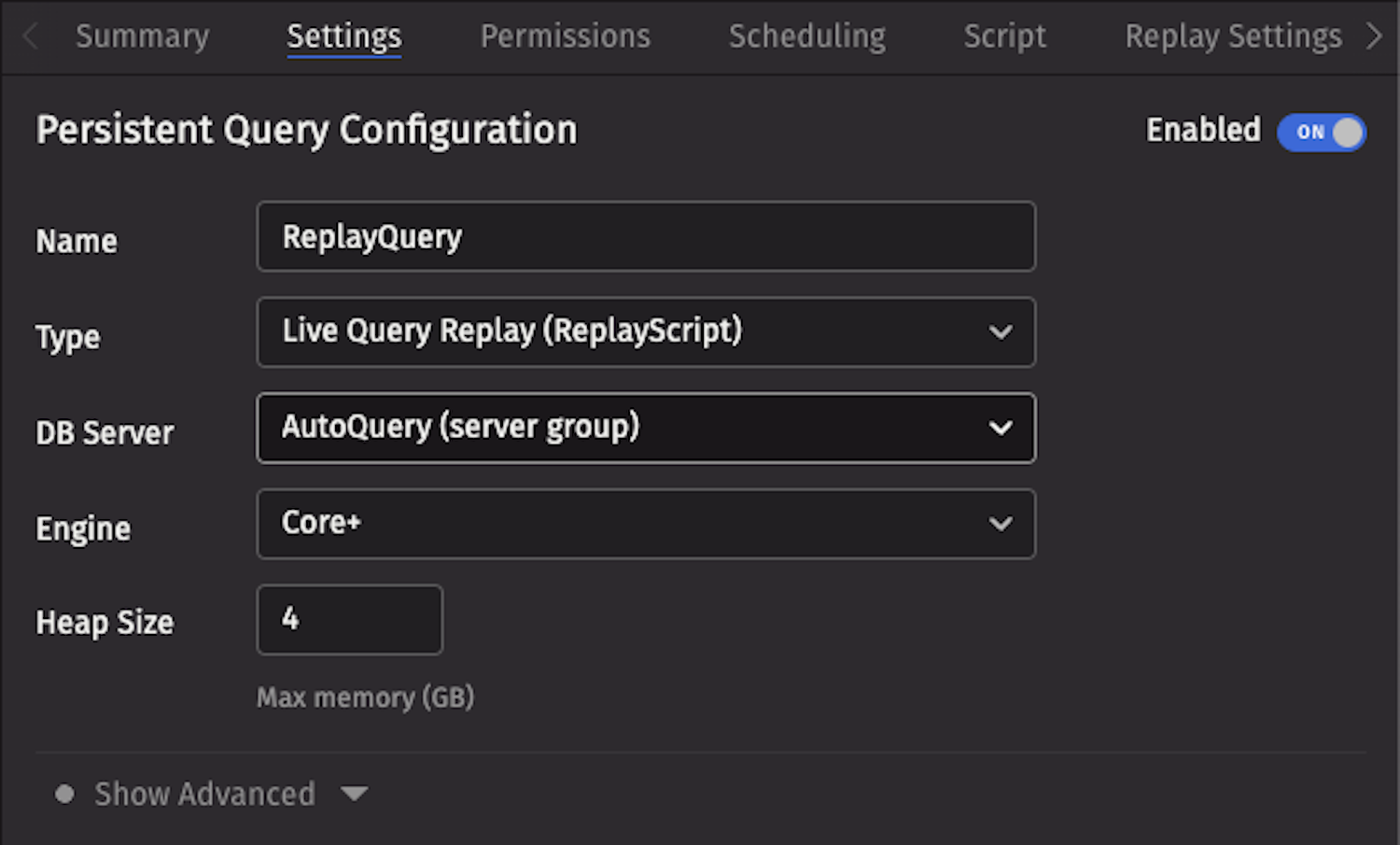
Create a replay query
This guide shows you how to create a Replay Query, a Persistent Query (PQ) that replays historical table data as ticking intraday data. Among other things, this is useful for:
- Testing changes to a script against known data.
- Troubleshooting issues that a query had on a previous day’s data.
- Stress testing a query by replaying a large data set at faster speed.
- Simulating data ticking into a table.
