Symbol Tables and Caching
Deephaven uses symbol tables to increase the performance of queries that involve string columns. A symbol table maps each unique value in a string column in a Deephaven table to an ID (a 4-byte signed integer). By using a fixed-width ID for each unique "symbol" in the column, Deephaven can:
- Save space on disk
- More efficiently access data
Symbol tables are created automatically — you don't need to do anything to enable them. This guide is primarily for understanding when symbol tables may hurt performance and how to disable them for specific columns using symbolTable="None" in your schema.
Symbol tables work by storing a *.dat file that tells Deephaven which string value (as the unique ID) is at a particular location. Deephaven then uses that value to look up the symbol offset in an offset file. The offset file tells Deephaven the byte address of the actual value in the symbol file, enabling Deephaven to look up the string value for a given ID quickly.
When to disable symbol tables
Symbol tables improve performance when the same string values repeat frequently. They hurt performance when:
- Values are mostly unique — columns like order IDs, UUIDs, or log messages where each value appears only once or twice.
- Cardinality approaches row count — if a column has nearly as many unique values as rows, the symbol table adds overhead without compression benefit.
- Values cycle beyond the cache window — if values repeat, but at intervals larger than the bounded cache size (default 10,000), the same string gets assigned new IDs repeatedly, rapidly exhausting the 2-billion ID limit.
To disable symbol tables for a column, add symbolTable="None" to the column definition in your schema:
Tip
Use the audit script to identify columns with poor symbol table efficiency. If the Efficiency ratio is well below 1.0, or if Values is close to the table's row count, consider disabling the symbol table.
Caching mechanics
The effectiveness of symbol tables is closely tied to caching mechanisms. These include symbol managers and string caches.
Symbol managers
Most string columns have a limited universe of distinct values, and hence benefit from using a symbol table as part of their storage format. When writing a column with a local symbol table, a symbol manager is used to cache the symbol indexes assigned to distinct string values.
There are two types of symbol managers used for this purpose:
- Strict symbol managers guarantee a one-to-one mapping from distinct value to symbol index. They must hold the full reverse mapping in memory when actively in use, but produce the most compressed output. They are suitable for columns with a small (less than 1 million), well-understood number of distinct values, such as equity tickers or option symbols in a table of quotes or trades.
- Bounded symbol managers cache a limited number of one-to-many mappings from distinct value to symbol index in memory when actively in use. In order to guarantee deterministic output at replica nodes, they use a FIFO (first-in-first-out) cache eviction policy. They are suitable for columns with a large number of distinct values, where there is expected to be some locality of reference, such as order identifiers in a table for an order management system. The following property defines the FIFO window size for all bounded (non-strict) symbol managers:
LocalAppendableTableComponentFactory.boundedSymbolManagerSize. The window size defaults to 10000. However, increasing this value is recommended if it is known that column values will repeat at a larger interval.
Caution
Symbol managers may only store approximately 2 billion mappings, because the symbol indexes must be less than the maximum array size in Java. Trying to store a mapping to an index higher than 2,147,483,646 = 231-2 will result in an UnsupportedOperationException.
String caches
Reading and writing from/to columns of string values usually involves a cache, in an attempt to reduce the total number of (possibly long-lived) objects created in the system. For writing processes (like the Data Import Server, offline or "batch mode" imports, or the merge process), cache selection has an impact on symbol manager selection, heap usage, and output size.
When an unbounded string cache is selected for a given appendable column of strings configured to use a local symbol table, the writing sub-system will use a strict symbol manager. In all other cases bounded symbol managers are used, with a FIFO window as mentioned above.
How bounded caches work
Bounded string managers work as follows. For string columns, a symbol table maps symbols to an ID, an integer offset. The field value for the Symbol ID (a 4-byte signed integer) is fixed width; this not only saves space if the same string is written multiple times, but allows for efficient random access. A fixed width symbol ID allows Deephaven to compute the byte index of the data we need to read from the row index, and read just those bytes without performing an O(n) sequential read or O(log n) lookup in a sorted data structure. Note that columns with encodings that are variable width or multi-byte are unable to use compressed strings. If such a column matches a cache of compressed strings, a default will be substituted.
