Scaling to multiple servers
Deephaven is designed with horizontal scaling in mind. This means adding capacity for services typically involves adding additional compute resources in the form of servers or virtual machines.
When considering how to scale Deephaven, determine the types of capacity needed before adding resources.
Scaling capacities
Read capacity
- Queries requiring access to very large data sets might require more IO bandwidth or substantial SAN caching.
- Add more
Query Dispatcherprocesses with added IO bandwidth.
Write capacity
- Handling multiple near real-time data streams quickly (through the Deephaven binary log/
Tailer/DISarchitecture). - Expanding IO for batch data imports or merges.
- Large batch imports of historical data.
Query capacity
- Queries may take large amounts of memory to handle large amounts of data, a lot of CPU to handle intensive manipulation of that data, or both.
- Support for more end-user queries.
- Support for analysis of large datasets that may consume a smaller server's resources.
Server types
A single host may run multiple server types. For example, the administrative processes do not require many resources, and consequently may be co-located with other services.
Query servers
- Increase read and analysis capacity of the database for end-users.
- Large CPU and memory servers.
- Run the
Query Dispatcherand the spawned worker processes.
Real-time import servers
- Increase write capacity for importing near real-time data.
- Increase write capacity for merging near real-time data to historical partitions.
- Run the DIS and (optional) Local Table Data Service (LTDS) processes.
Administrative servers
- Run administrative Deephaven processes, such as the Deephaven controller, the authentication server, and the ACL write server.
Single server architecture
The Deephaven Installation guide illustrates the provisioning of a server with a network interface and the loopback interface (network layer), local disk storage (storage layer), and the Deephaven software (application layer) to create a single server Deephaven deployment. The guide uses this single server to perform basic operations by connecting to Deephaven from a remote client.
With that in mind, this single-server installation looks like the following:
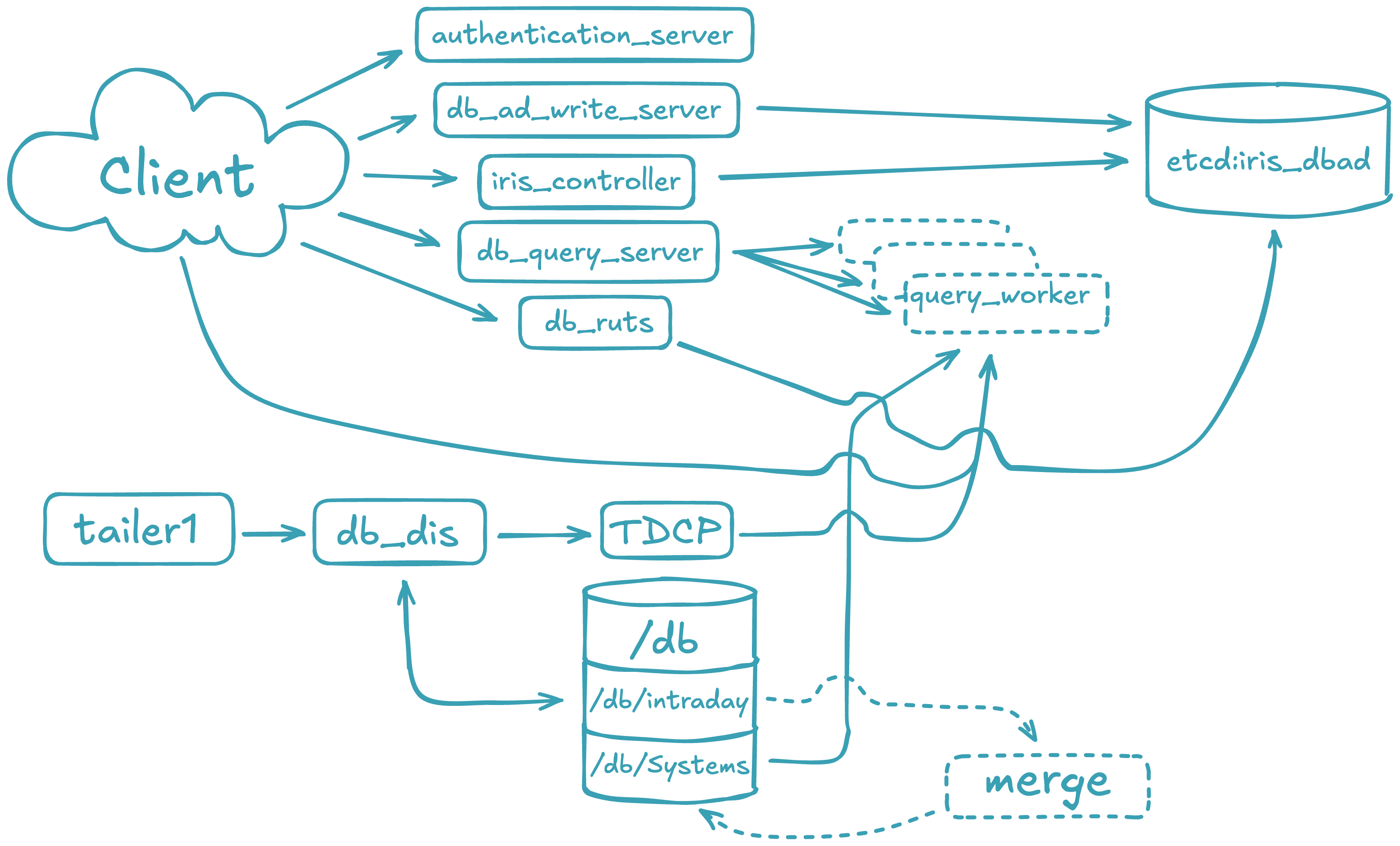
This fully functional installation of Deephaven is limited to the compute resources of the underlying server. As the data import or query capacity requirements of the system grow beyond the server's capabilities, it is necessary to distribute the Deephaven processes across several servers, converting to a multiple server architecture.