The value of the Deephaven system clock, currentClock, is set to a simulated clock created using the query's replay settings. Calls to today, pastBusinessDate, etc. will return values based on the configured replay time, date, and speed. The timeTable and WindowCheck functions also use simulated clock.
By default, Replay Queries redirect the db.live_table command to load the historical version of the table (db.historical_table) instead. They also apply a special where clause on the table's timestamp column that releases rows based on the configured clock. This allows you to take an existing query that uses intraday data and execute it on historical data instead.
To create a Replay query, click the +New button in the Query Monitor and select the type Live Query Replay (ReplayScript).
Replay settings
Configure the query in the Replay Settings tab.
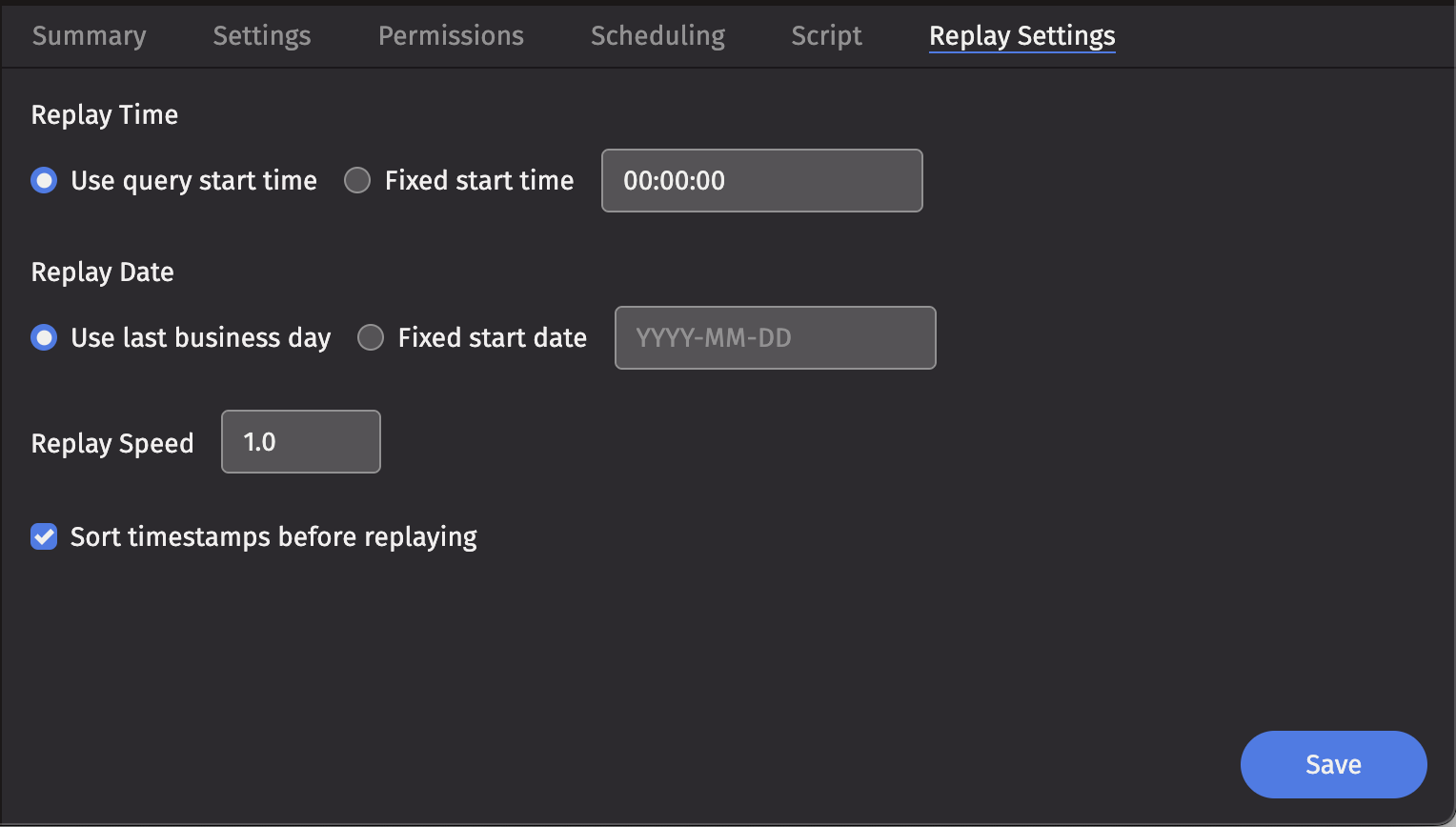
The parameter options are detailed below.