For example, let's say you have 6 strings: A, B, C, D, E, F, but you have a Symbol Manager whose cache can only hold 5 items.
Your symbol table will initially include:
| ID | String |
|---|---|
| 0 | A |
| 1 | B |
| 2 | C |
| 3 | D |
| 4 | E |
If new strings come in as "A A B A B C D E", then "0 0 1 0 1 2 3 4" is logged on disk for the column. If a row for "F" comes in, it cannot fit in the symbol table because it is the sixth item; there is only room for five. The Symbol Table must drop an item, and it does so by following the "First In, First Out" (FIFO) rule: whatever was added to the cache first is removed, not whatever was least recently used. In this case, the Symbol Table removed "A."
Now our table looks like:
| ID | String |
|---|---|
| 5 | F |
| 1 | B |
| 2 | C |
| 3 | D |
| 4 | E |
As the table continues to update with new data, let's say we get another row with 'A'. It needs to be put back in our table, which means we have to remove another item, in this case 'B'. Because 'A' appears like a new string, it is assigned a new ID (now it is 6, not 0).
| ID | String |
|---|---|
| 5 | F |
| 6 | A |
| 2 | C |
| 3 | D |
| 4 | E |
Tip
It's important to set a reasonable value that your cache can hold. However, depending on the order of the source data, the same string could be read into the cache with a different ID multiple times. In this case, a symbol table is probably ineffective. For example, with a dataset like A B C D E F A B C D E F A B C D E F, the same string will be frequently assigned a new ID if the cache only holds five items. IDs can count up to 2 billion very quickly, which exceeds the maximum amount of mappings that can be stored. To avoid this, include symbolTable="None" in your schema.
Deephaven does not have an unbounded cache by default because tables with non-repeating string data (e.g. ProcessEventLog) would very quickly exhaust available system resources resulting in process termination (which is of particular concern for long-running processes such as the DataImportServer).
Cache configuration
Data Import Server cache hints
Users should carefully consider which columns have a well-known universe of possible distinct values, and configure cache hints accordingly. If the cycle where data may repeat is long, configuring a larger bounded symbol manager size is appropriate/advisable. If your column's data is unlikely to repeat, or unlikely to repeat more than a small handful of times over the course of a partition, you should include symbolTable="None" in your schema and disregard cache hints for the column in question.
The Data Import Server uses a series of cache hints (specified via properties) to determine string cache selection. It is possible to specify a global default, as well as column and table name specific caches, allowing sharing across tables in some cases to minimize overall heap usage at the expense of concurrency. This hint system allows Unbounded, Bounded, and "Always Create" caches to be specified. "Always Create" (or "No-Op") makes a new string in each instance, rather than caching the data.
Note
Note that MergeData and other write jobs are also able to use hint-driven StringCacheProviders. The "default" StringCacheProvider is "unbounded," thereby triggering strict symbol manager usage.
To configure cache hints, use the following syntax:
The components are defined below:
| Component | Description |
|---|---|
match-specifier | Determines which columns the hint applies to. Options include default, tableNameEquals.<name>, tableNameStartsWith.<prefix>, columnNameEquals.<name>, columnNameStartsWith.<prefix>, and tableNameAndColumnNameEquals.<table-name>,<col-name>. |
cache-type | The type of cache to use. Options are ConcurrentUnboundedStringCache (shared, unbounded), ConcurrentBoundedStringCache (shared, bounded), and AlwaysCreateStringCache ("no-op" cache). |
value-type | The data type, either String or CompressedString. |
arguments | Varies by cache type. For ConcurrentUnboundedStringCache, it's the number of stripes. For ConcurrentBoundedStringCache, it's the number of stripes and the maximum cache size. |
The following examples illustrate the hint types and when to use them.
