How to write and read multiple Parquet files
This guide will show you how to read a directory of Parquet files as well as partitioned Parquet files.
Read and write a Parquet directory
Directory structure
This example will show you how to read a directory of similar Parquet files into a Deephaven table, supplying just the directory path. They must be flat Parquet files, meaning that they have no partitioning columns.
It is common to use Parquet for large-scale data. In Deephaven, when we load a Parquet file into a table we do not load the whole file into RAM. This means that files much larger than the available RAM can be loaded as tables. However, you might already have a directory of Parquet files that you wish to read. These Parquet files may also be partitioned into directories and sub-directories.
To read an entire directory of Parquet files (and potentially sub-directories), every Parquet file in the directory needs to have the same schema.
Create files
To see this in practice, you first need multiple Parquet files in your directory. Start by creating the grades1 and grades2 tables, containing student names, test scores, and GPAs.
from deephaven import new_table
from deephaven.column import int_col, double_col, string_col
grades1 = new_table(
[
string_col("Name", ["Ashley", "Jeff", "Rita", "Zach"]),
int_col("Test1", [92, 78, 87, 74]),
int_col("Test2", [94, 88, 81, 70]),
int_col("Average", [93, 83, 84, 72]),
double_col("GPA", [3.9, 2.9, 3.0, 1.8]),
]
)
grades2 = new_table(
[
string_col("Name", ["Jose", "Martha", "Mary", "Richard"]),
int_col("Test1", [67, 92, 87, 54]),
int_col("Test2", [97, 99, 92, 63]),
int_col("Average", [82, 96, 93, 59]),
double_col("GPA", [4.0, 3.2, 3.6, 2.7]),
]
)
- grades1
- grades2
Now, use the write method to export each table as a Parquet file. write takes the following arguments:
- The table to be written. In this case,
grades1andgrades2. - The Parquet file to write to. In this case,
/data/grades/part1.parquetand/data/grades/part2.parquet. - (Optional)
parquetInstructionsfor writing files using compression codecs. Accepted values are:SNAPPY: Aims for high speed and a reasonable amount of compression, based on Google's Snappy compression format. IfParquetInstructionsis not specified, defaults toSNAPPY.UNCOMPRESSED: The output will not be compressed.LZ4_RAW: A codec based on the LZ4 block format. Should always be used instead ofLZ4.LZ4: Deprecated Compression codec loosely based on the LZ4 compression algorithm, but with an additional undocumented framing scheme. The framing is part of the original Hadoop compression library and was historically copied first in parquet-mr, then emulated with mixed results by parquet-cpp. Note thatLZ4is deprecated; useLZ4_RAWinstead.LZO: Compression codec based on or interoperable with the LZO compression library.GZIP: Compression codec based on the GZIP format (not the closely-related "zlib" or "deflate" formats) defined by RFC 1952.ZSTD: Compression codec with the highest compression ratio based on the Zstandard format defined by RFC 8478.
from deephaven.parquet import write
write(grades1, "/data/grades/part1.parquet")
write(grades2, "/data/grades/part2.parquet")
Deephaven writes files to locations relative to the base of its Docker container. See Docker data volumes to learn more about the relation between locations in the container and the local file system.
Read directory
Now, use the read method to import the entire Parquet directory as one table. read takes the following arguments:
- The Parquet directory to read. In this case,
/data/grades/. - (Optional )
parquetInstructionsfor codecs when the file type cannot be successfully inferred. Accepted values are:SNAPPY: Aims for high speed, and a reasonable amount of compression, based on Google's Snappy compression format. IfParquetInstructionsis not specified, defaults toSNAPPY.UNCOMPRESSED: The output will not be compressed.LZ4_RAW: A codec based on the LZ4 block format. Should always be used instead ofLZ4.LZ4: Deprecated Compression codec loosely based on the LZ4 compression algorithm, but with an additional undocumented framing scheme. The framing is part of the original Hadoop compression library and was historically copied first in parquet-mr, then emulated with mixed results by parquet-cpp. Note thatLZ4is deprecated; useLZ4_RAWinstead.LZO: Compression codec based on or interoperable with the LZO compression library.GZIP: Compression codec based on the GZIP format (not the closely-related "zlib" or "deflate" formats) defined by RFC 1952.ZSTD: Compression codec with the highest compression ratio based on the Zstandard format defined by RFC 8478.LEGACY: Load any binary fields as strings. Helpful to load files written in older versions of Parquet that lacked a distinction between binary and string.
from deephaven.parquet import read
result = read("/data/grades")
- result
Write and read a partitioned Parquet file
Write a partitioned Parquet file
In this example, we write a table to a partitioned Parquet file. Partitioning creates multiple, smaller files based on the values of one or more columns. Unlike a directory, these must contain a partitioning column.
from deephaven import new_table
from deephaven.column import double_col, string_col
from deephaven.parquet import write
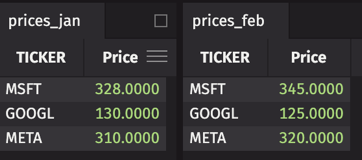
prices_jan = new_table(
[
string_col("TICKER", ["MSFT", "GOOGL", "META"]),
double_col("Price", [328, 130, 310]),
]
)
prices_feb = new_table(
[
string_col("TICKER", ["MSFT", "GOOGL", "META"]),
double_col("Price", [345, 125, 320]),
]
)
# Write each table to a subdirectory inside "Prices" under corresponding month
write(prices_jan, "Prices/Month=Jan/data.parquet")
write(prices_feb, "Prices/Month=Feb/data.parquet")
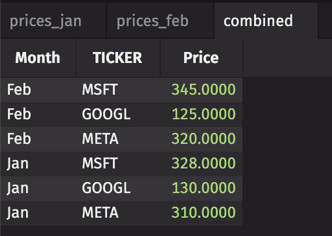
- prices_jan
- prices_feb
The structure of the "Prices" directory will look like:
Prices
├── Month=Feb
│ └── data.parquet
└── Month=Jan
└── data.parquet
Read a partitioned Parquet file
Now, use the read method to import the entire partitioned Parquet file.
from deephaven.parquet import read
combined = read("Prices")
Now we get a table with the additional partitioning column "Month".