Deephaven's table types
Deephaven tables are the core data structures supporting Deephaven's static and streaming capabilities. Deephaven implements several specialized table types that differ in how streaming data is stored and processed in the engine, how the UI displays data to the user, and how some downstream operations behave. This document covers static tables, standard streaming tables, and the four specialized streaming table types: append-only, add-only, blink, and ring.
Table type summary
This guide discusses the unique properties of each of Deephaven's table types. The main points are summarized in the following table.
| Table type | Index-based ops, special variables | Consistent inter-cycle row ordering | Bounded memory usage | Inter-cycle data persistence |
|---|---|---|---|---|
| Static | ✅ | 🚫 | ❌ | 🚫 |
| Standard | ❌ | ❌ | ❌ | ✅ |
| Append-only | ✅ | ✅ | ❌ | ✅ |
| Add-only | ❌ | ❌ | ❌ | ✅ |
| Blink | ✅ | 🚫 | ✅ | ❌ |
| Ring | ❌ | ❌ | ✅ | ✅ |
The rest of this guide explores each of these table types, their properties, and the consequences of those properties.
Static tables
Static tables are the simplest types of Deephaven tables and are analogous to Pandas Dataframes, PyArrow Tables, and many other tabular representations of data. They represent data sources that do not update, and therefore do not support any of Deephaven's streaming capabilities.
Because static tables do not update, they have the following characteristics:
- Index-based operations are fully supported. The row indices of a static table always range from
0toN-1, so operations can depend on these values to be stable. - Operations that depend on or modify external state can be used with static tables. Stateful operations can present problems for some types of streaming tables.
- The use of special variables is fully supported. Deephaven's special variables
iandiirepresent row indices of a table asintorlongtypes, respectively. These variables are guaranteed to have consistent values in static tables.
Static tables can be created by reading from a static data source, such as CSV, Iceberg, Parquet, or SQL. Or, they can be created with Deephaven's table creation functions, like new_table or empty_table. This example uses empty_table to construct a static table:
Check whether a table is a static table with the is_refreshing property. This property will be False for static tables:
Any streaming table can be converted to a static table by taking a snapshot. This will produce a static copy of the streaming table at the moment in time the snapshot is taken:
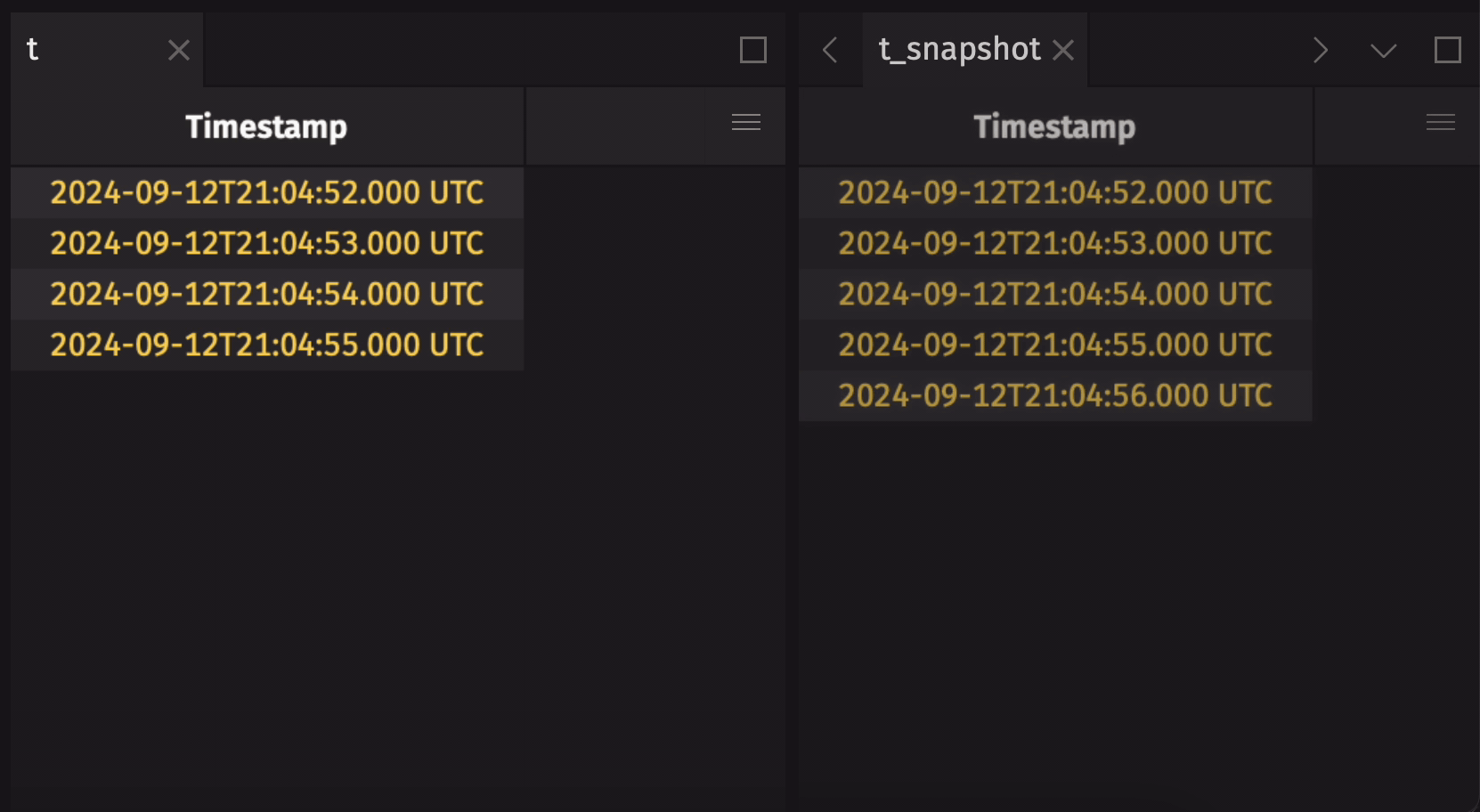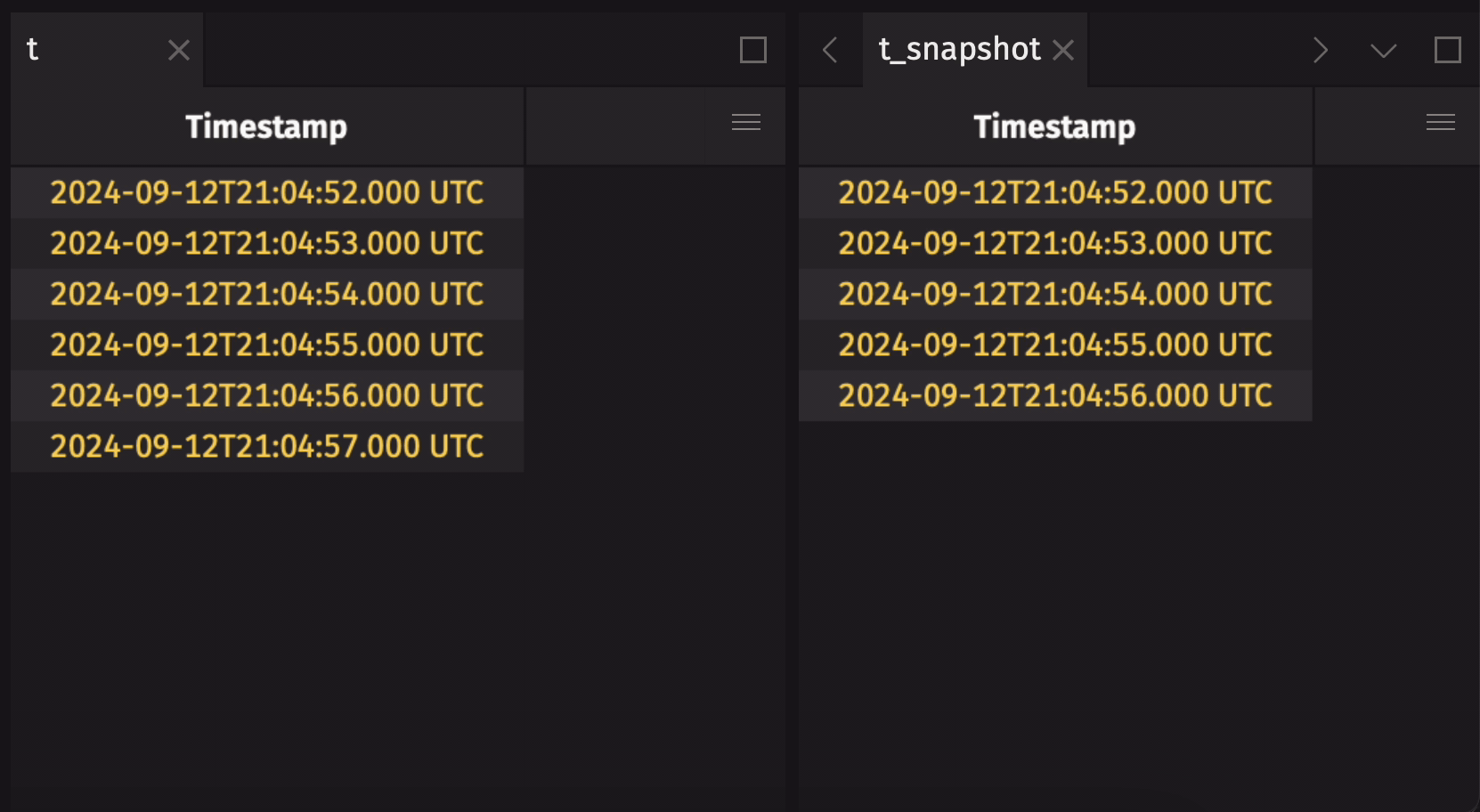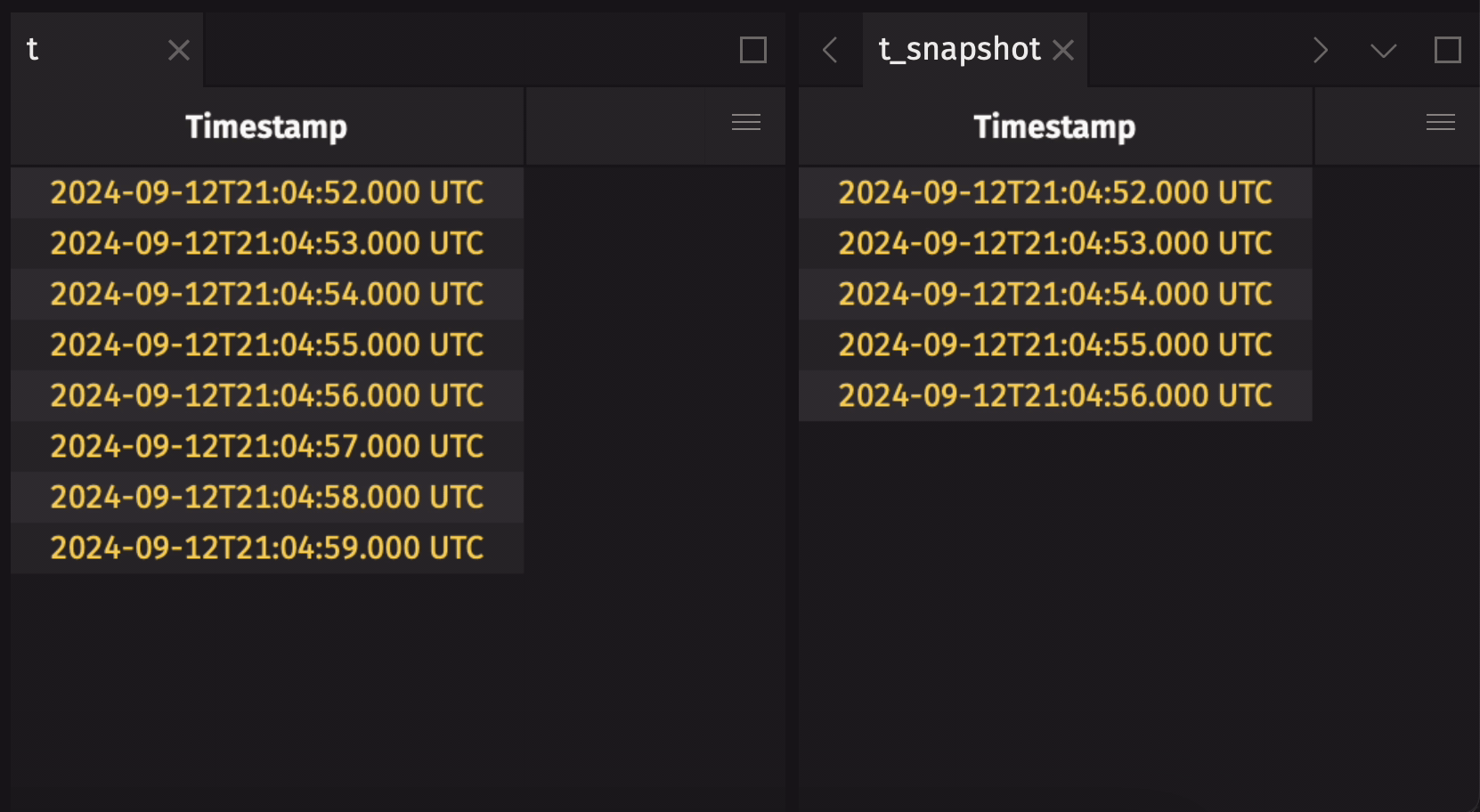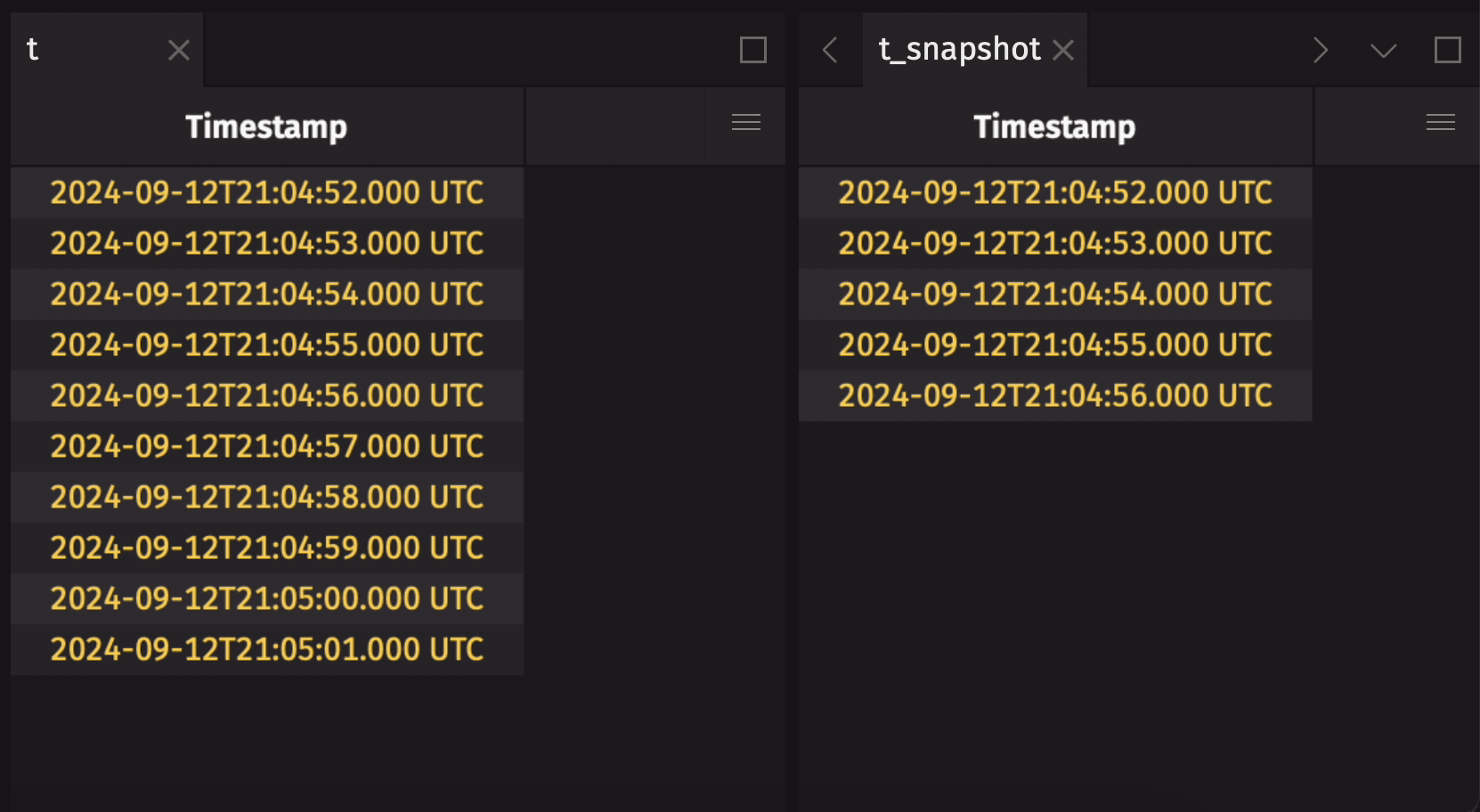
Verify that the snapshot is static with is_refreshing:
Standard streaming tables
Most streaming Deephaven tables are "standard" tables. These are the most flexible and least constrained types of tables, with the following key properties:
- Rows can be added, modified, deleted, or reindexed at any time, at any position in the table.