Table name and column name exact match
Use this when a specific column in a specific table has known, predictable cardinality. Here, the Exchange column in OptionQuotes has a small, fixed set of exchange codes, so an unbounded cache ensures strict symbol management with optimal compression:
Column name exact match
Use this to apply consistent caching to a column that appears across multiple tables. Here, all Exchange columns get a bounded cache of 100,000 entries — appropriate when exchanges are consistent but you want to limit memory usage:
Column name prefix match
Use this for columns following a naming convention. Here, all columns starting with Sym (e.g., Symbol, SymbolRoot) use an unbounded cache with compressed strings — ideal for ticker symbols with a well-known universe:
Table name exact match
Use this to tune all string columns in a specific table. Here, the Quotes table gets a large bounded cache (1 million entries) — useful when the table has multiple high-cardinality columns with good locality:
Table name prefix match
Use this for groups of related tables. Here, all tables starting with Market share compressed string handling with a 1-million-entry cache:
Default
The default hint applies to all columns not matched by more specific hints. Using AlwaysCreateStringCache disables caching entirely — appropriate when most columns have unique values and caching would waste memory:
Offline importers and merge
In the current version of Deephaven, all Deephaven Data Labs-provided importers, as well as the merge process, use a global default string cache for all output columns.
The size of this cache is specified by the following property, which bounds the cache of strings that will be stored:
Note
This deprecates BinaryStore.stringCacheSize as of Deephaven v.1.20180430.
This property must be passed to the worker/process running a given import or merge. This can be accomplished by adding -DStringCacheProvider.defaultStringCacheSize=-1 to the process arguments when executing the import or merge class, or to the Extra JVM Arguments (Advanced Settings) in an import or merge Persistent Query configuration. The value above, -1, means that all strings should be cached indefinitely, and all symbol managers should be strict.
Audit symbol table efficiency
Symbol table efficiency largely depends on the ratio of the cardinality of the symbol table to the size of the Deephaven table it is associated with. For instance, a symbol table with 100 unique IDs for a Deephaven table with 100 million rows will be more performant than a symbol table with 100 thousand unique IDs for a Deephaven table with 10 million rows.
Symbol tables can negatively affect performance if used in the wrong contexts. For instance, consider a symbol table with a cardinality greater than the size of the Deephaven table it's associated with. In such a case, the DIS creates multiple IDs for each symbol. This results in a higher disk usage, which can negatively impact the performance of queries that need to read additional data.
The following code block audits the symbol table efficiency of a table:
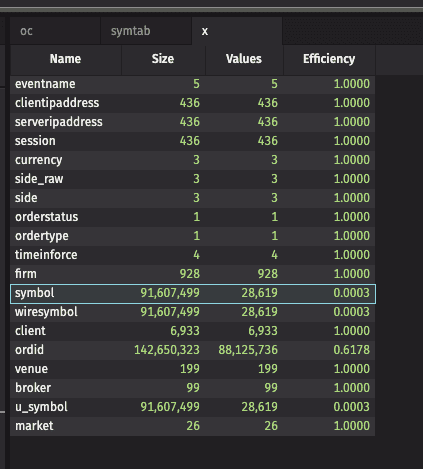
The query produces a table with one row per symbol table column. The table has the following columns:
Values: the number of distinct values exist for that column.Size: the size of the on-disk symbol table.Efficiency: the ratio ofValuestoSize, which is ideally 1.00 (or 100%) for a single partition. When you have tables with multiple partitions, the symbol tables are independent.
You may also see that the number of Values is close to the size of the input table, in which case a symbol table column may not be appropriate (as is often the case for order IDs).
Consider the screenshot below. The symbol, wiresymbol, and u_symbol columns show an efficiency of 0.03%, which is very low. Adjusting the DIS cache hints to allow sufficient headroom for the roughly 30,000 unique values is likely to improve query performance. Additionally, the ordid column is a symbol table column, but it has over 88 million unique values. Queries and ingestion are likely to be more efficient by changing the schema to include symbolTable="None".
Best practices
- Use symbol tables for columns with repeating values (e.g., stock tickers, status codes). They are highly efficient when the number of unique values (cardinality) is much smaller than the number of rows.
- Avoid symbol tables for columns with unique values (e.g., timestamps, order IDs). High cardinality can make symbol tables inefficient. Use
symbolTable="None"in your schema for these columns. - Choose the right Symbol Manager: Use
Strictmanagers for columns with a known, small set of unique values. UseBoundedmanagers for columns with many values but good data locality. - Audit regularly: Use the provided scripts to check symbol table efficiency. A low efficiency ratio (<< 1.0) indicates that your cache is too small and needs tuning.