Release notes for Deephaven version 0.34
A big release for a wide audience
May 3 2024

The wait is over, and Deephaven Community Core version 0.34.0 is out. This is a big release with significant enhancements and new features. Are you ready to explore the latest updates? Let's dive in and discover what's new!
New features
Command line interface for pip-installed Deephaven
Do you run Deephaven from Python without Docker? If so, chances are it's because:
- You don't like Docker.
- You want to keep everything in Python.
- You like the Jupyter experience.
Well, we have good news. It just got even easier to start Deephaven from Python with the introduction of a new command line interface.
If you pip install Deephaven 0.34.0 or later via pip install deephaven-server, you can start a Deephaven server with a single deephaven command:
For more information about installing Deephaven with pip, see the pip install guide.
Use the Python client to ingest tables from remote servers
Have you ever wanted to use the Deephaven Python client from within a server? Now you can! Client tables can be made available for use in server-side queries. By running a Python client on a server, you can create and ingest tables from remote servers and use them in your own queries. This is exciting because:
- Distributing workloads across multiple Deephaven servers just got a lot easier.
- It leverages gRPC to support large and complex queries.
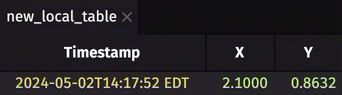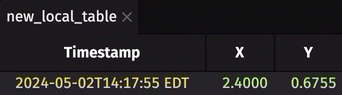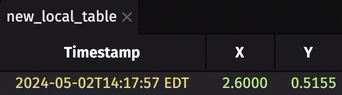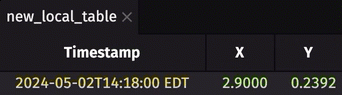
To demonstrate this new feature, consider the following configuration:
- You have a Deephaven server up and running with Python locally on port
10000. It has pydeephaven installed. - You have another server running locally on port
9999with anonymous authentication. You want to create a table on this other instance, and subscribe to it on the Deephaven server at port10000.
From the Deephaven server running on port 10000, run:
Parquet
Read partitioned Parquet datasets from AWS S3
In the 0.33 release, we added support to read single Parquet files from AWS S3. That has now been expanded to read partitioned datasets from S3. The best part? It's just as easy to do! Check out this code, which reads a folder of publicly available Parquet data from an S3 bucket directly into Deephaven as a table:
Write partitioned Parquet files and metadata files
You can now not only read these files into Deephaven tables, but also write them from Deephaven tables. The following code block writes a partitioned table to a partitioned Parquet dataset.
Data indexing for tables
A DataIndex allows users to improve speed of data access operations in a table. It applies to one or more indexed key columns. It's now available in the Python API through deephaven.experimental.data_index module. Sort, join, aggregation, and filter operations all benefit from this new feature.
Keep an eye out for additions to our documentation on this topic soon!
Built-in query library functions for array columns
Two new built-in query library functions, diff and rank have been added that can be used on array columns. They:
- Compute differences between values in an array.
- Rank values in an array.
The code block below uses these two on a table with an array column.
Improvements
Batch formula compilation
A core port of the Deephaven engine has been reworked to be significantly more performant when batching formulas together. For instance, the following code runs over 10x faster in 0.34.0 than it does in 0.33.3.
If you create tables with a lot of columns created from formulas, you'll see a noticeable difference.
Improved error messages
Error messages in Deephaven now contain the query string that caused them, which makes them more searchable and easier to understand.
Blink input tables in the Python client
Server-side APIs have been able to create blink input tables for some time, so it's about time the Python client caught up.
The C++ client now works on Windows
The Deephaven C++ client previously only worked on Linux distributions, but that is no longer the case! It can now be built on both Windows 10 and Windows 11. For full instructions on building on Windows, see here.
Null to NaN conversions for NumPy arrays
Users whose Deephaven queries leverage NumPy have likely converted a table with null values to a NumPy array, and found the null values to be frustrating to deal with. Deephaven now offers a helper function to convert those to NumPy NaN values, which are much easier to handle from Python.
Note
Before version 0.34.0, this conversion was done automatically for user-defined functions. That is no longer the case. For more information on this breaking change, see engine handling of type hints.
Simple date formatting in Python
A helper function, simple_date_format, has been added to the Python API. It makes date parsing easier in Python if your date-time data isn't in an ISO-8601 format:
Time of day methods properly handle daylight savings
New time of day methods have been added to the Deephaven Query Language. These new methods take an additional boolean value depending on the desired behavior with respect to daylight savings time. See secondOfDay as an example.
Warning
The older ___ofDay methods are considered deprecated moving forward and will be removed within the next few releases.
Time binning methods now accept durations
Popular time binning methods upperBin and lowerBin now accept Java Durations as bin size and offset. These methods work all the same as the ones that take an integer number of nanoseconds:
Ticking Python client on PyPi
pydeephaven-ticking, the Python client API that works with ticking data, is now available on PyPi!
Breaking changes
Engine handling of type hints
The NumPy null to NaN conversion is no longer done automatically for user-defined functions that use NumPy arrays in their type hints. Users now must perform this conversion if their data contains null values where NaN is correct, for instance when the data type in the array is np.double.
Additionally, the data types specified in type hints are checked against those used in the corresponding query string to ensure compatibility. If they are not, an error is thrown with information about any incompatibility. This ensures safe usage of type hints in functions called in query strings.
These breaking changes result user-defined functions being significantly more performant when called in query strings.
Other breaking changes
-
Parquet read/write Java APIs that used File objects have been replaced by ones that use strings instead.
-
The internal public class
io.deephaven.engine.table.impl.locations.local.KeyValuePartitionLayouthas been renamed toio.deephaven.engine.table.impl.locations.local.FileKeyValuePartitionLayout.
Bug fixes
-
Blink tables previously could not use the special variable row indices
i,ii, andk. This has been fixed, and these can all now be used in blink tables. -
In certain rare cases, the
ungroupoperation produced a null pointer exception where it shouldn't have. This has been fixed. -
FilterComparisonnow works with string literals:
-
A bug has been fixed that could cause searching for a value with the UI to not work as expected on sorted columns.
-
Arrays of Instant strings are now properly handled by deephaven.dtypes.instant_array.
-
Fixed a bug where duplicate headers could be passed between the ticking Python client and server, resulting in an error.
-
move_columnscould previously erroneously remove columns from tables. This has been fixed, and the method now inserts new columns at the specified locations without losing existing data. -
deephaven.pandas.to_pandas now supports the
numpy_nullableoption when the Pandas version is > 1.5.0.
Time zone conversions in Python now handle more cases. Previously, it was possible for time zone conversions from Python types to Java ZoneId types to throw errors when the conversion should have worked. This has been fixed.
- A bug in deephaven.learn was found that could cause null pointer exceptions; it has been fixed.
Other notable changes
Required Java version
If you run the embedded Deephaven server, it will raise an error on startup if your Java version is below a threshold:
- 11.0.17 for Java JDK 11.
- 17.0.5 for Java JDK 17.
The error will notify you that the outdated version is the cause.
Docker Compose v2
Deephaven officially supports Docker Compose v2 by default. All of the pre-built Docker Compose files we publish have been updated to use V2.
Reach out
Our Slack community continues to grow! Join us there for updates and help with your queries.