- The table's size can grow without bound.
These properties have some important consequences:
- Index-based operations, stateful operations, or operations using special variables may yield results that change unexpectedly between update cycles. By default, Deephaven throws an error in these cases.
- The rows in standard tables are not guaranteed to maintain their original order of arrival. Operations should not assume anything about the order of data in a standard table.
- Standard tables may eventually result in out-of-memory errors in data-intensive applications.
These properties are not ideal for every use case. Deephaven's specialized table types provide alternatives.
Specialization 1: Append-only
Append-only tables are highly-constrained types of tables. They have the following key properties:
- Rows can only be added to the end of the table.
- Once a row is in an append-only table, it cannot be modified, deleted, or reindexed.
- The table's size can grow without bound.
These properties yield the following consequences:
- Append-only tables guarantee that old rows will not change, move, or disappear, so index-based operations, stateful operations, or operations using special variables are guaranteed to yield results that do not change unexpectedly between update cycles.
- The rows in append-only tables are guaranteed to maintain their original order of arrival.
- Append-only tables may eventually result in out-of-memory errors in data-intensive applications.
Append-only tables are useful when the use case needs a complete and ordered history of every record ingested from a stream. They are safe and predictable under any Deephaven query and are guaranteed to retain all the data they've seen.
Specialization 2: Add-only
