Ingest Kafka Data
Ingesting a Kafka feed into Deephaven is done in the context of a Persistent Query. A separate Data Import Server (DIS) instance is run within the query script. The Deephaven Kafka ingester subscribes to one or more Kafka topics and replicates them to streaming Deephaven tables. The query additionally serves those tables to other workers through a Table Data Protocol (TDP) connection, as described by the routing configuration.
The Data Import Server stores the replicated Kafka offsets inside a Deephaven checkpoint record, which is updated atomically with the size of the replicated Deephaven table. This allows Deephaven to resume the Kafka stream and provide exactly-once replication of the Kafka stream even in the face of restarts. Note: a Kafka broker itself may provide different guarantees to its producers depending on the selected configuration (e.g., at-least-once delivery or best-effort delivery). Deephaven does not change those guarantees but rather preserves the same level of guarantee.
The Deephaven Core+ Kafka ingestion framework provides several advantages over the Legacy Kafka framework. Notably:
- The Core+ Kafka ingester can read Kafka streams both into in-memory tables and also persist them to disk using the DIS integration described on this page.
- Key and Value specifications are disjoint, which is an improvement over the
io.deephaven.kafka.ingest.ConsumerRecordToTableWriterAdapterpattern found in Legacy. - The Core+ KafkaIngester uses chunks for improved efficiency compared to row-oriented Legacy adapters.
Setting up the ingester
You may find it convenient to test ingestion by consuming the Kafka stream to an in-memory table at first. This allows you to tune your key and value specifications before creating a schema by following the instructions in the Deephaven Core documentation. After determining the desired properties and key/value specifications and examining the in-memory table, you can proceed to persistent ingestion. The properties and key/value specifications may also be used to create a schema.
Configure storage and data routing
The system data routing configuration needs to be changed so that data for the Kafka tables is sent to and read from the appropriate processes and locations.
There are two choices when setting up a new ingestion server. The preferred way for simple configurations is to use the dhconfig dis tool to add a data import server without modifying the routing file. You can instead manually configure routing.
This dhconfig command creates a Data Import Server named "KafkaImport1" that handles all tables in the "Kafka" namespace.
The KafkaImport1 DIS is configured to use private storage and the service registry. In most cases, no routing file updates are necessary.
Whether you manually configure routing or use dhconfig dis, you must create the directory for the DIS to persist the Kafka data (this directory is used in the ingestion script). For example, to create a directory for KafkaImport1:
The storage directory must be on local disk. Network file systems like NFS do not guarantee sufficient reliability for a Deephaven DIS to function correctly.
Creating an import script
The import script that starts the ingester can be tested/developed in a Code Studio using a merge worker. When run for production use, the script should be run as a "Live Query - Merge Server" Persistent Query. In either case, it must run on a specific merge server (not AutoMerge) to have permission to write data to the import server's filesystem and to ensure it always has access to the same file system. A complete example script is in the fixed partitions section below.
The import script handles:
- Configuring and starting the in-worker DIS using the storage and properties defined in the routing YAML.
- Setting properties for the Kafka consumer and starting the consumer.
- Configuring the key and value specifications.
The Kafka consumer used by the import script is an org.apache.kafka.clients.consumer.KafkaConsumer. Some of the properties that affect the KafkaConsumer's operation are shown in the examples here, but there are many more that relate to such cases as two-way TLS, authentication with a schema registry, and others. Please refer to the Apache documentation for KafkaConsumer for details and examples of other properties that can be configured.
The first time a Deephaven ingester connects to a topic, it requests Kafka records from offset 0 — i.e., the broker's oldest records for this topic.
As the in-worker DIS receives and processes Kafka records, it delivers the table row data to Deephaven clients that have subscribed for updates, and it also, in parallel, flushes and checkpoints row data to disk. When a checkpoint is durably committed, the ingester sends a checkpoint notification to the Kafka broker to update the latest offset that has been delivered. In this way, when an ingester is restarted, intentionally or unintentionally, it can pick up exactly where it left off in receiving records from the topic. On startup, the ingester's default behavior is to attempt to resume from the last ingested record, ensuring exactly-once delivery. This behavior can be further controlled by the KafkaTableWriter Options.