Replay time
The Replay Time configuration provides two options that control the time of day that the script will begin.
- Use query start time - The query executes using the current time of day.
- Fixed start time - The query executes using this value as the current time of day. The format is
HH:MM:SS.
This is useful if you need to replay data that was initially streamed in a different time zone than the one you are testing in.
Replay date
The Replay date option determines what date is returned by date-related methods in your query, such as:
today()minusBusinessDays(today(), 1)
If you do not specify a replay date, the system uses the last business day from the default calendar by default.
You can set the replay date to simulate running your query as if it were a different day. This is useful for testing scripts against historical data or reproducing past scenarios.
Replay speed
The Replay Speed option controls the rate at which data is replayed. This is useful if you want to replay data at a higher speed to simulate a greater data load or process a day quicker. A replay speed of 0.5 would replay value at half speed, while a replay speed of 2 would replay data at double speed.
Sorted replay
The Sorted Replay checkbox guarantees that the data is replayed in Timestamp order - that is, in the order of the table, sorted by the configured timestamp column.
Caution
Enabling Sorted Replay on input data that is not sorted on a timestamp column leads to undefined results.
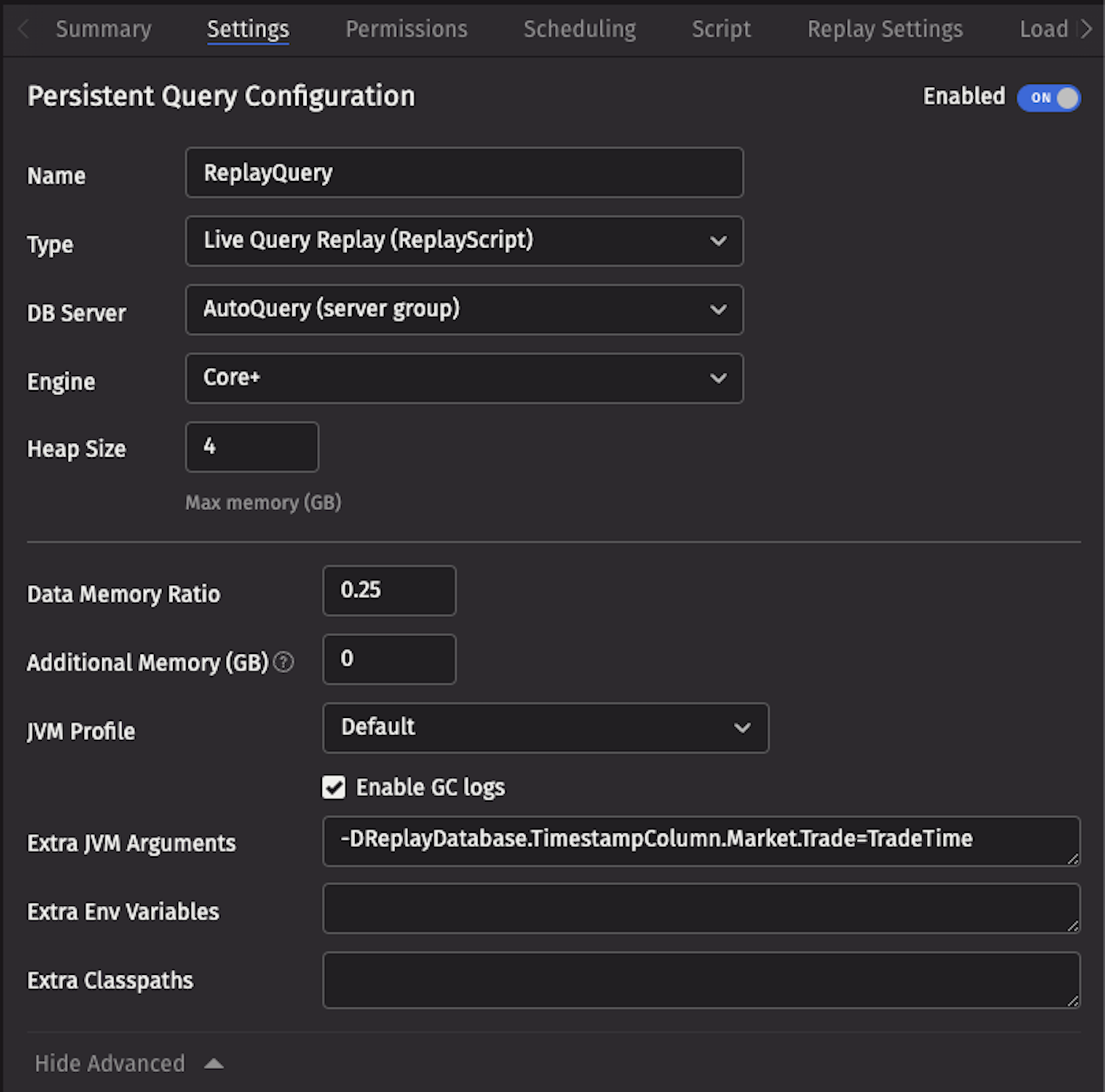
Additional JVM arguments
JVM arguments provide advanced configuration options for Replay Queries. These arguments can be added in the Extra JVM Arguments field when creating or editing a Replay Query.
