Ingest JDBC data into system tables
This guide demonstrates how to generate a schema from a SQL query ResultSet, deploy it, and ingest data from JDBC sources using the command line. These commands assume a typical Deephaven installation, a SQL Server source database, and a SQL Server table created as follows:
After creating the table, you can populate it with some sample data. For example:
Deephaven offers tools to infer a table schema from JDBC and import data using a JDBC interface. Both schema inference and data imports work with a JDBC ResultSet rather than directly with the source table. Fortunately, most JDBC drivers include detailed metadata in the ResultSet, allowing standard SQL types to be accurately mapped to Deephaven column types.
JDBC Data Source Support
When using JDBC data sources with command-line tools or data import classes, you can specify any driver class string and connection URL. The schema discovery and data import processes rely on standard JDBC functionality, so most drivers are compatible. However, for schema discovery to work, the driver must provide ResultSetMetaData for the query result set. Some drivers may lack this capability.
The Legacy Schema Editor simplifies the process of creating and editing schemas by allowing you to make and validate changes to the schema in a graphical user interface. The Schema Editor UI also provides a way to generate a schema from a JDBC query. The Schema Editor UI is available in the Deephaven Web UI and can be accessed by clicking on the Schemas tab.
For JDBC, a limited set of data sources are currently available in the Schema Editor:
- MySQL/MariaDB
- Apache Redshift
- Microsoft SQL Server
- PostgreSql
These data sources have been tested and their typical drivers are known to support features needed for schema discovery and data import.
In some cases, you may need to consult the data source's product documentation for specific instructions on connecting via a JDBC driver. For example, the data source might need to be reconfigured to allow username and password authentication from the Deephaven merge server where the import process or Schema Editor is running. Additionally, some drivers have unique requirements for the connection URL. For instance, Postgres requires the database name to be included in the connection URL, whereas MySQL does not.
Note
When using recent versions of the Microsoft SQL Server driver and using self-signed certificates for SSL connections, you may need to add trustServerCertificate=true to your connection URL to avoid certificate validation errors. For example, jdbc:sqlserver://1.2.3.4; trustServerCertificate=true ensures that the driver trusts the self-signed certificate.
Schema Preparation
This section outlines the necessary steps to prepare a schema, which must be completed before attempting to ingest data using either the command-line interface or the Web UI.
Generate a schema
See the Schema inference page for a guide on generating a schema from a JDBC query.
For example, to generate a schema for a table named Trade in the ExNamespace namespace from a SQL Server database, you could use a command like this:
This command will create a schema file named ExNamespace.Trade.schema in the /tmp directory. You would then deploy this schema using the dhconfig schema import command as shown in the next step.
Deploy the schema
Command-Line Import with iris_exec jdbc_import
JDBC imports can be performed directly from the command line using the iris_exec tool. This method is suitable for scripting and batch processing. Ensure you have completed the Schema Preparation steps before proceeding.
General Syntax
sudo -u dbmerge /usr/illumon/latest/bin/iris_exec jdbc_import <launch args> -- <jdbc import args>
Example Import Command
The following example imports data from the JDBC source into the specified intraday partition, using the schema file generated in the previous step.
This example imports data into the ExNamespace.Trade table, using a schema that was previously generated (e.g., via schema_creator which would place the schema file in a directory for the namespace) and deployed. Once the schema is deployed, this command can be used to import data from the JDBC source.
JDBC Import Arguments
The JDBC importer takes the following arguments:
| Argument | Description |
|---|---|
| Either a destination directory, specific partition, or internal partition plus a partition column must be provided. A directory can be used to write a new set of table files to a specific location on disk, where they can later be read with TableTools. A destination partition is used to write to intraday locations for existing tables. The internal partition value is used to separate data on disk; it does not need to be unique for a table. The name of the import server is a common value for this. The partitioning value is a string data value used to populate the partitioning column in the table during the import. This value must be unique within the table. In summary, there are three ways to specify destination table partition(s):
|
-ns or --namespace <namespace> | (Required) Namespace in which to find the target table. |
-tn or --tableName <name> | (Required) Name of the target table. |
-om or --outputMode <import behavior> | (Optional):
|
-rc or --relaxedChecking <TRUE or FALSE> | (Optional) Defaults to FALSE. If TRUE, will allow target columns that are missing from the source JDBC to remain null, and will allow import to continue when data conversions fail. In most cases, this should be set to TRUE only when developing the import process for a new data source. |
-sn or --sourceName <ImportSource name> | Specific ImportSource to use. If not specified, the importer will use the first ImportSource block that it finds that matches the type of the import (CSV/XML/JSON/JDBC). |
-jd or --jdbcDriver <class name> | Class name of the driver to load to connect to the data source. See below for more details. |
-cu or --connectionUrl <JDBC URL> | Information needed to find and connect to the data source. See below for more details. |
-jq or --jdbcQuery <query string> | The full query string to execute against the data source. In most cases, this will need to be delimited with double-quotes. |
The schema of the target table will be used to select default setters for the transformation of incoming data if there are no ImportColumns to provide other instructions. For example, if the source column is a string, but the Deephaven table column is designated as integer, the importer will attempt to cast the data as integer.
- The driver will need to be available from the
classpathof the importer.- Examples of driver classes are:
com.microsoft.sqlserver.jdbc.SQLServerDriverfor Microsoft SQL Servercom.mysql.jdbc.Driverfor MySQL
- Examples of driver classes are:
- The
connectionURLwill include things like server name, port, authentication, etc, that will vary depending on the type of data source being used. - An example of a SQL Server URL for a local, default instance, using integrated Windows security, might be something like the following:
jdbc:sqlserver://localhost:1433;databaseName=Sample;integratedSecurity=true
- Other sources may be a bit different. For example, a sample MySQL
connectionURLfollows:jdbc:mysql://localhost:3306/Sample?user=root&password=secret
The SQL query format will also vary depending on specific language capabilities and expectations of the data source. However, the resultant columns should match the column names in the target table. Most SQL dialects will allow columns to be calculated or labeled as part of the query, and the importer will match columns based on the resultant labels. Rather than just directly matching result set column names to target table column names, another option is to add transformation metadata to the Deephaven schema. This allows the user to specify options like a different source column name, a different source column data type, whether a column can be null, and even custom transform functions to use during the import. See the general importer topic for a sample of schema for an import target table.
In addition to column translation features of the CSV importer, the JDBC importer will perform special handling when the source column is a Date type (JDBC DateTime, Date, or Timestamp), and the destination is an Instant. This handling will attempt to do direct conversion between date values.
Warning
After completing a JDBC import, you must run a rescan command for the imported data to become available in Deephaven. The Data Import Server (DIS) will not automatically detect the new data.
Run this command to rescan a specific table:
See the Data control tool rescan documentation for more details.
JDBC Import Query
Note
Ensure you have completed the Schema Preparation steps before configuring a JDBC Import Query.
A JDBC Import Query may also be created and configured in the Deephaven Web UI. To create a JDBC Import query, click the +New button above the Query List in the Query Monitor and select the type Import - JDBC.
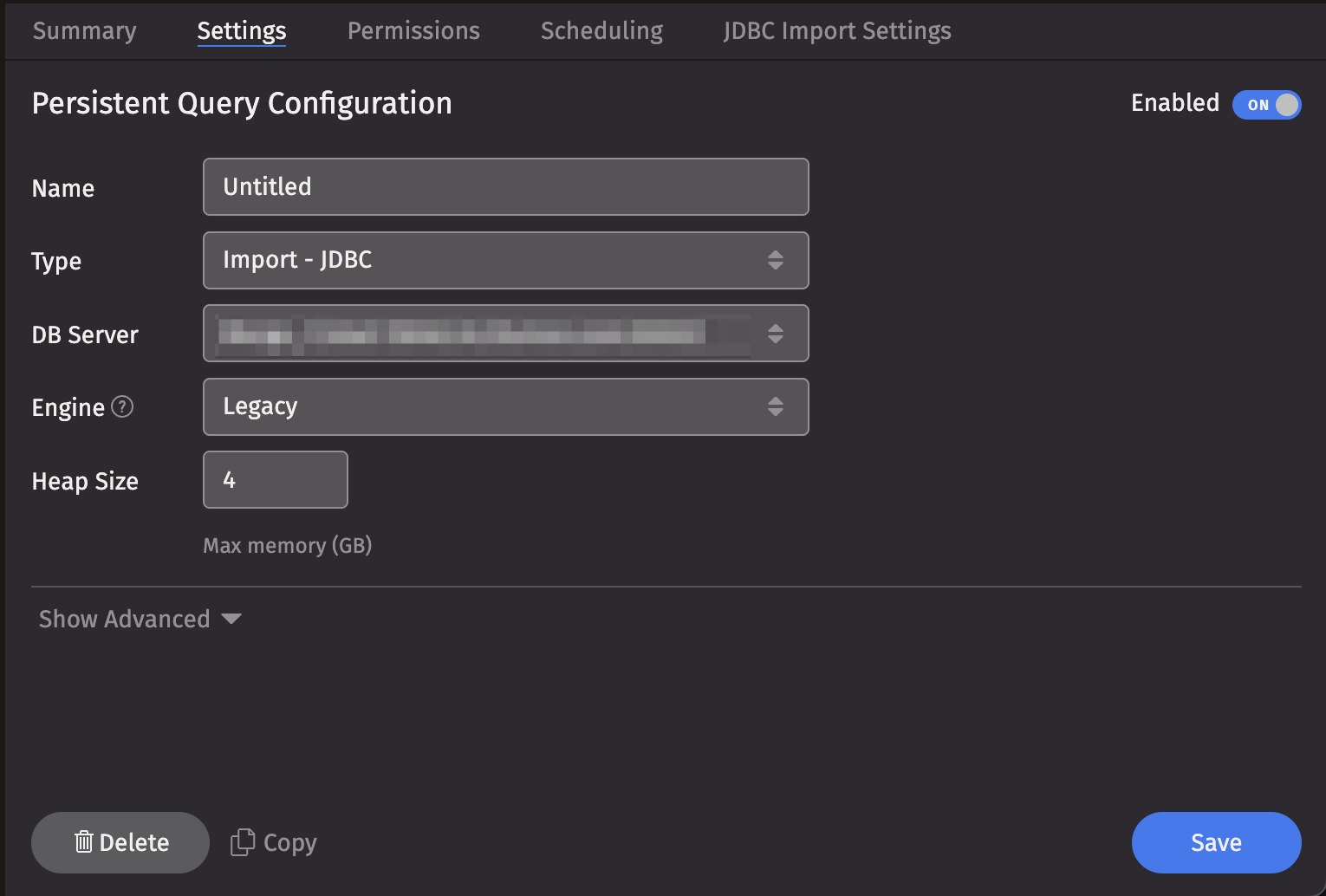
- Select a DB Server , choose an Engine (Core+ or Legacy), and enter the desired value for Memory (Heap) Usage (GB).
- Options available in the Show Advanced Options section of the panel are typically not used when importing or merging data.
- The Permissions tab presents a panel with the same options as all other configuration types, and gives the query owner the ability to authorize Admin and Viewer Groups for this query.
- Clicking the Scheduling tab presents a panel with the same scheduling options as all other configuration types.
- Clicking the JDBC Import Settings tab presents a panel with the options pertaining to importing from JDBC:
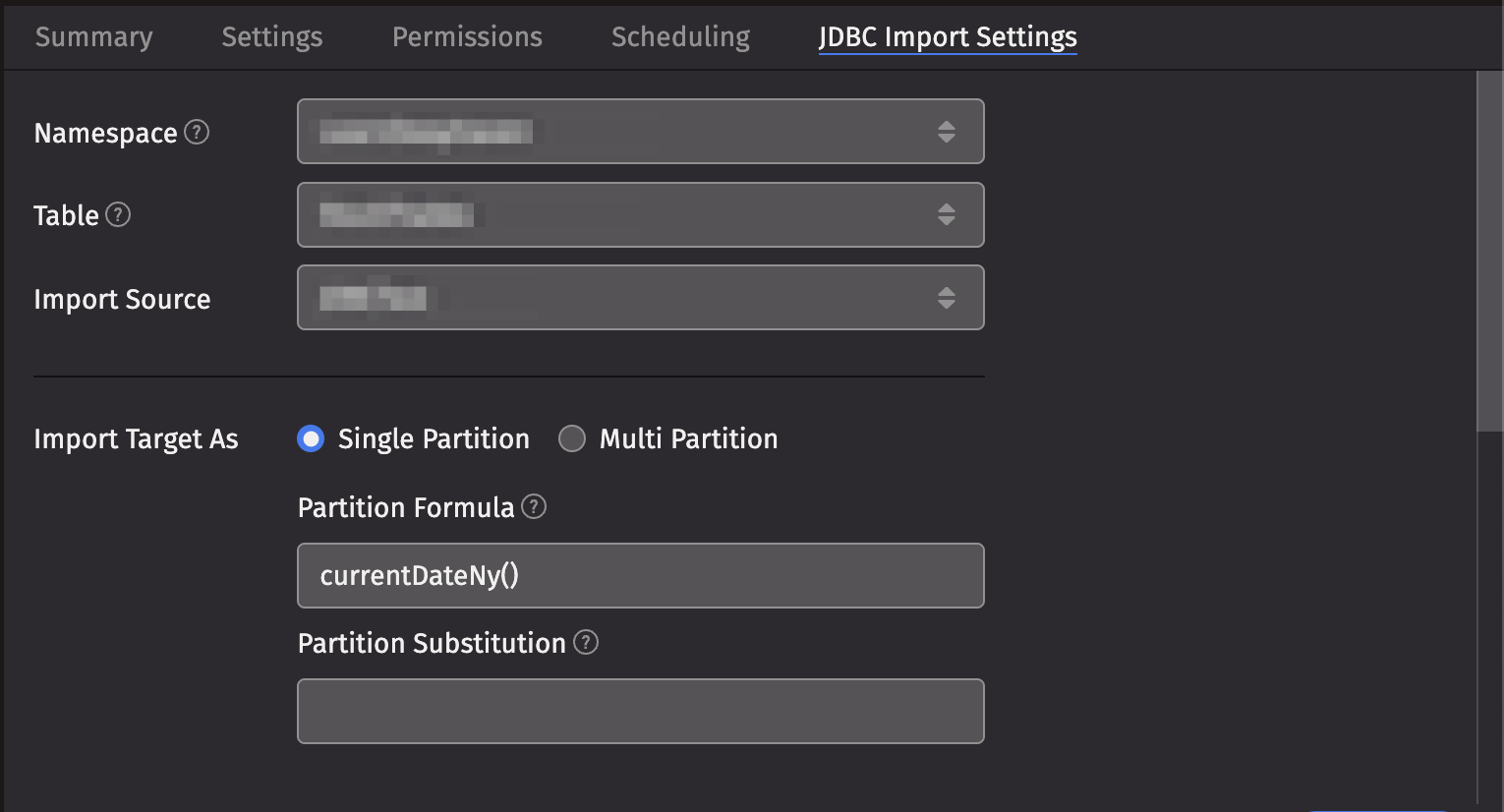
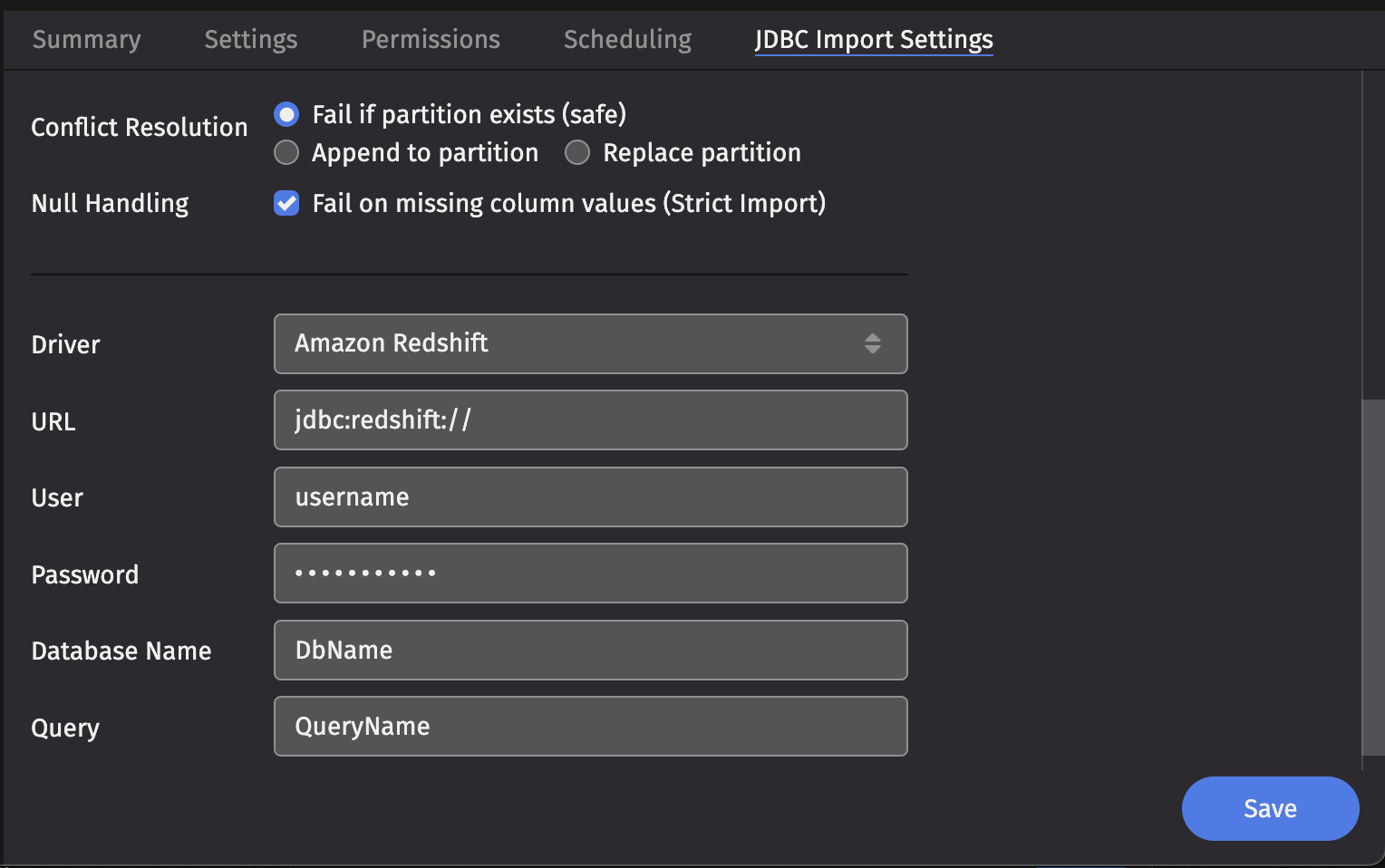
JDBC Import Settings
- Namespace: This is the namespace into which you want to import the file.
- Table: This is the table into which you want to import the data.
- Import Source: This is the import source section of the associated schema file that specifies how source data columns will be set as Deephaven columns.
- Strict Import will fail if a file being imported has missing column values (nulls), unless those columns allow or replace the null values using a default attribute in the
ImportColumndefinition.
- Strict Import will fail if a file being imported has missing column values (nulls), unless those columns allow or replace the null values using a default attribute in the
- Output Mode: This determines what happens if data is found in the fully-specified partition for the data. The fully-specified partition includes both the internal partition (unique for the import job) and the column partition (usually the date).
Safe- The import job will fail if existing data is found in the fully-specified partition.Append- Data will be appended to the partition if existing data is found in the fully-specified partition.Replace- Data will be replaced if existing data is found in the fully-specified partition. This does not replace all data for a column partition value, just the data in the fully-specified partition.
- Single/Multi Partition: This controls the import mode. In
single-partition, all of the data is imported into a single intraday partition. Inmulti-partitionmode, you must specify a column in the source data that will control to which partition each row is imported.- Single-partition configuration:
- Partition Formula: This is the formula needed to partition the JDBC file being imported. If a specific partition value is used, it will need to be surrounded by quotes. For example:
currentDateNy()"2017-01-01" - Partition Substitution: This is a token used to substitute the determined column partition value in the source directory, source file, or source glob, to allow the dynamic determination of these fields. For example, if the partition substitution is
PARTITION_SUB, and the source directory includesPARTITION_SUBin its value, thatPARTITION_SUBwill be replaced with the partition value determined from the partition formula. - Substitution Date Format: This is the date format that will be used when a Partition Substitution is used. The standard Deephaven date partition format is
yyyy-MM-dd(e.g., 2018-05-30), but this allows substitution in another format. For example, if the filename includes the date inyyyyddMMformat instead (e.g., 20183005), that could be used in the Date Substitution Format field. All the patterns from the JavaDateTimeFormatterclass are allowed.
- Partition Formula: This is the formula needed to partition the JDBC file being imported. If a specific partition value is used, it will need to be surrounded by quotes. For example:
- Multi-partition configuration:
- Import Partition Column: This is the name of the database column used to choose the target partition for each row (typically
Date). There must be a correspondingImport Columnpresent in the schema, which will indicate how to get this value from the source data.
- Import Partition Column: This is the name of the database column used to choose the target partition for each row (typically
- Single-partition configuration:
- Driver: This is the name of the driver needed to access the database. It defaults to
Mysql. - URL: This the URL for the JDBC connection.
- Query: This is the query detailing what data you want to pull from the database.
Warning
After completing a JDBC Import Query, you must run a rescan command for the imported data to become available in Deephaven. The Data Import Server (DIS) will not automatically detect the new data.
Run this command to rescan a specific table:
See the Data control tool rescan documentation for more details.