Multiple server architecture
The multiple server architecture is built by moving the network and storage layers outside the server, and by adding hardware to run additional data loading or querying processes. The network layer moves to subnets or vlans. The storage layer becomes a shared filesystem that is mounted across all servers. The application layer becomes a set of servers with the Deephaven software installed and configured to perform certain tasks.
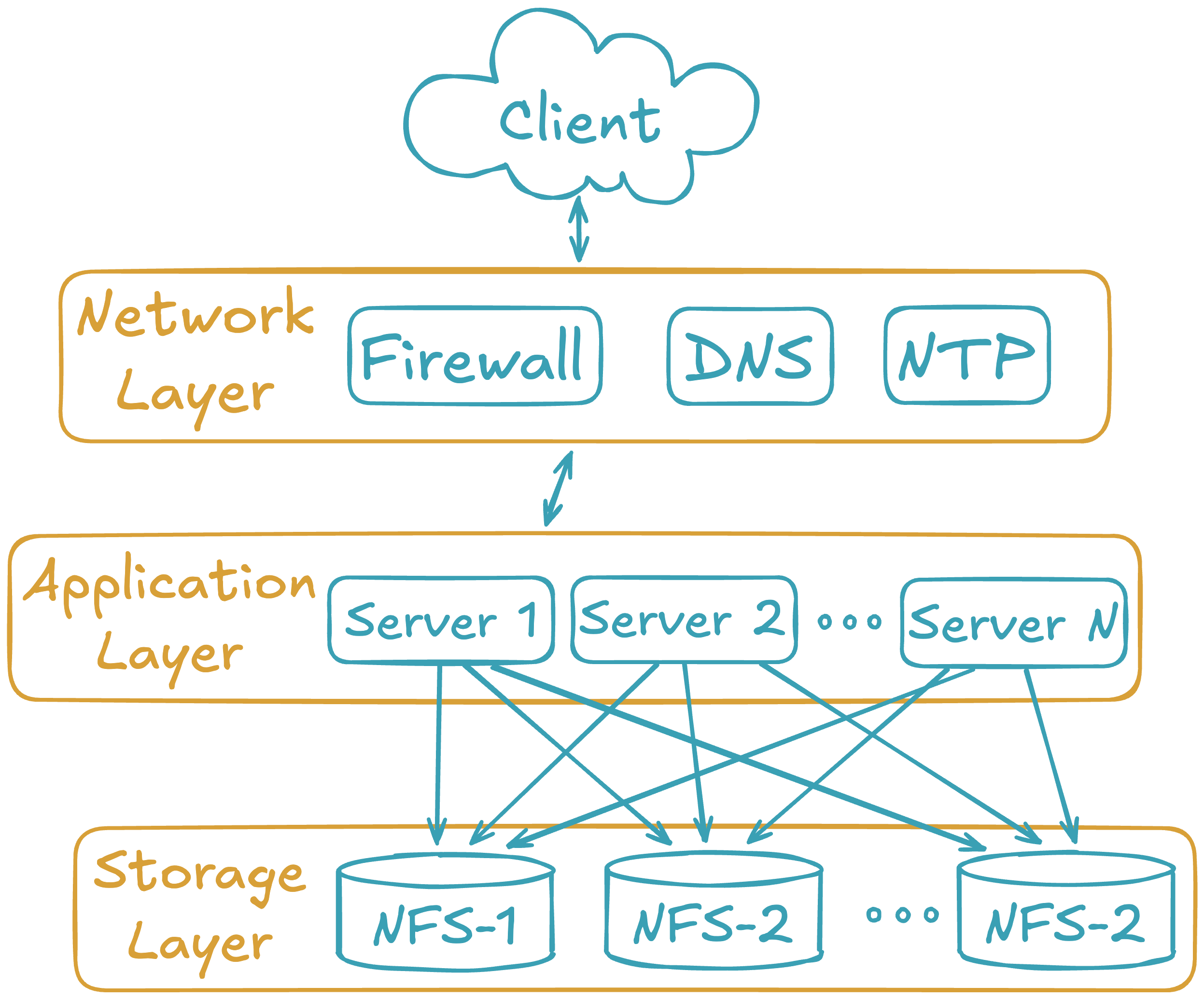
Deploying Deephaven on multiple servers has the following requirements:
- Modification of each layer in the three-layer model.
