Streaming Kafka
This section of the Crash Course guides you through ingesting a single Kafka topic into the Deephaven system as intraday data. This process leverages an in-worker Data Import Server (DIS) and makes the data accessible to other users via db.live_table. It also provides a foundation for ingesting multiple Kafka topics into Deephaven.
Prerequisites
This guide assumes you have access to a Kafka cluster or a testing environment where Kafka can be deployed. Kafka administration is outside the scope of this document.
Administrative Configuration
Before starting, a system administrator must:
-
Add the DIS to the system configuration. Here, we show a simplified DIS configuration using claims; more advanced routing configuration is outside the scope of this guide. This example illustrates adding a DIS named
KafkaDis1and claiming the tableExampleNamespace.ExampleTableName: -
Create a data storage location (
dbRoot) for the DIS on the relevant Merge Server. By convention, this is typically created under/db/dataImportServers/<disName>, but other locations can be used. While multiple DISes can technically share adbRootdirectory, it is recommended that each DIS be assigned its own dedicated directory. For merge jobs to function correctly, ensure thedbRootdirectory is owned by thedbmergeuser anddbmergegrpgroup.
Persistent Query Configuration
Only users belonging to the iris-datamanagers, iris-dataimporters, or iris-superusers groups (see special groups for details) can create the in-worker DIS as a Persistent Query (PQ) within Deephaven.
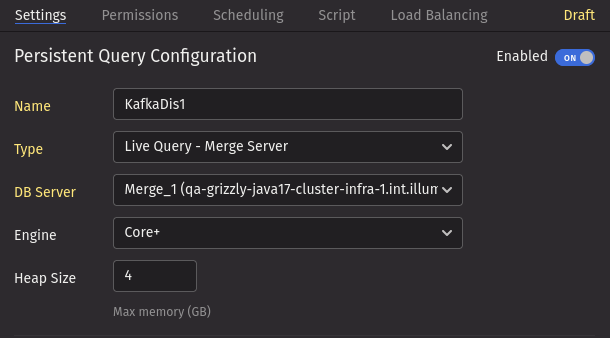
Create a new PQ in the web UI with the following settings:
- Name: By convention, use the name of your DIS configuration, although any name is technically acceptable.
- Type: "Live Query - Merge Server"
- DB Server: Specify the Merge Server where the
dbRootdirectory was created.
Next, create the script. The following code snippet outlines the basic configuration to launch an in-worker Kafka DIS.
Crucially, the keySpec and valueSpec parameters must be defined. These parameters describe the format of the Kafka topic's key and value data. In this example, we've ignored the topic's key and will parse the value data directly as a simple string, assigning it to a column named "Value". Deephaven has built-in support for JSON, Avro, and Protobuf data from Kafka, as well as support for custom formats.
The code also includes an optional SchemaHelper, which serves two purposes:
- Add Schema: If no schema exists for
ExampleNamespace.ExampleTable, the derived schema will be added to Deephaven. - Schema Validation: If a schema exists for
ExampleNamespace.ExampleTable, the derived schema will be checked for compatibility against the existing schema.
If the SchemaHelper is not used, the schema must already have been created.
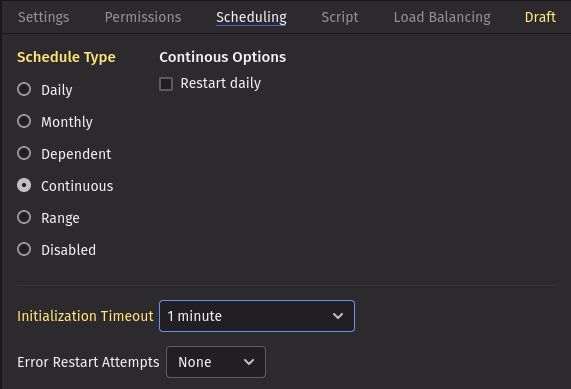
Next, configure the scheduling. By default, PQs are scheduled to run with the Schedule Type "Daily", which is often inappropriate for Kafka DISes. To enable continuous data ingestion from the Kafka topic, change the Schedule Type to "Continuous" and set an initialization timeout.
For more advanced PQ configuration, refer to the Deephaven documentation creating Persistent Queries.
Further considerations
The optimal setup for in-worker Kafka DISes varies significantly based on data volume and operational requirements.
Dedicated DIS
A Dedicated in-worker Kafka DIS refers to a configuration where a single DIS instance is solely responsible for consuming data from one specific Kafka topic. This approach offers a couple of advantages:
- Ideal for High-Volume Topics: Particularly suitable for consuming high-volume Kafka topics.
- Enhanced Resource Isolation: Provides better resource isolation. Restarting a dedicated DIS will only affect the associated topic and its corresponding live table, minimizing disruption to other data streams.
You can enhance performance for extremely high-volume Kafka topics by configuring a single dedicated DIS to consume data in parallel from multiple partitions of the same topic. This is achieved by utilizing the partitionFilter option within KafkaTableWriter.Options to specify the desired partition assignments for each consumeToDis call.
Shared DIS
A Shared in-worker Kafka DIS refers to a configuration where a single DIS instance is responsible for consuming data from multiple Kafka topics. This approach can be considered for scenarios involving:
- A large number of low-volume Kafka topics.
- A moderate number of medium-volume Kafka topics.
- A small number of high-volume Kafka topics.
This is achieved by including configurations for multiple Kafka topics within the PQ script and calling consumeToDis for each topic within that script.