Timestamp column
A Replay Query assumes that the replay timestamp column in all tables is Timestamp unless configured otherwise. If a table has only one column of type Instant, the Replay Query will automatically use it as the replay timestamp.
If your table has a timestamp column that is not named Timestamp, add the following argument to the Extra JVM Arguments field:
For example:
Persistent Query type-specific fields
When creating a replay query using a client rather than the UI, you must set the configurationType field to ReplayScript and manually configure the replay settings. These settings are stored in the typeSpecificFieldsJson of the PersistentQueryConfigMessage protobuf that represents the Persistent Query. Configuration settings specified with -D<key>=value arguments must be included in the extraJvmArguments field.
Each field of the type-specific fields JSON is a map that includes a type and a value.
| Field Name | Type | Default | Example | Notes |
|---|---|---|---|---|
ReplayDate | string | - | 2025-05-17 or lastBusinessDateNy() | Must be a date in the form YYYY-MM-DD or the constant lastBusinessDateNy() for the prior New York business date as reported by Legacy lastBusinessDateNy(). |
ReplaySpeed | string | 1.0 | 2.0 | The string is parsed into a numeric value using Double.parseDouble(). |
ReplaySorted | boolean | - | true | |
ReplayStart | string | - | now or 04:00:00 | If the constant now is specified, then the query starts replay at the current time of day. Otherwise, the start of the replay is the time specified by HH:mm:ss. |
The following example JSON starts the replay at 4AM using yesterday's data, playing data that is assumed to be sorted at double speed:
In this example JSON, data from May 17, 2024 is played at real-time speed, starting at the current time, without assuming the data is sorted:
Script
Replay historical data
The simplest use case for a Replay Query is to replay a historical data set in an existing query script. If your script already uses the Deephaven built-in date methods (such as today() or now), then you will not need to do any additional work to select the appropriate date partition for replay. If not, ensure it selects the correct playback date by hand.
For example, if you have any hardcoded dates:
You will need to change the .where() clause manually. It is generally good practice to store the date in a local variable and reuse it throughout your query, so it is easy to change:
Save your query and your data will be replayed to the query script.
Simulate intraday data with replay
While it is often useful to simply replay historical data to a script, it may also be helpful to use a historical replay to simulate current intraday data. This example shows how to use the SystemTableLogger to re-log table data and transform timestamps to match today’s date and time. This allows you to run unmodified queries against simulated data with a little bit more complexity and configuration.
Say you want to simulate data from the following table:
You could replay data directly back to the table above; however, it is best practice to separate simulated or replayed data from actual production data.
-
Create a Schema for Simulated Data
- Define a CopyTable schema with a new namespace. This ensures replayed data does not mix with your original data.
- Example schema definition:
- Deploy the schema using
dhconfig schemas). This will add a new system table to Deephaven under the namespaceMarketSim.
-
Create and Configure the Replay Query
- Write a script that:
- Pulls the table from the original namespace.
- Logs the table and its updates back to a binary log file.
- Write a script that:
Simulate intraday data with timestamp shifting
If your table contains any columns that are Instant columns, you will probably want to convert these into values with the current date, but the same original timestamp. This example replays the table to the MarketSim namespace and also converts every Instant column it finds to the current date at the same time: