable, the{user.home}/.aws/credentials or {user.home}/.aws/configfiles, or from EC2 metadata service, if running in EC2. If no region name is derived from the above chain or the region name derived is incorrect for the bucket accessed, the correct region name will be derived internally, at the cost of one additional request.max_concurrent_requests: The maximum number of concurrent requests to make to S3. The default is 50.read_ahead_count: The number of fragments that are asynchronously read ahead of the current fragment as the current fragment is being read. The default is 1.fragment_size: The maximum size of each fragment to read in bytes. The default is 5 MB.max_cache_size: The maximum number of fragments to cache in memory while reading. The default is 32.connection_timeout: The amount of time to wait for a successful S3 connection before timing out. The default is 2 seconds.read_timeout: The amount of time it takes to time out while reading a fragment. The default is 2 seconds.access_key_id: The access key for reading files. If set,secret_access_keymust also be set.secret_access_key: The secret access key for reading files.anonymous_access: A boolean indicating to use anonymous credentials. The default isFalse. If the default credentials fail, anonymous credentials are used.endpoint_override: The endpoint to connect to. The default isNone.
Additionally, the S3.maxFragmentSize configuration property can be set upon server startup. It sets the buffer size when reading Parquet from S3. The default is 5 MB. The buffer size should be set based on the largest expected fragment.