Add-only tables are relaxed versions of append-only tables. They have the following key properties:
- Rows can only be added to the table, but they may be added at any position in the table as long as they have a new row key (see How do row keys and positional indices behave during table operations for details). If a new row is added in a way that requires a shift, such as with
merge, it is not an add-only operation. - Existing rows cannot be deleted or modified, but may be reindexed.
- The table's size can grow without bound.
These properties yield the following consequences:
- Index-based operations, stateful operations, or operations using special variables may yield results that change unexpectedly between update cycles. By default, Deephaven throws an error in these cases.
- The rows in add-only tables are not guaranteed to maintain their original order of arrival. Operations should not assume anything about the order of data in an add-only table.
- Add-only tables may eventually result in out-of-memory errors in data-intensive applications.
Specialization 3: Blink
Blink tables keep only the set of rows received during the current update cycle. Users can create blink tables when ingesting Kafka streams, creating time tables, or using Table Publishers. They have the following key properties:
- The table only consists of rows added in the previous update cycle.
- No rows persist for more than one update cycle.
- The table's size is bounded by the size of the largest update it receives.
These properties have the following consequences:
- Since blink tables see a brand new world at every update cycle, index-based operations, stateful operations, or operations using special variables are guaranteed to yield results that do not change unexpectedly between update cycles.
- The entire table changes every update cycle, so preserving row order from cycle to cycle is irrelevant.
- Blink tables can only cause memory problems if a single update receives more data than fits in available RAM. This is unusual, but not impossible.
Blink tables are the default table type for Kafka ingestion within Deephaven because they use little memory. They are most useful for low-memory aggregations, deriving downstream tables, or using programmatic listeners to react to data.
Check whether a table is a blink table with the is_blink property:
Specialized semantics for blink tables
Aggregation operations such as agg_by and count_by operate with special semantics on blink tables, allowing the result to aggregate over the entire observed stream of rows from the time the operation is initiated. That means, for example, that a sum_by on a blink table will contain the resulting sums for each aggregation group over all observed rows since the sum_by was applied, rather than just the sums for the current update cycle. This allows for aggregations over the full history of a stream to be performed with greatly reduced memory costs when compared to the alternative strategy of holding the entirety of the stream as an in-memory table.
Here is an example that demonstrates a blink table's specialized aggregation semantics:
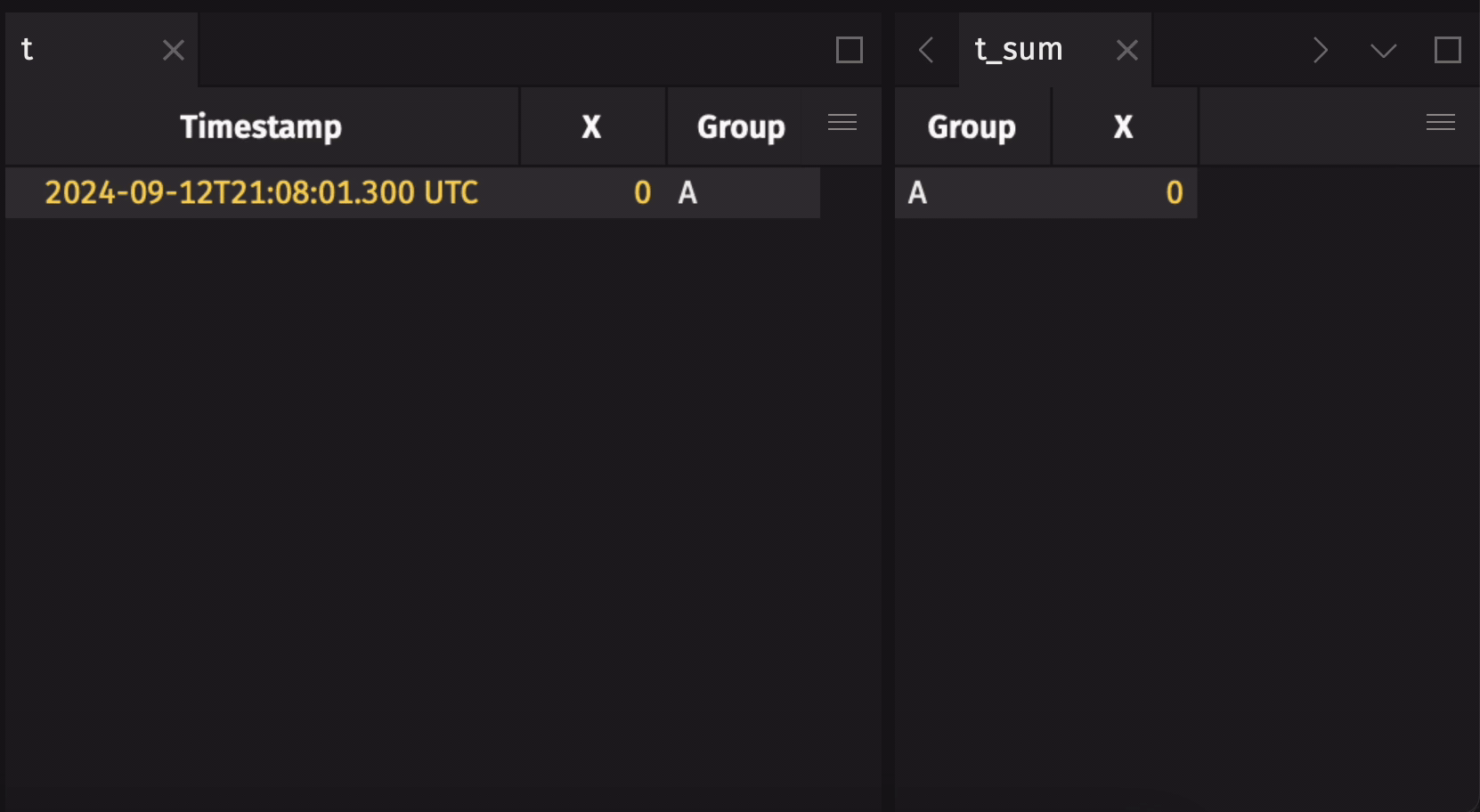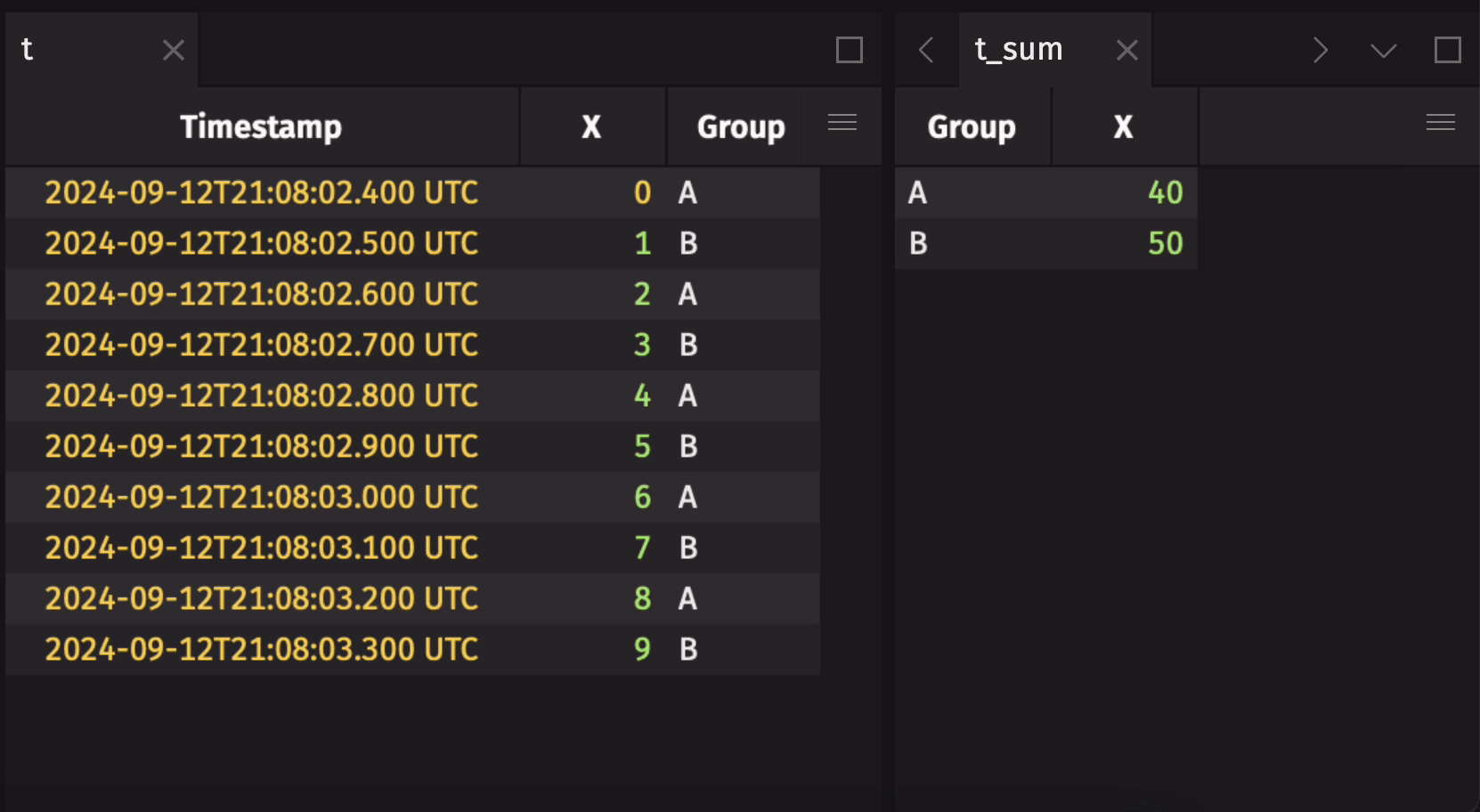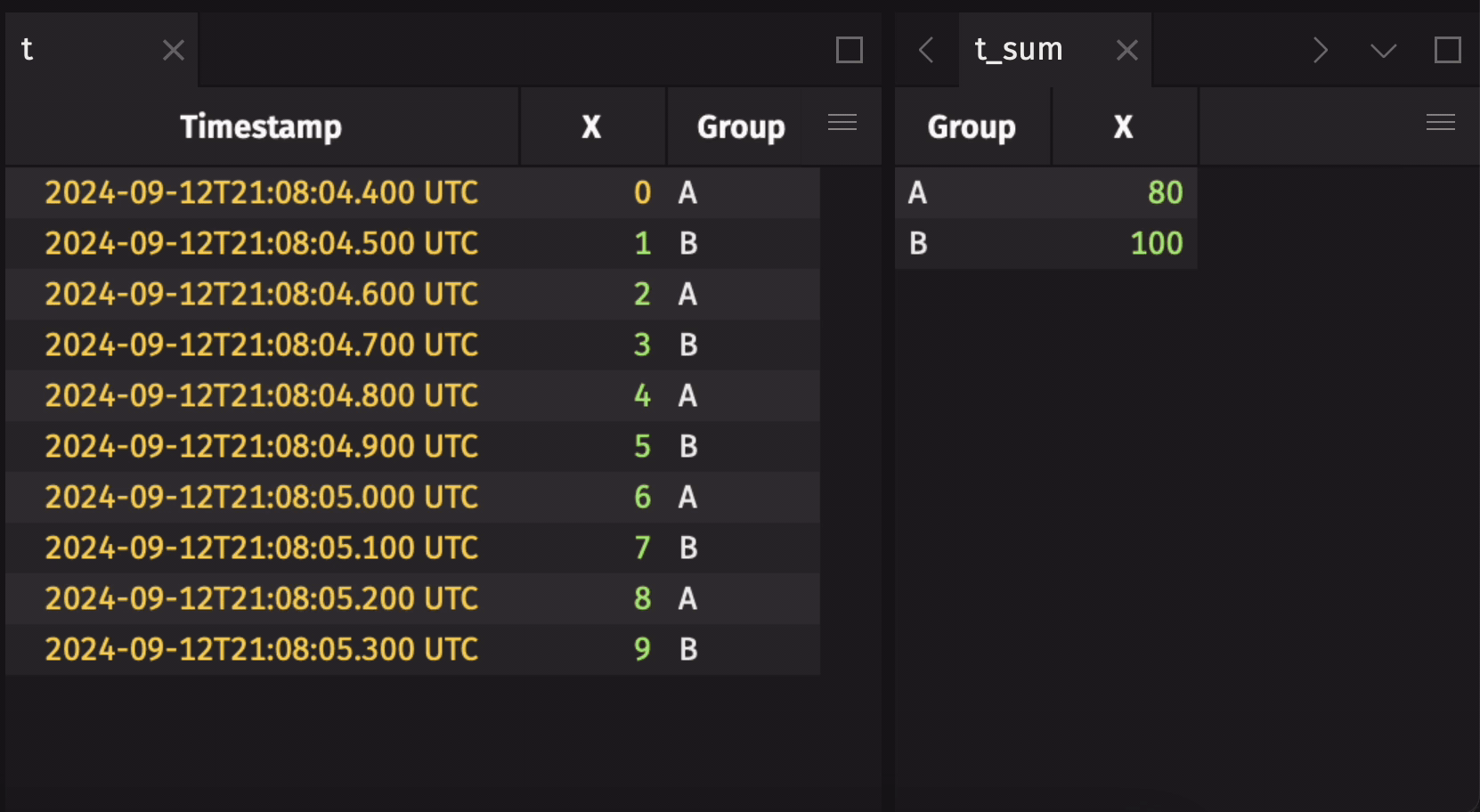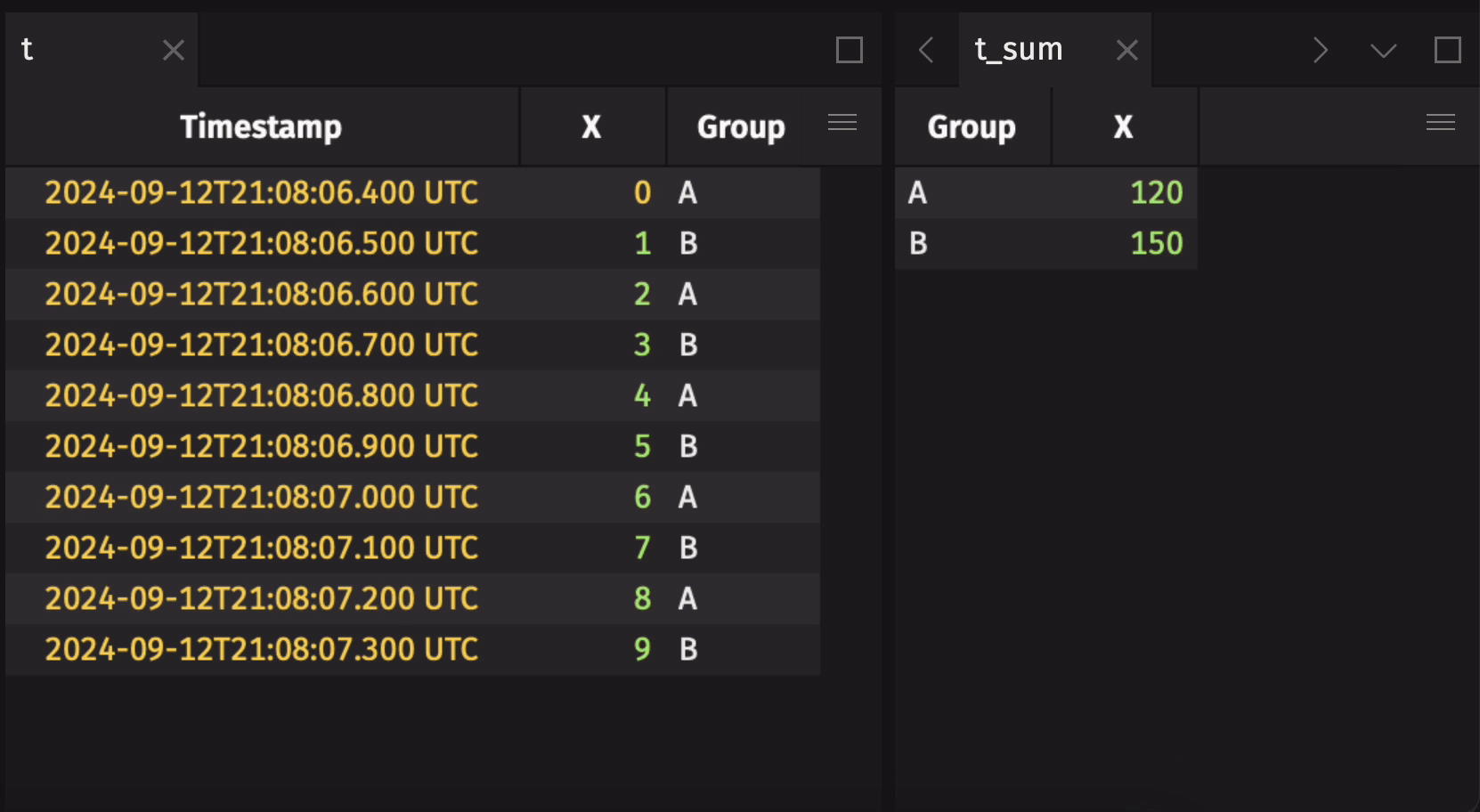
These special aggregation semantics may not always be desirable. Disable them by calling remove_blink on the blink table:
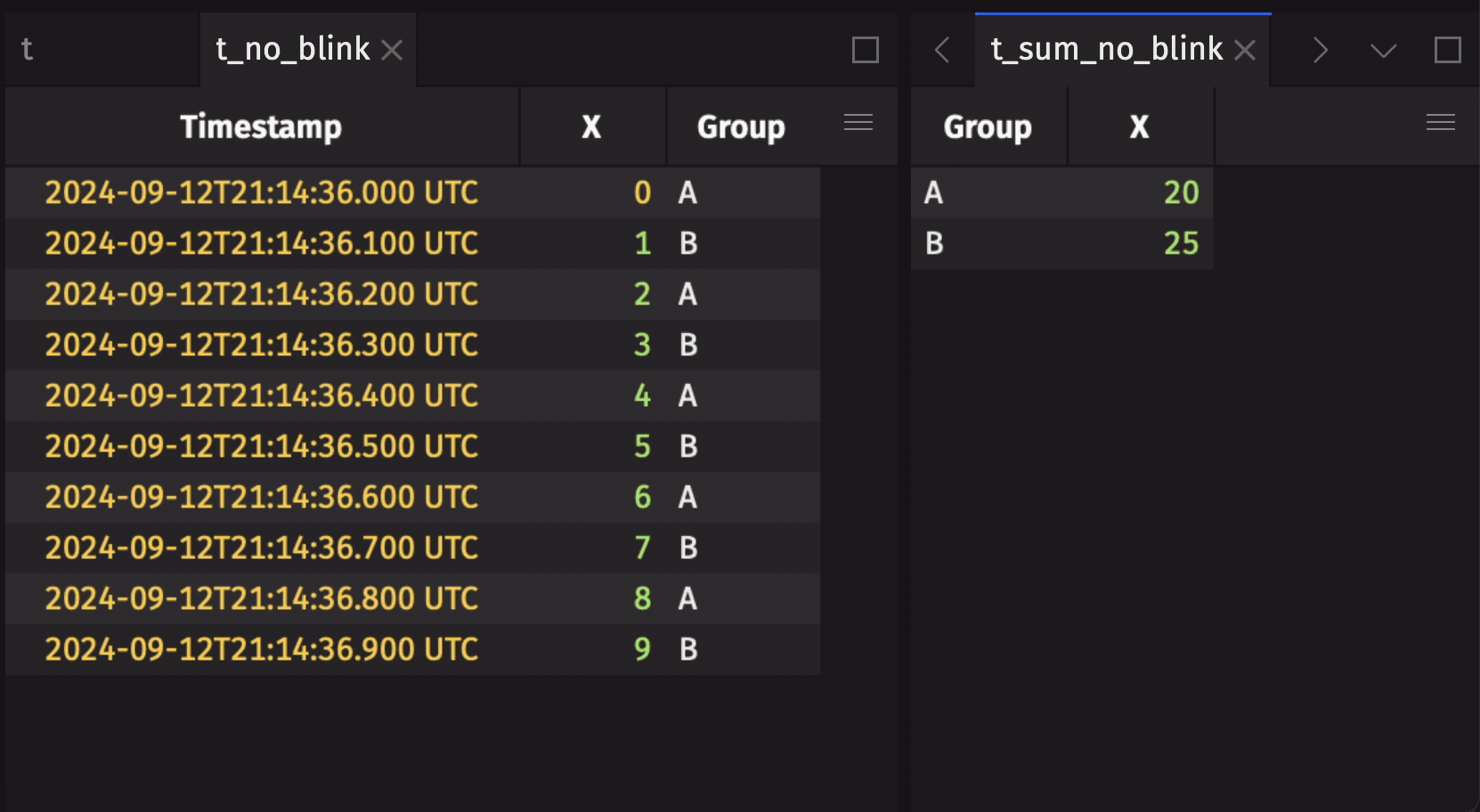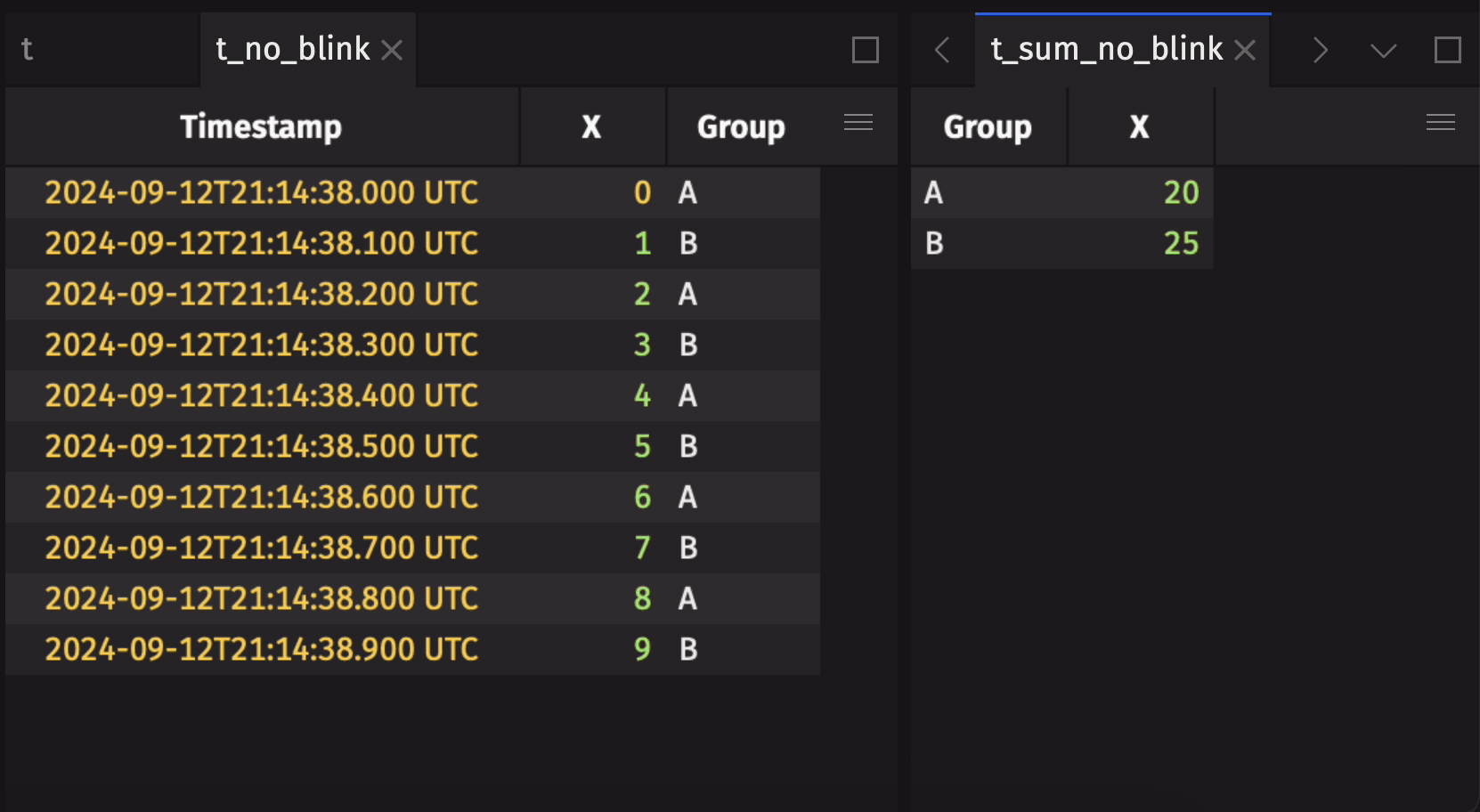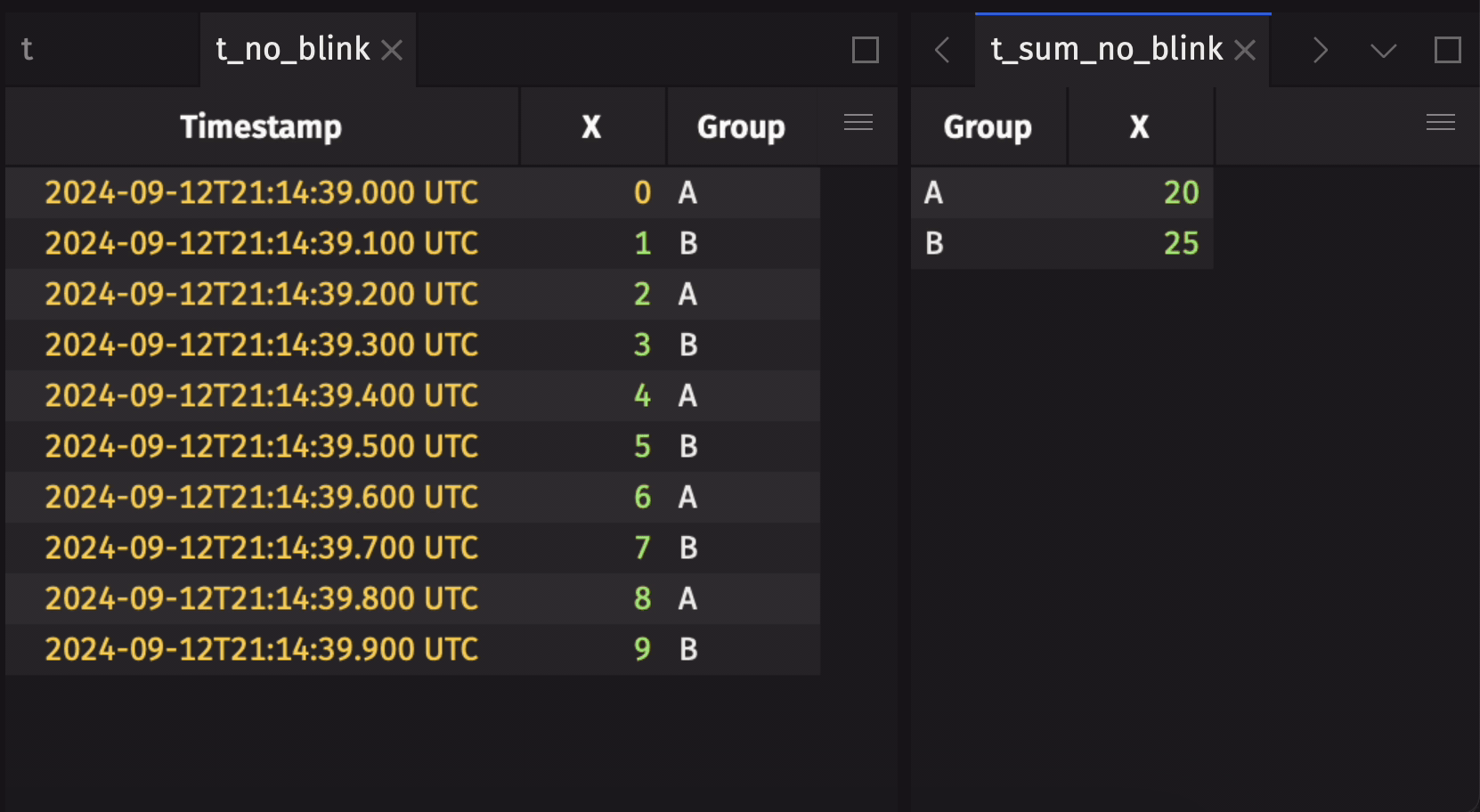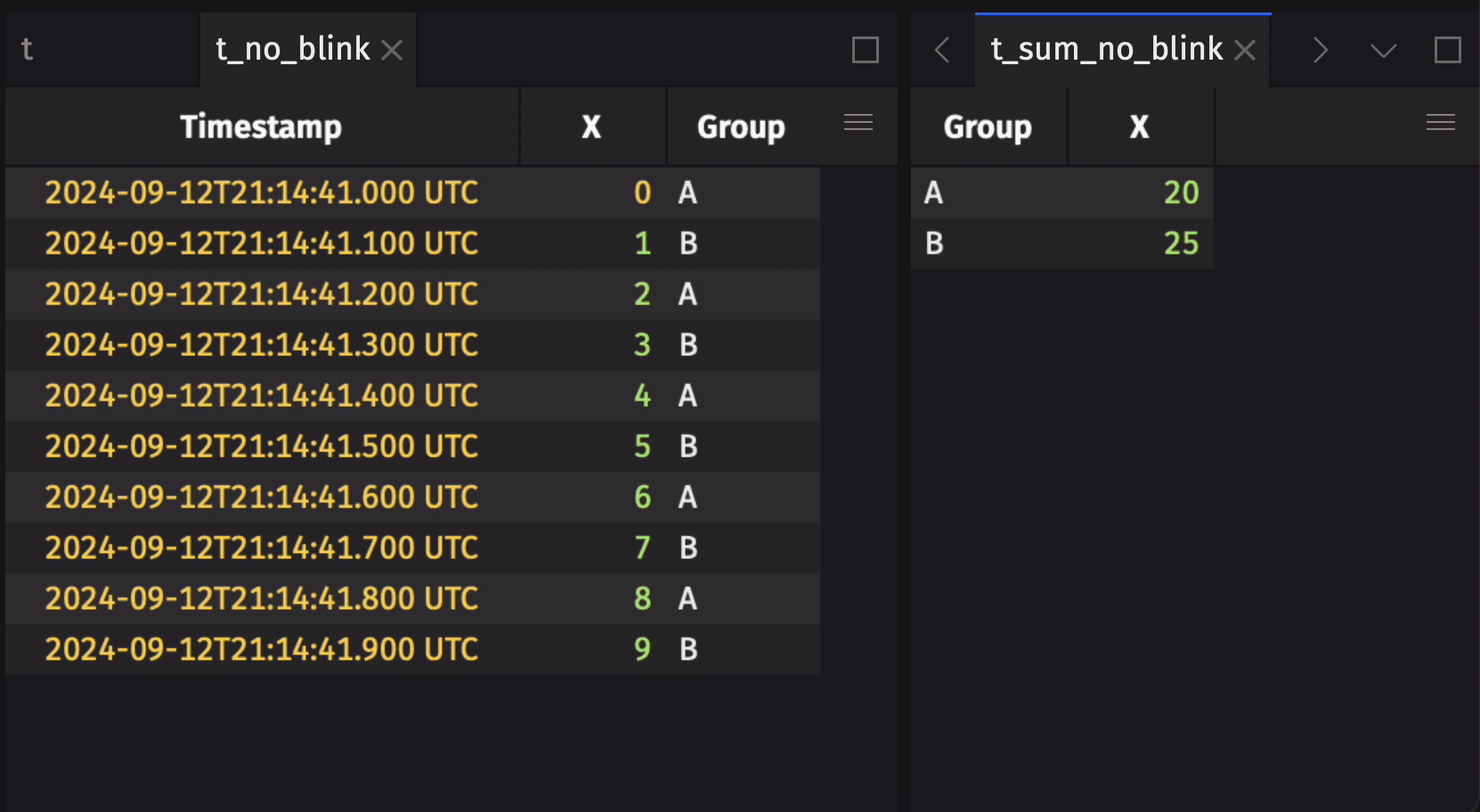
Most operations on blink tables behave exactly as they do on other tables (see the exclusions below); that is, added rows are processed as usual. For example, select on a blink table will contain only the newly added rows from the current update cycle.
Because Deephaven does not need to keep all the history of rows read from the input stream in memory, table operations on blink tables may require less memory.
Tip
To disable blink table semantics, use remove_blink, which returns a child table that is identical to the parent blink table in every way, but is no longer marked for special blink table semantics. The resulting table will still exhibit the “blink” table update pattern, removing all previous rows on each cycle, and thus only containing “new” rows.
Unsupported operations
Attempting to use the following operations on a blink table will raise an error:
group_bypartition_by(see below for a workaround)partitioned_agg_byhead_pcttail_pctsliceslice_pctagg_byif eithergrouporpartitionis used.rollupifincludeConstituents=true.tree
Create an append-only table from a blink table
It is common to create an append-only table from a blink table to preserve the entire data history. Use blink_to_append_only to do this:
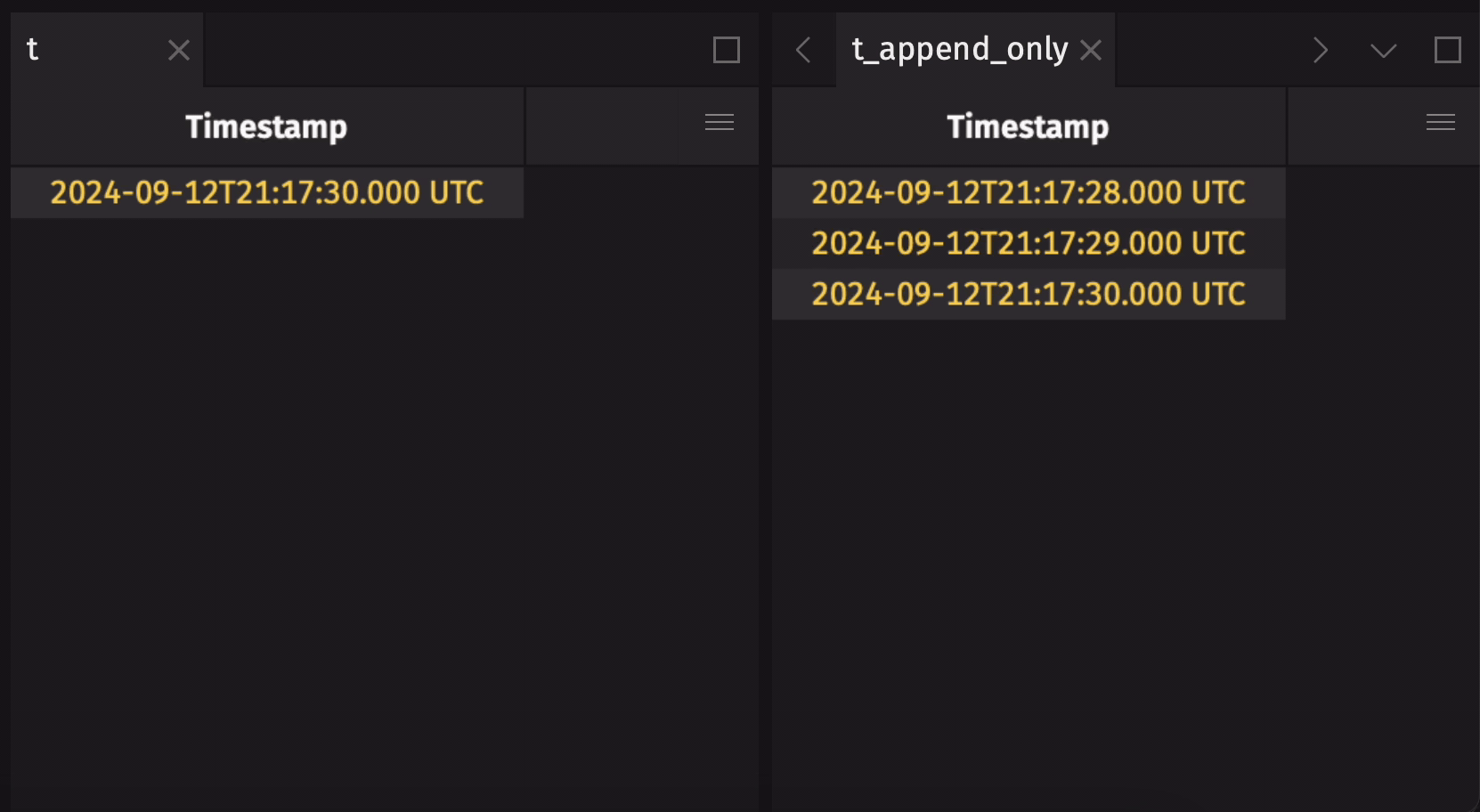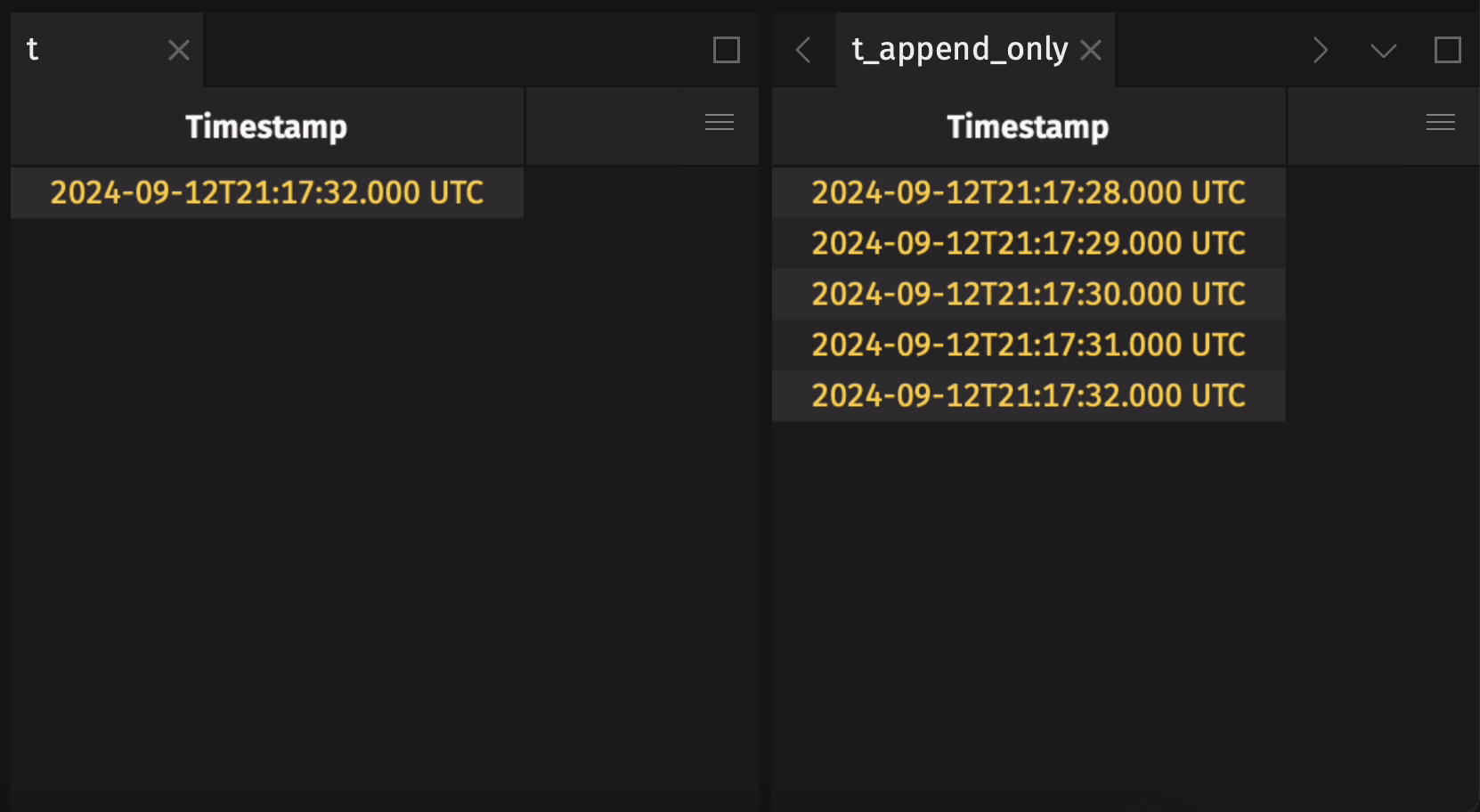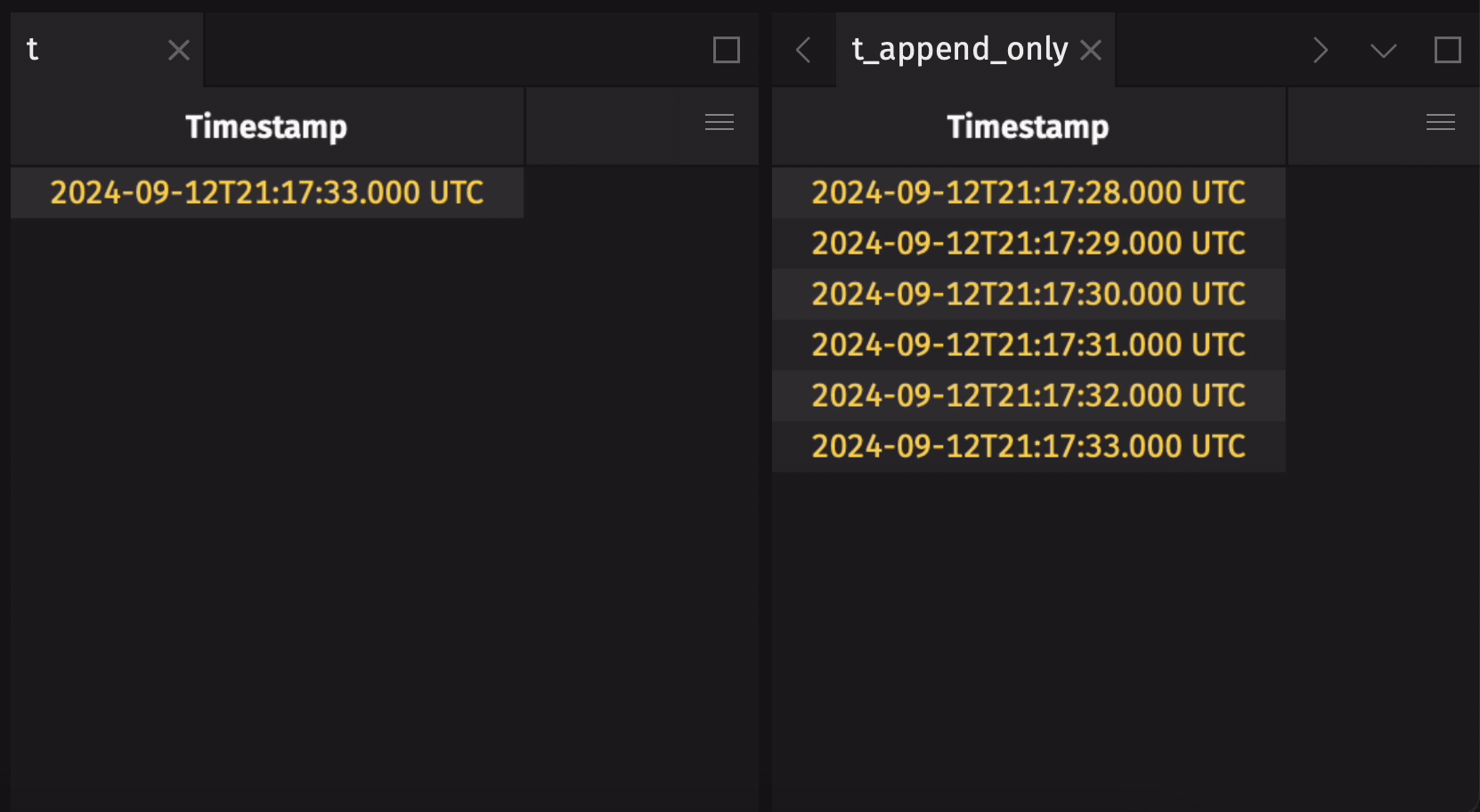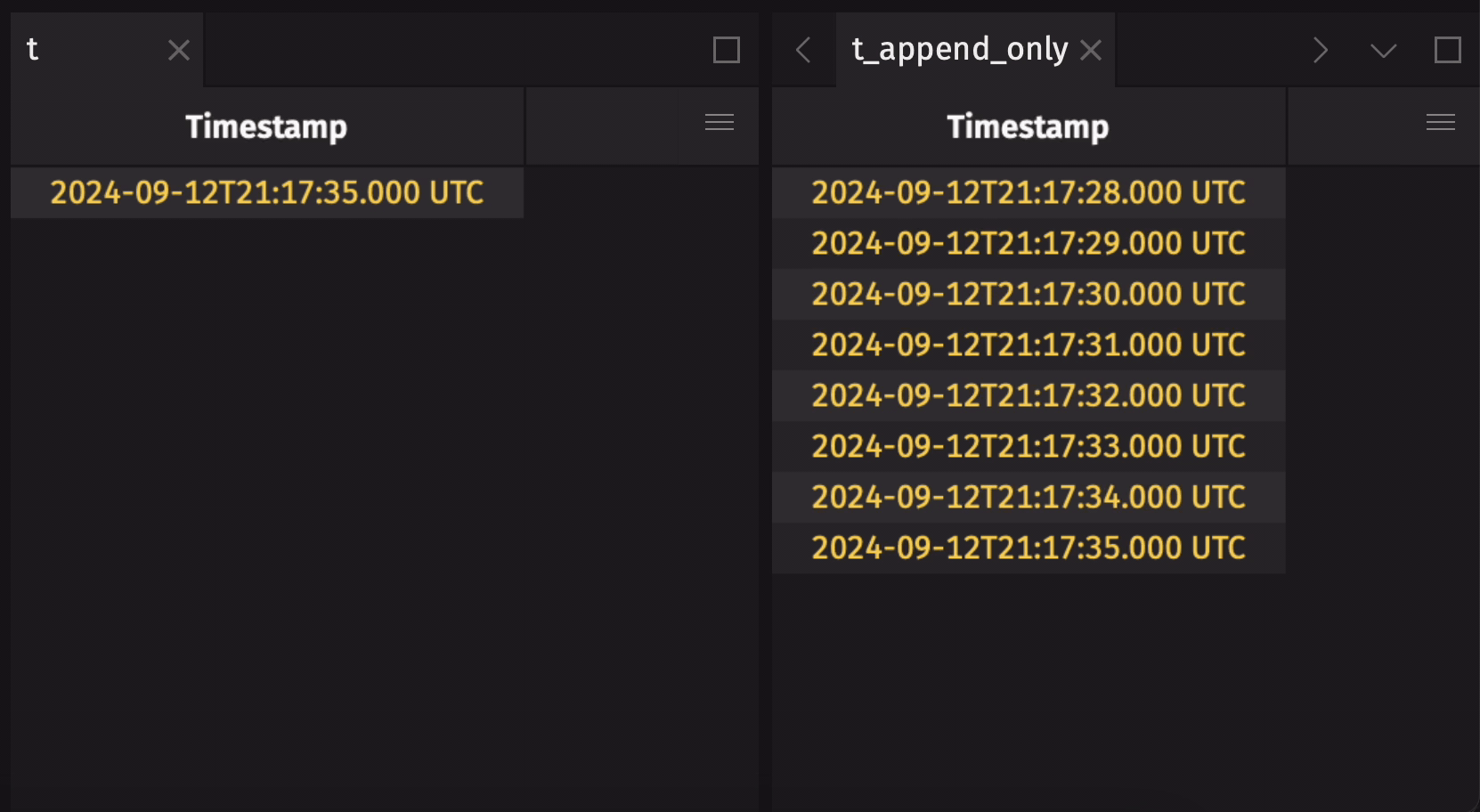
Create a blink table from an add-only table
It may be useful to create a blink table from an add-only table. This will only provide real benefit if the upstream add-only table is not fully in-memory. If the upstream add-only table is already fully in-memory, the operation will not fail, but there will be no memory savings. Use add_only_to_blink to accomplish this:
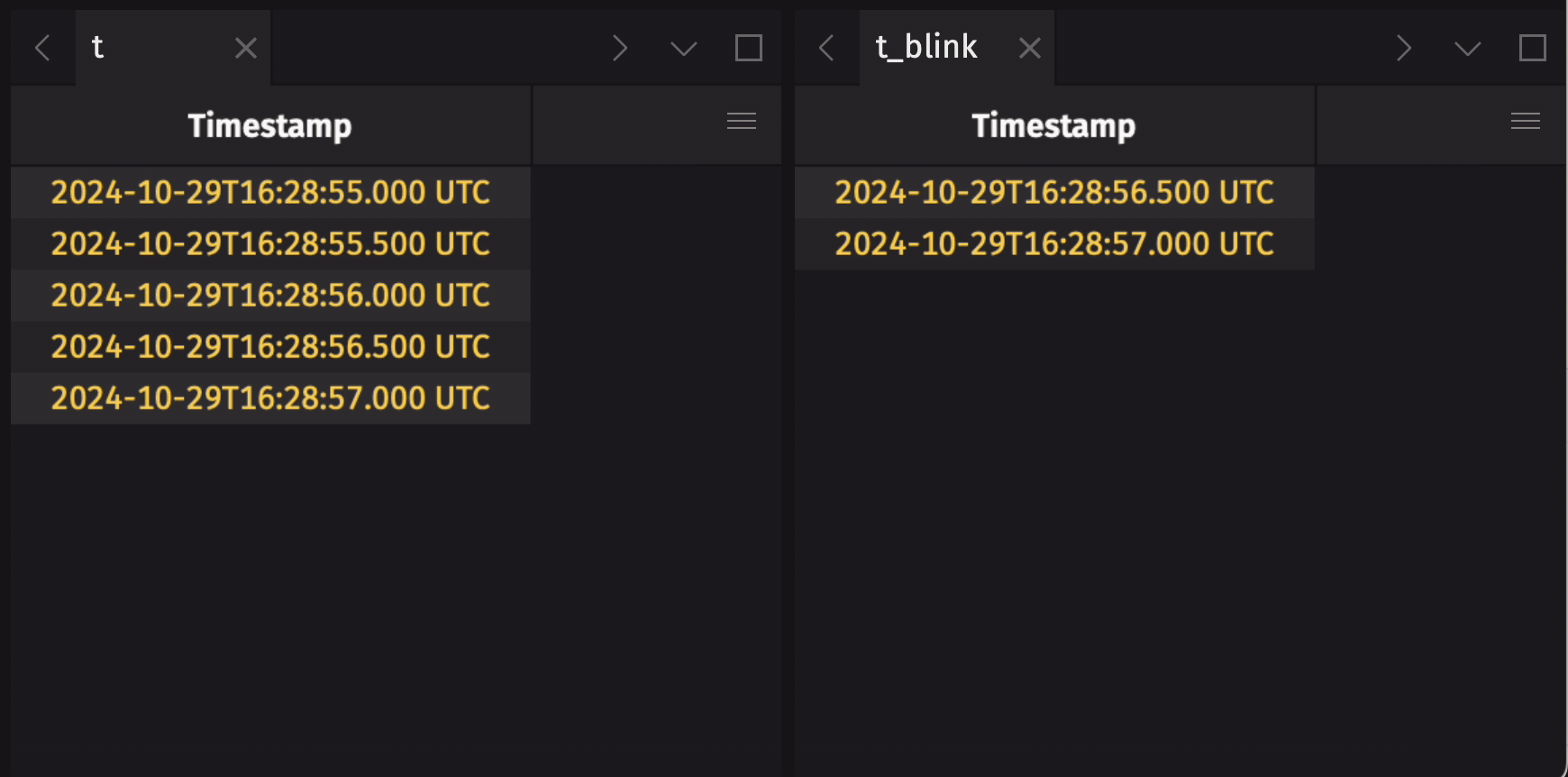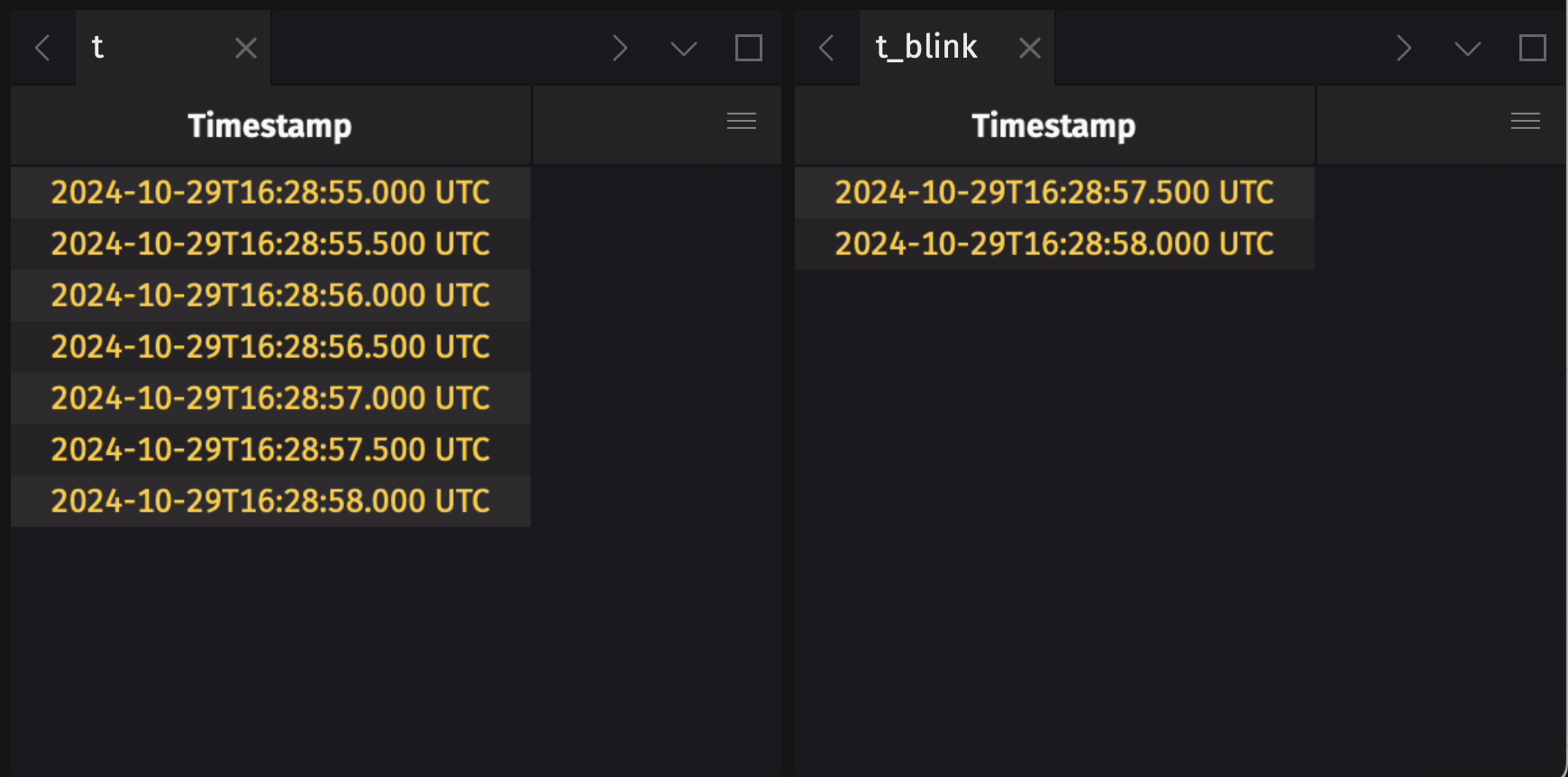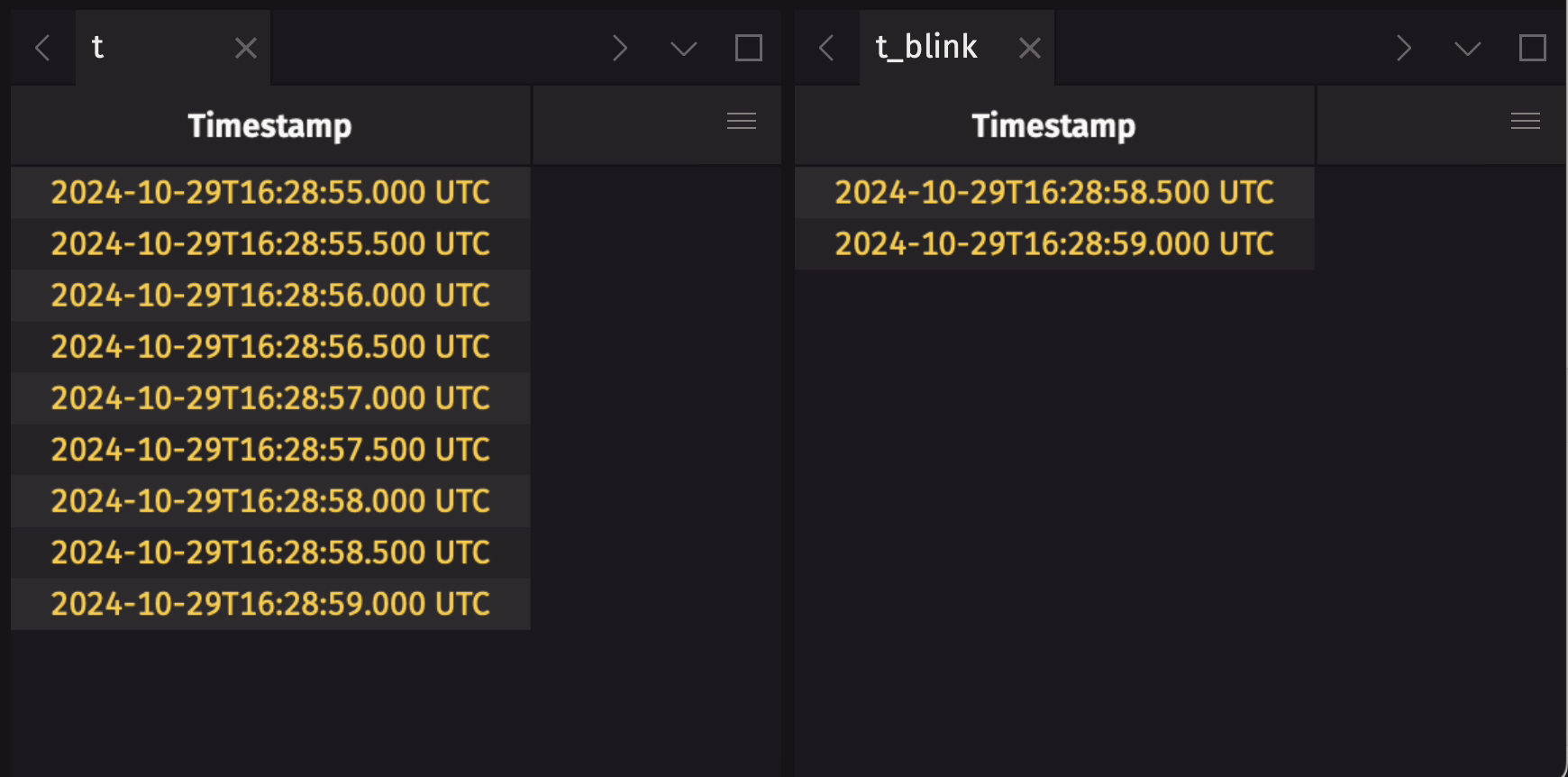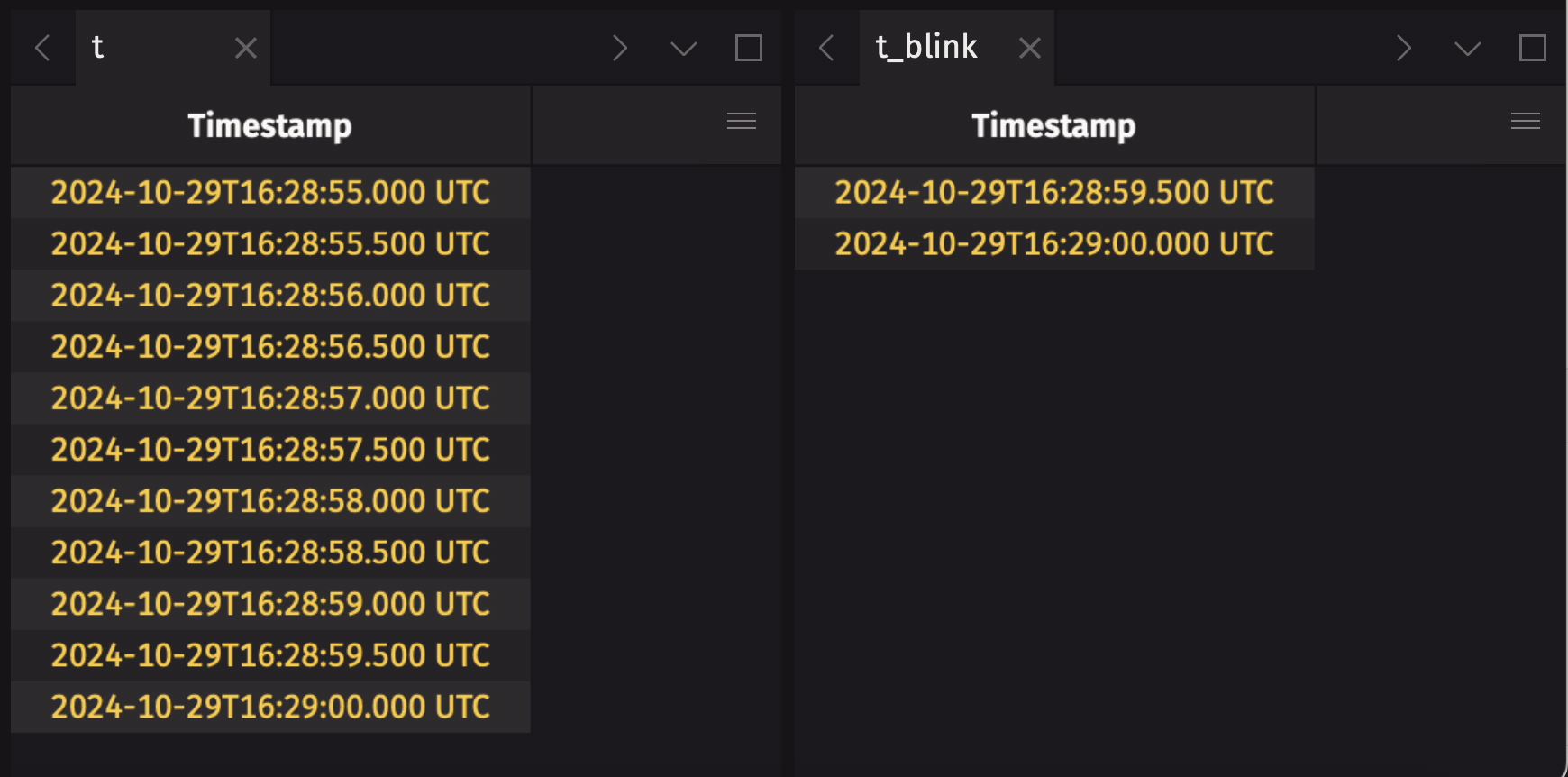
Partition a blink table
To partition a blink table, drop the blink attribute, create the partition, and then use a transform to add back the blink table attribute:
Specialization 4: Ring
Ring tables are like standard tables, but are limited in how large they can grow. They have the following key properties:
- Rows can be added, modified, deleted, or reindexed at any time, at any position in the table.
- The table's size is strictly limited to the latest
Nrows, set by the user. As new rows are added, old rows are discarded so as to not exceed the maximum limit.
These properties have the following consequences:
- Index-based operations, stateful operations, or operations using special variables may yield results that change unexpectedly between update cycles. By default, Deephaven throws an error in these cases.
- The rows in ring tables are not guaranteed to maintain their original order of arrival. Operations should not assume anything about the order of data in a ring table.
- Ring tables will not grow without bound and are strictly limited to a maximum number of rows. Once that limit is reached, the oldest rows are discarded and deleted from memory.
Ring tables are semantically the same as standard tables, and they do not get specialized aggregation semantics like blink tables do. However, operations use less memory because ring tables dispose of old data.
Create a ring table from a blink table
It is common to create a ring table from a blink table to preserve some data history, but not all. Use ring_table to do this.
The following example creates a ring table that holds the five most recent observations from a blink table:
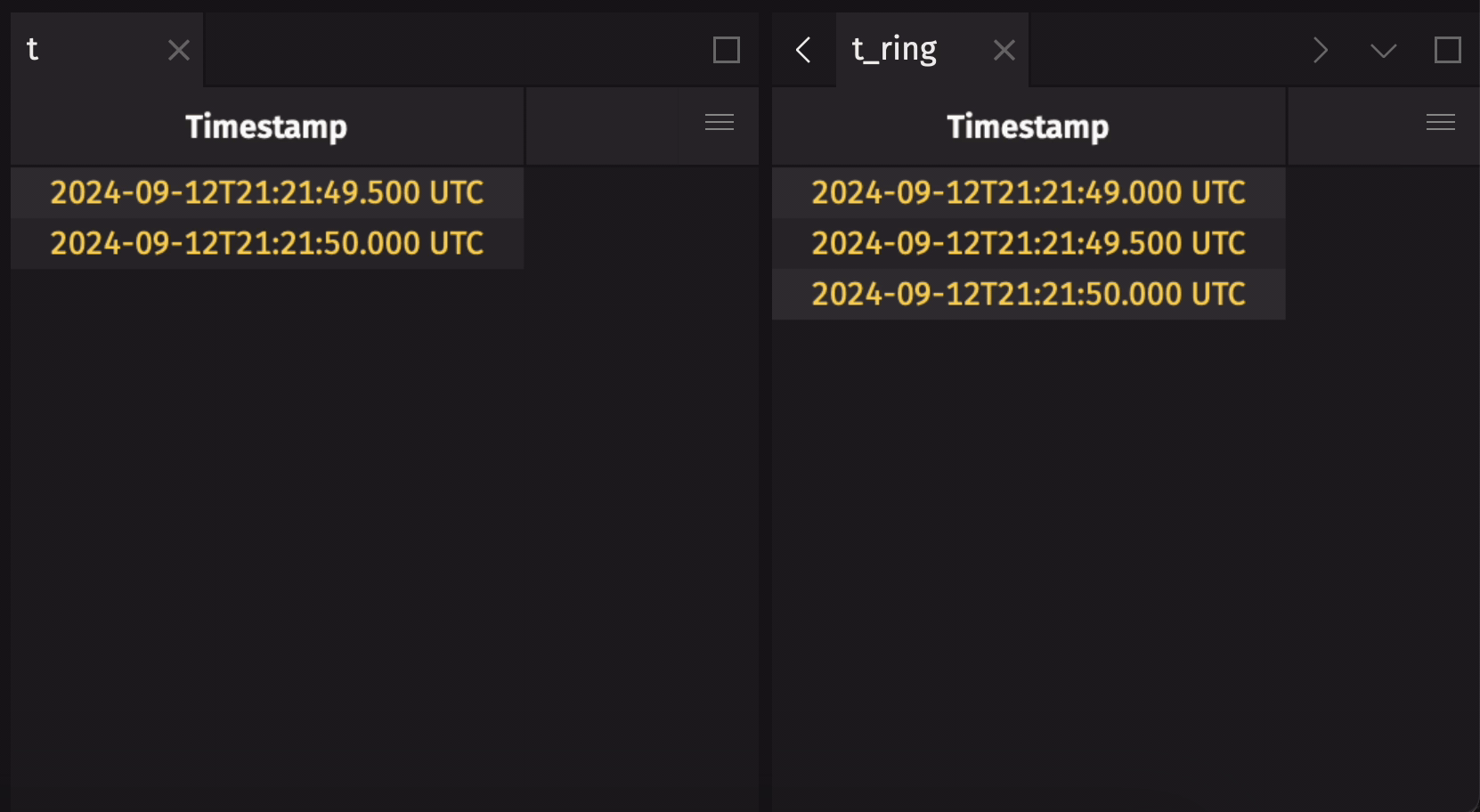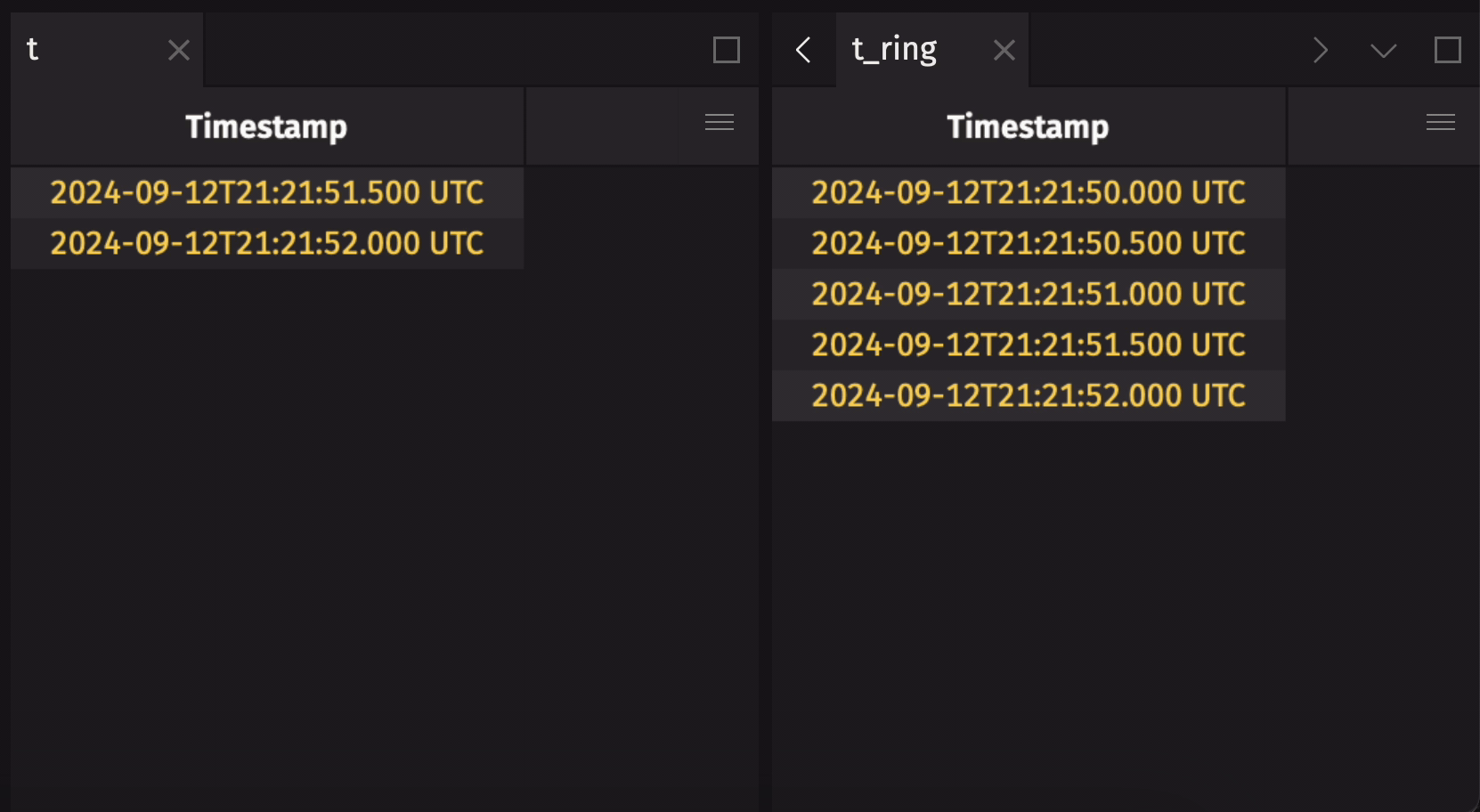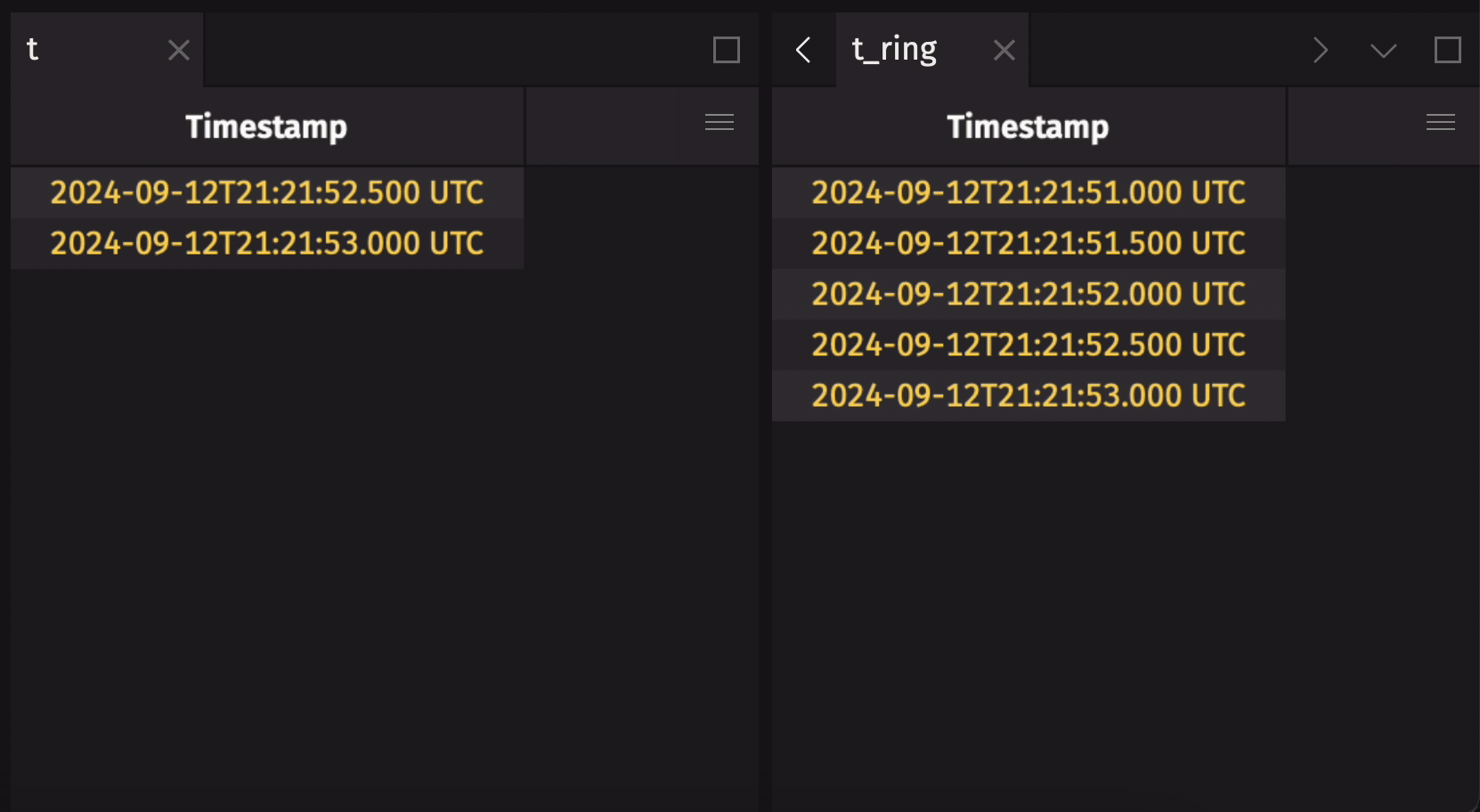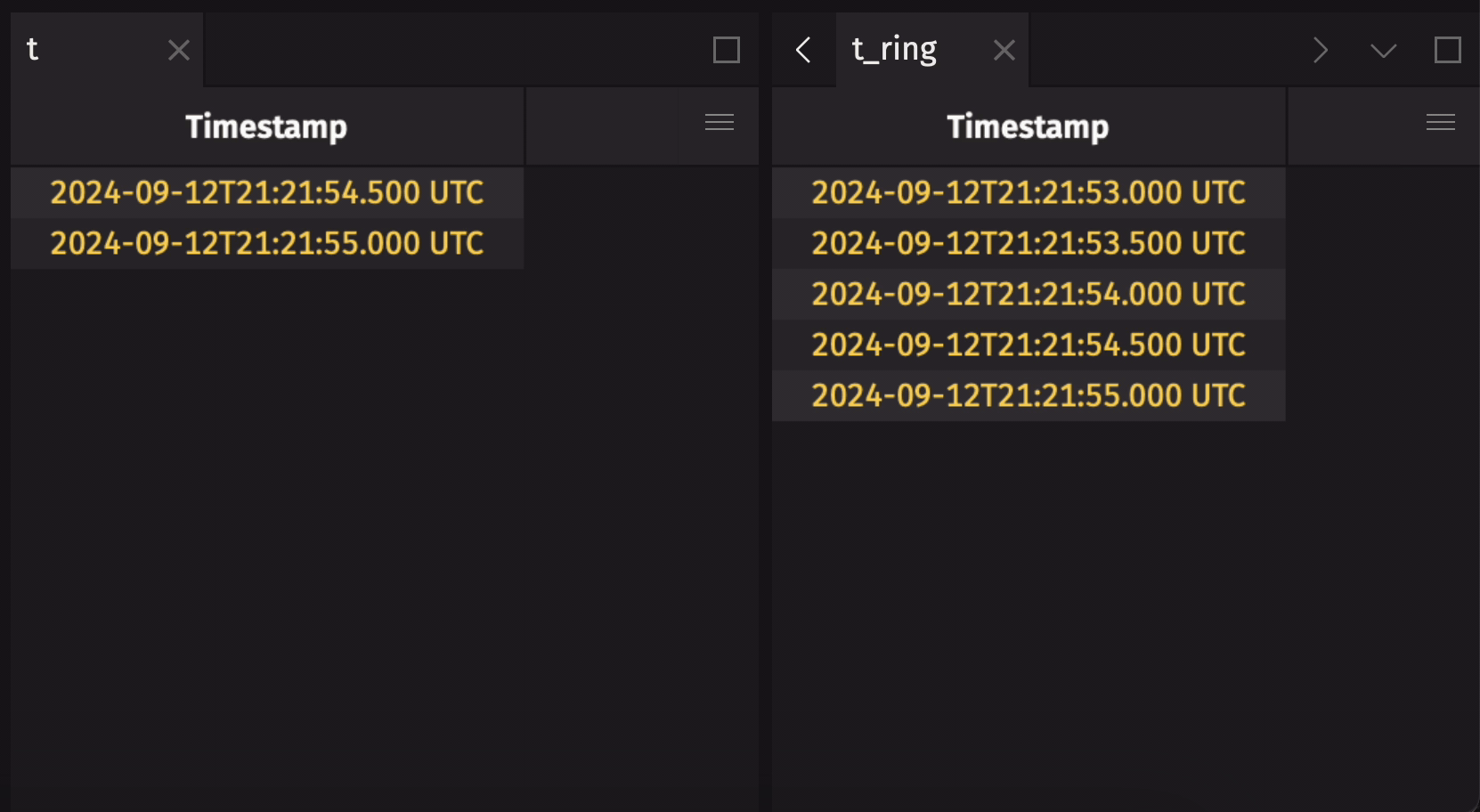
Create a ring table from an append-only table
Caution
Creating a ring table from an append-only table does not give the memory savings that ring tables are useful for.
Ring tables can also be created from append-only tables using ring_table. This is a less common use case because the typical memory savings that ring tables afford is lost. If there is an append-only table anywhere in the equation, it can grow until it eats up all available memory. A downstream ring table will only appear to save on memory, and is effectively equivalent to applying a tail operation to an append-only table.