KafkaConsumer Properties
You must create a Properties object for the KafkaConsumer. Persistent ingestion requires that auto-commit is disabled to ensure exactly-once delivery by setting the enable.auto.commit property to false. This setting allows the in-worker DIS, which is actually writing rows to disk, to also manage commits back to the Kafka broker. The broker will associate the offset for the ingester based on the supplied consumer group (props.put("group.id", "dhdis")). Any not-already-used name can be used for the Deephaven consumer group, but it may be necessary to update Kafka permissions on the broker side to allow the Deephaven consumer to manage its own consumer groups.
Below is an example of how to create a typical Properties object for a KafkaConsumer:
KafkaTableWriter Options
After creating suitable properties, the next step is creating an Options builder object for the ingestion and passing it to the KafkaTableWriter.consumeToDis function. The KafkaTableWriter.Options Javadoc provides a complete list of options.
Example Options for both fixed partitions and dynamic partitions are provided below.
Specifying record type and columns
For JSON-formatted Kafka records, a valueSpec is needed to indicate the names and types of columns to map from the record to the target table. Note the import of ColumnDefinition for the ofType specification methods.
Consume also provides record specification methods for Avro, protobuf, and raw Kafka records.
Schema Helper Tools
Options may be used to automatically generate, validate, add, or even modify a Schema. Modifying a schema is permitted, specifically, adding and removing columns, updating column groupings and symbolTable types, and updating partition key formula used for merging are valid operations. Schema updates may only occur before data is ingested to a given Partition. That is, once data has been written for a particular "Date", additional data cannot be added to the same "Date" if the schema is changed; a new "Date" is required for further ingestion (or the existing data must be removed).
The auto-generated schema may be updated to change the default values of columnType="Normal" to columnType="Grouping" by including the desired grouping column(s) with .withGroupingCols("GroupCol1", "GroupCol2"). Similarly, the default option of symbolTable="ColumnLocation" for String columns may be changed to symbolTable="None" with .withSymbolTableNone("StrCol1", "StrCol2"). The default partition key formula used for merging is ${autobalance_single}, which can be changed via .withMergeKeyFormula(...). These calls follow a basic builder pattern, so they can be called sequentially from each other.
Specifying the Data Import Server
The Options structure determines which of the Data Import Server configurations is used.
Use dhconfig dis to create an ad-hoc DIS. DISes can also be configured in the main data routing configuration.
You can specify the Data Import Server in three ways:
- Pass in the name of a Data Import Server and the path to its storage root using
disNameWithStorage. The referenced DIS must have "private" storage defined in the routing configuration. Like any Deephaven Data Import Server, the pathname you specify todisNameWithStoragemust be on local disk - network file systems are not suitable. - Pass in the name of a Data Import Server using
disName. The referenced DIS must have storage defined in the routing configuration. - Pass in a
DataImportServerobject typically retrieved withDataImportServerTools. If you are using the DataImportServer for multiple ingesters, then you must choose this method.
LastBy Tables
Often queries can be well-served by having the most recent (last) row for a given key immediately available. When dealing with large tables, such as a table of quotes, initializing the state for a lastBy requires reading the entire table. Particularly at the end of the day, this can take significant time. A Deephaven ingestion server can maintain an in-memory view of the last row for each table, with the last-row state persisted to the checkpoint record. The in-memory table can then be shared with other workers over Barrage. To enable a lastBy view of a Kafka table, invoke the .lastBy(KeyColumns) function on the Options object. The method for exporting lastBy tables from a Kafka ingester is the same as that for a Core+ binary log ingester.
For example, this adds a lastBy view for the instrument column to the ingester:
The Options structure lets you create multiple lastBy views, each with a different name by specifying .lastBy multiple times.
After calling the consumeToDis method, create a lastBy view of the table in memory with the LastByPartitionedTableFactory.forDataImportServer method. The resulting table can then be retrieved in other workers via Barrage or examined in the Deephaven web UI.
Function Transformations
Before writing the stream received from Kafka to disk, you may need to transform the received rows. For example, the Kafka stream might:
- Require a timestamp with a custom format to be converted to a Java Instant.
- Create a composite column from several other columns.
- Split a column into more meaningful fields.
- Rename columns.
- Filter out some rows.
To express these transformations, you must provide a Function from one Table to another with the transformation Option.
In the following example, the Instant column is created from the Timestamp column, and the column named NegateBool inverts the BoolValue column. We implement the function using a Groovy closure named `xf'.
The function may not increase the number of rows in the table. Offsets in the output table must be ascending, and every offset in the output must exist in the input. This has the effect of permitting you to filter rows or alter rows on a 1-1 basis, but does not allow performing more complex operations like grouping, or ungrouping.
When using dynamic partitions, the transformation function is applied before the partition for a row is determined so the resulting value can be used as input to the partition function.
Deephaven table partitions
Deephaven tables are partitioned in two ways. The first type of partitioning is that each table has a column partition, which is user-visible and can be used from queries. (Typically, the column partition is a "Date" column.) The second type of partitioning is an internal partition. The internal partition is not generally visible to users, and represents a single stream of data. For tables ingested from Kafka, the Deephaven internal partitions are automatically assigned with the format <topic>-<numeric kafka partition>.
The Kafka ingester supports two ways of determining column partitions:
- Fixed partitions are assigned for the life of the ingester.
- Dynamic partitions are determined as a function of the data.
Fixed partitions
To use a fixed partition, call the Options.partitionValue function. On startup:
- If the column partition already has data ingested, then the checkpoint record provides the offset of the next message. This step can be skipped by calling
Options.ignoreOffsetFromCheckpoints(true)when creating the ingestion options. - If
Options.resumeFromis specified, the prior partition is determined by invoking theresumeFromfunction with the current column partition. If a matching internal partition for the previous column partition is found with a checkpoint record, then the ingestion is resumed from that offset. - The Kafka broker is queried for committed values. If there is a committed value, ingestion is resumed from that offset. This step can be skipped by calling
Options.ignoreOffsetFromBroker(true)when creating the ingestion options. - Finally, the fallback function specified by
Options.partitionToInitialOffsetFallbackis called, and ingestion is resumed from the returned offset. The fallback function defaults to reading all data from the beginning of the topic, but can be configured to ingest only new data (or an arbitrary offset by providing your own function).
The following example ingestion script uses a long key and avro message from a schema registry and writes to the MyNamespace.MyTable partition for today().
Dynamic partitions
Dynamic partitions determine the column partition from a long column in the input data and a function passed to the Options.dynamicPartitionFunction method. This is suitable, for example, for turning a KafkaTimestamp column into a daily or hourly column partition value.
As the ingester starts up, it determines the Kafka offset to resume from using the following process:
- Existing column partitions for each internal partition are enumerated and sorted in lexicographical order. The most recent (i.e., highest sorted value) column partition's checkpoint record is read, and ingestion resumes from the Kafka offset found in that checkpoint record. This step can be skipped by calling
Options.ignoreOffsetFromCheckpoints(true)when creating the ingestion options. - The Kafka broker is queried for committed values. If there is a committed value, ingestion is resumed from that offset. This step can be skipped by calling
Options.ignoreOffsetFromBroker(true)when creating the ingestion options. - Finally, the fallback function specified by
Options.partitionToInitialOffsetFallbackis called, and ingestion is resumed from the returned offset. The fallback function defaults to reading all data from the beginning of the topic, but can be configured to ingest only new data (or an arbitrary offset by providing your own function).
When messages are consumed from the broker and parsed into Deephaven table rows, the column partition is computed for each row. Only one column partition is active at any time. When a row with a new column partition is ingested, the active column partition is durably committed to disk and the new column partition is opened. Because the existing partition is committed before the next partition is written (and on startup, the partitions are sorted in lexicographical order), the output of the dynamic partition function should be non-descending to avoid thrashing partitions or possibly missing messages on startup.
The TimePartitionRotation class provides convenience functions to map nanos since the epoch to either daily or hourly partitions. By default, a "slack" parameter is set to 30 days — times that are more than 30 days into the past or future are considered invalid and an exception is raised from the consumer.
Ingestion scripts for dynamic partitioning are identical to fixed partitioning, but instead of a partitionValue the dynamicPartitionFunction option is specified. In this example, the KafkaTimestamp column is used to create daily partitions using the London time zone. Timestamps that are more than one week (168 hours) are considered a data error.
Manual Routing Configuration
Instead of using dhconfig dis with private storage you may choose to manually configure the DIS in the routing YAML. This provides more flexibility at the cost of increased configuration complexity.
See dhconfig routing for help modifying the data routing file.
Configure a storage location
Add the location where the Kafka DIS process stores its intraday data. In this section, "KafkaImport1" is an arbitrary identifier, which is referenced later in the configuration file. The dbRoot path "/db/dataImportServers/KafkaImport1" is also arbitrary and not directly related to the identifier. This example assumes that the default /db entry exists in your routing yaml file.
Instead of specifying a storage location in the data routing file, you may instead use "private" storage and configure the location in your ingestion script.
Configure the new in-worker Data Import Server
Create a new entry in the dataImportServers section. Add claims for the tables that this DIS will handle. Deephaven recommends using dynamic endpoints for in-worker data import servers.
Note
See also: Add a Data Import Server to the data routing configuration
In this example, the KafkaImport1 DIS handles all tables in the “Kafka” namespace.
Note
The tailer port is not needed for data ingestion from Kafka. However, the tailer service is also used to send commands to the DIS, so disabling the port also disables those commands. This control functionality will not be available if the tailer port is disabled.
See our Importing Data guide for instructions to delete data directly from disk.
Change the table data service configuration(s)
The tableDataServices section defines how data is routed. One or more entries in this section may need to be adjusted so that query and merge workers source data appropriately. In this example, the table data cache proxy is configured in a way that does not require changes.
Configure Local Storage Routing
Local storage (reading directly from the disk where the process is running) is the default method for accessing historical tables' data files. It is also the default method when reading data to be merged from intraday to historical. The data routing table normally contains an entry called "local" that is used for these purposes. Since the in-worker DIS process used to consume Kafka topics has its own storage path, it needs its own local definition in the routing file. This can be combined with the original "local" or defined independently.
Note
When configuring an in-worker Data Import Server in Kubernetes, the storage is always private to the worker's pod. Therefore, you cannot use local storage for merge queries and must instead read the data through the running data import server in order to merge it to historical space.
(local includes original local and KafkaImport1):
(local is original local, and KafkaImport1 is referred to by kafka_direct):
Any entries defined here are available in the TableDataService selection dialogs when creating merge jobs:
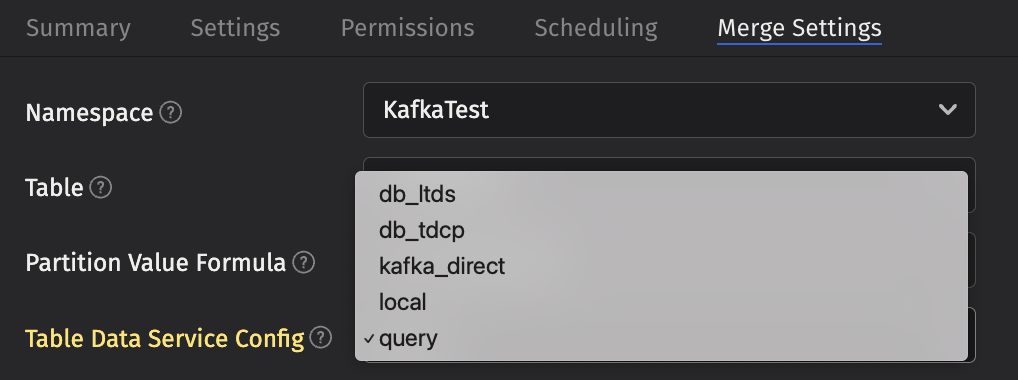
The above example corresponds to the routing entries that include original local (local) and kafka_direct. If desired, tags can be used to restrict which TableDataService entries are shown in the UI.
Note