- Modification and management of the Deephaven configuration.
- Modification and management of the
dh_monitDeephaven configuration.
The network layer
The customer supplies the network and necessary services (DNS, NTP, etc.). This document does not cover configuration or implementation of the network, except to specify the network services on which Deephaven depends.
Deephaven requires a subnet or VLAN for the servers to communicate. Like all big data deployments, fast network access to the data will benefit Deephaven in query and analysis speed. If using FQDNs in the Deephaven configuration, a robust DNS service is also recommended.
The network layer should provide the fastest possible access to the storage layer.
The storage layer
The storage layer has the most changes in a multiple server installation. Deephaven requires access to a shared filesystem for historical and intraday data that can be mounted by each server in the Deephaven cluster.
Typically, these disk mounts are provided via the NFS protocol exported from a highly available storage system. Other types of distributed or clustered filesystems such as GlusterFS or HDFS should work but Deephaven has not extensively tested them.
As mentioned, Deephaven relies on a shared filesystem architecture for access to its data. Currently, the larger installations use ZFS filers to manage the storage mounts that are exported to the query and data import servers via NFS over 10g network interfaces.
Deephaven divides data into two categories:
- Intraday data is any data that hasn't been merged to historical storage partitions, including near real-time as well as batch-imported data. Depending on the data size and rate, the underlying storage should typically be high-throughput (SSD) or contain sufficient caching layers to allow fast writes.
Intraday data is written to the database via the Data Import Server or other import processes onto disks mounted on
/db/Intraday/<namespace>/. - Historical data is populated by performing a merge of the Intraday data to the historical file systems. As storage needs grow, further storage can be easily added in the form of writable partitions without the need to reorganize existing directory or file structures, as Deephaven queries will automatically search additional historical partitions as they are added.
Intraday data is typically merged to Historical data on the Data Import Servers during off hours by scheduled processes.
The historical disk volumes are mounted into two locations on the servers:
- For writing:
/db/Systems/<databaseNamespace>/WritablePartitions/[0..N] - For reading:
/db/Systems/<databaseNamespace>/Partitions/[0..N]
- For writing:
The Deephaven application layer
The software installation procedure for each server is documented in the Deephaven installation guide. Once the server is deployed, the network storage should be mounted on all the servers. Once this is done, you must manage the main Deephaven configuration and modify the dh_monit configuration to only run processes for each server type.
Users and groups
Deephaven requires three Unix users and five Unix groups that are created at install time by the installer. See Appendix B: Users and Groups in the installation guide for details.
Each server type is defined by the Deephaven processes it runs and the hardware resources required. You can combine server types on a single server given sufficient hardware resources. For instance, it is common to combine the administrative server with a Data Import Server.
Administrative server
Server Hardware and Operating System
- 6 cores (2 core minimum) @ 3.0 Ghz Intel
- 10GB RAM
- See Installation planning for supported operating systems
- Network: 1g
- Storage:
- Root - sufficient local disk space
Processes
authentication_server- Securely authenticates users on login.configuration_server- Serves configuration data to Deephaven processes.db_acl_write_server- Serves as a single writer for ACL information stored in etcd.iris_controller- Controller that manages Persistent Query lifecycles and provides discovery services to other clients for Persistent Queries.web_api_service- Provides the REST API for administrative operations.
Real-time Data Import Server
Server Hardware and Operating System
- 24 cores (6 cores minimum) @ 3.0 Ghz Intel
- 256GB RAM (32GB minimum)
- See Installation planning for supported operating systems
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Intraday data - SSD either local or iScsi
- Historical data - NFS mounts for all historical data
Processes
- DIS - receives binary table data from user processes and writes it to user namespaces, simultaneously serving read requests for same.
db_merge_server- merges intraday data to historical partitions.tailer1- reads data from binary log files written by Deephaven processes, and sends them to a DIS process for ingestion. Tailer configuration is covered in Deephaven Data Tailer.
Query server
Server Hardware and Operating System
- 24 cores (6 cores minimum) @ 3.0 Ghz Intel
- 512GB RAM (32GB minimum)
- See Installation planning for supported operating systems
- Network: 10g mtu 8192
- Storage:
- Root - sufficient local disk space
- Database mount - 250GB SSD mirror local
- Historical data - 16 NFS mounts @ 35TB each
Processes
db_query_server- manages query requests from clients and forks query worker processes to do the actual work of queries.db_tdcp- Table Data Cache Proxy that caches table data locally and provides efficient data access between workers and data sources.