This example creates a ring table with a 5-row capacity from a simple append-only time table:
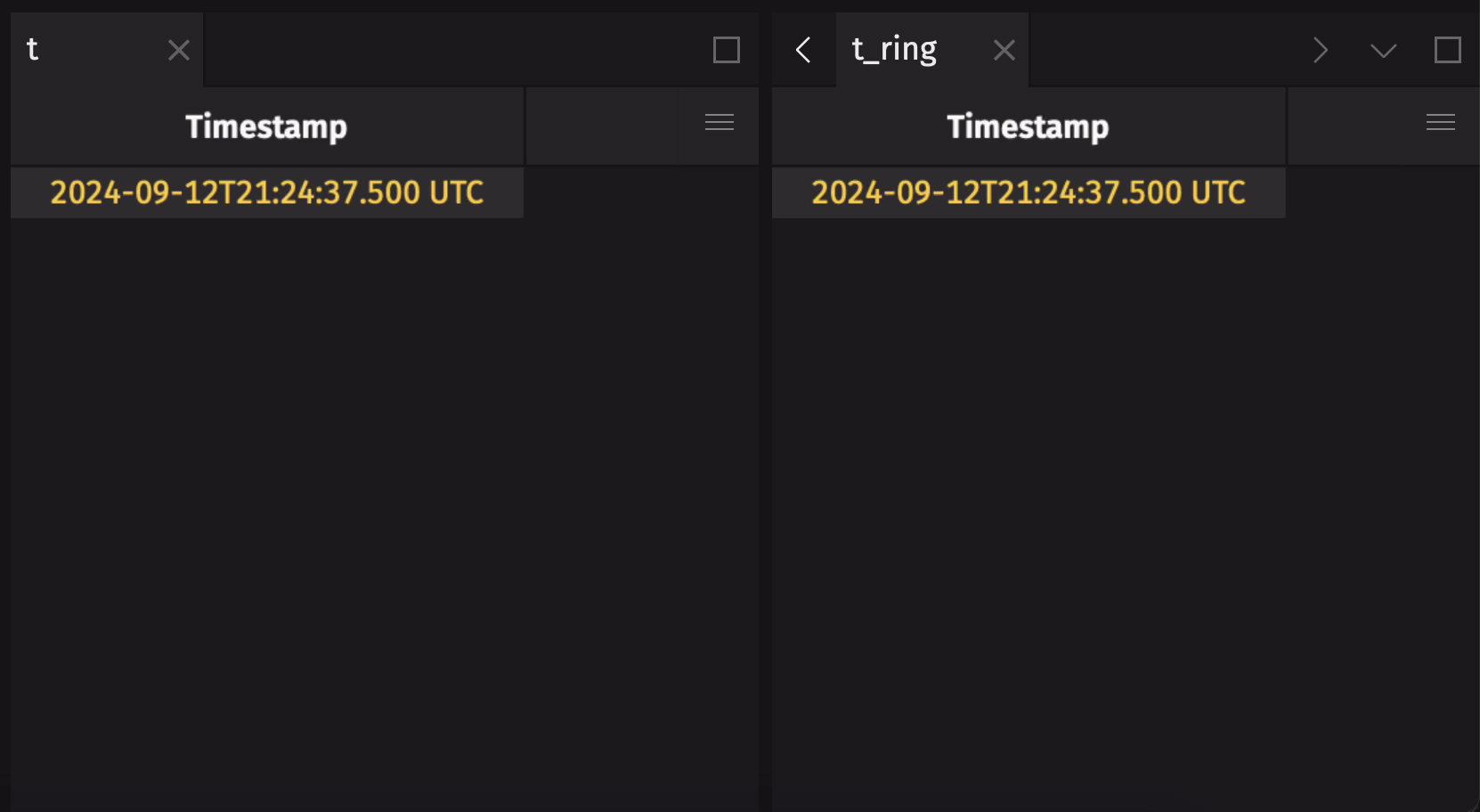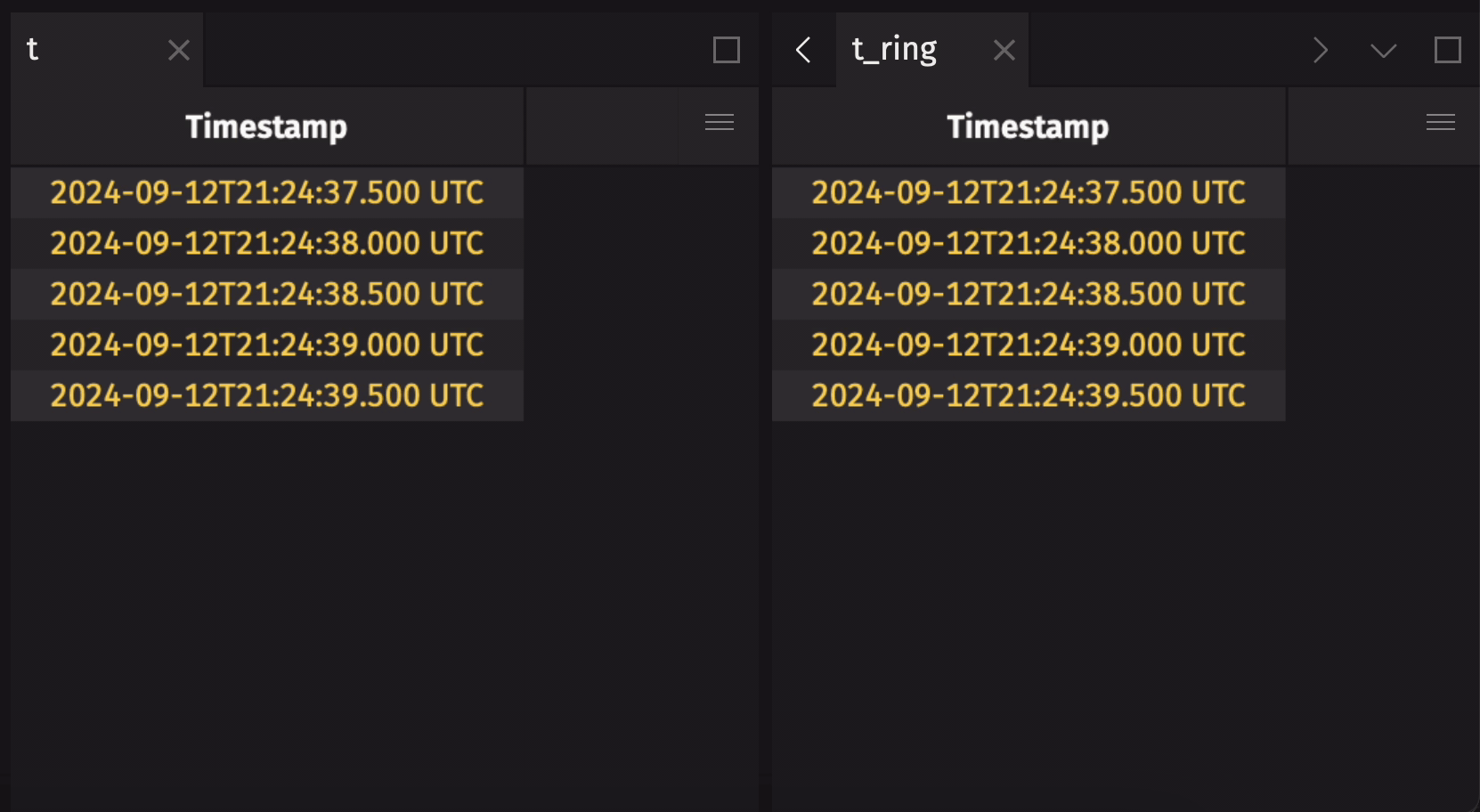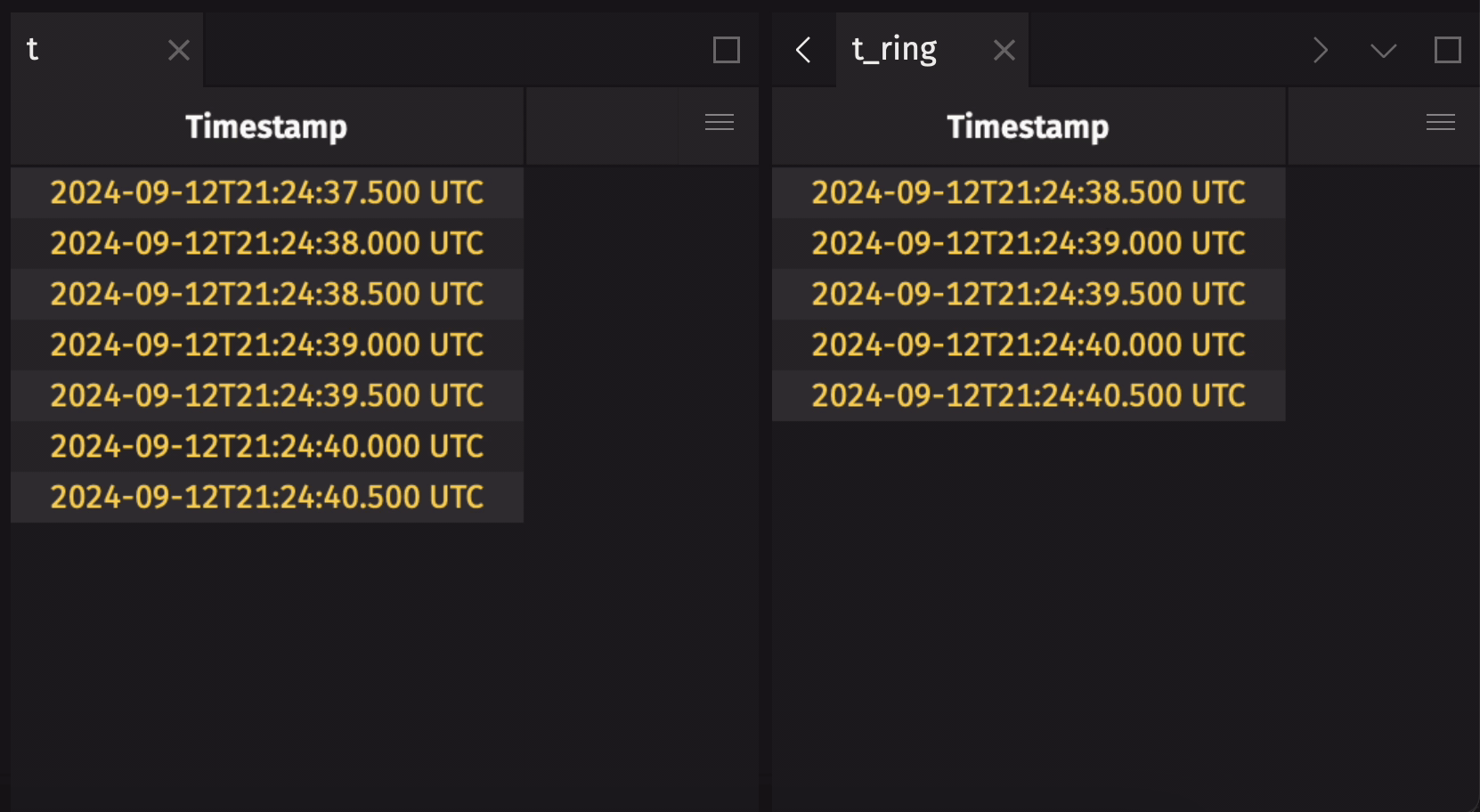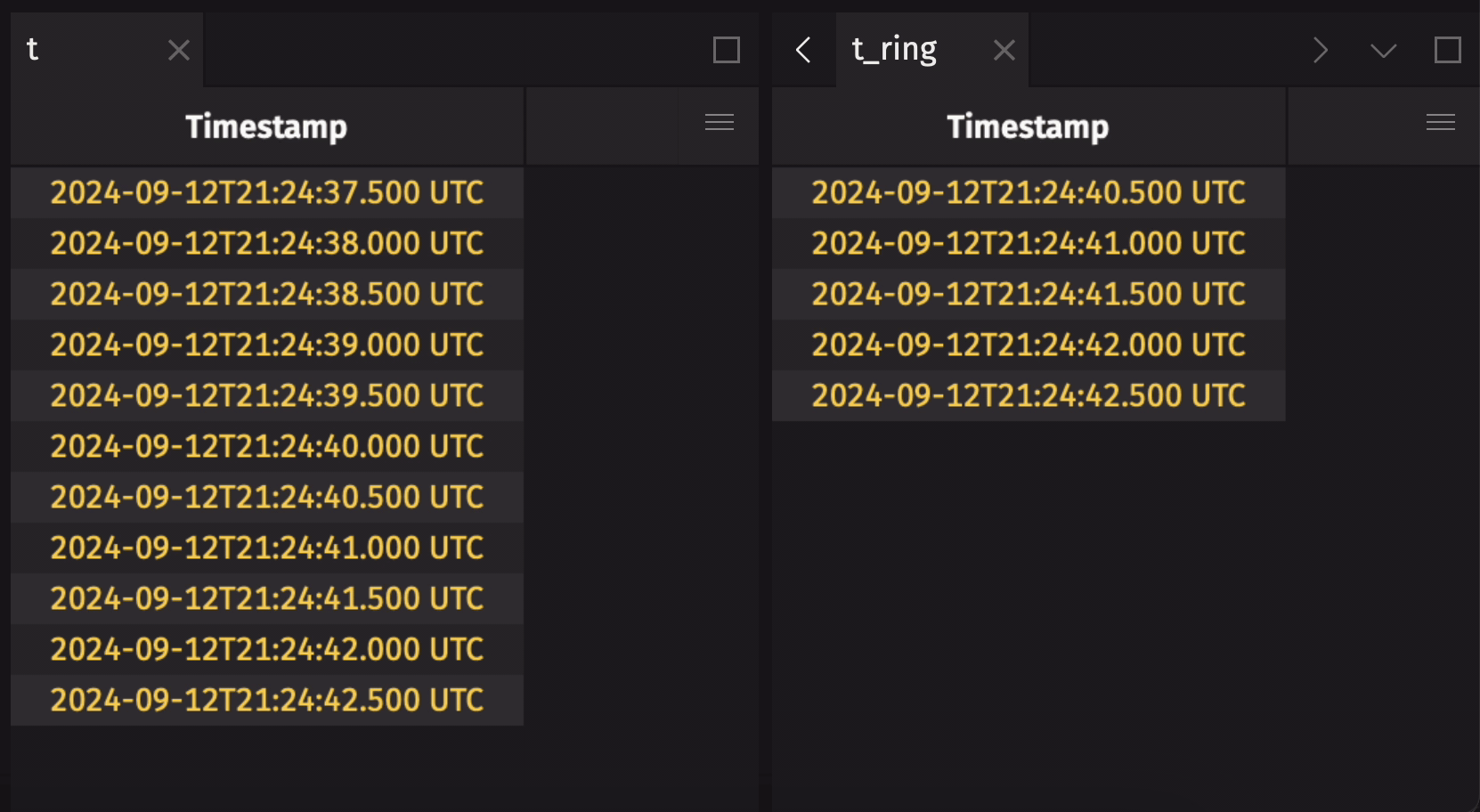
If the source append-only table already has rows in it when ring_table is called, the resulting ring table will include those rows by default:

To disable this behavior, set initialize = False:
